


FCOS代码解读
论文解读:https://zhuanlan.zhihu.com/p/63868458
源码解读:
一:https://zhuanlan.zhihu.com/p/112126473

入门mmdetection(柒)---FCOS源码解读
前面六篇文章借助sq的经典之作(Faster R-CNN)熟悉了mmdetection整个的设计风格和训练流程,这篇笔记想分享一下FCOS在mmdetection中的源码实现。
FCOS大概是去年这个时候出来的文章,一出来就注定要引领新的潮流,单阶段网络逐渐成为学术界和工业界的新宠。但其实FCOS本质思想,一方面几年前Densebox就已经有类似的了,另一方面,无非是框的anchor变成了点的anchor,并不能说是真正的anchor-free,还是没有跳脱滑窗匹配的命运。整体而言,FCOS出来了还是很惊艳了我,对回归目标的编码方式、centerness的提出解决大框偏离问题以及利用FPN缓解歧义的场景(如人的手上拿了个网球)。来开始欣赏代码吧:
# FCOS类继承了单阶段检测器类SingleStageDetector
class FCOS(SingleStageDetector):
def __init__(self,backbone,neck,bbox_head,
train_cfg=None,test_cfg=None,pretrained=None):
super(FCOS, self).__init__(backbone, neck, bbox_head, train_cfg,
test_cfg, pretrained)FCOS类继承了单阶段检测器类,这个和之前Faster R-CNN继承了双阶段检测器一样,实现都在对应的父类里面,所以我们截取部分重要的单阶段的代码块来看。
class SingleStageDetector(BaseDetector):
def __init__(self,backbone,neck=None,bbox_head=None,
train_cfg=None,test_cfg=None,pretrained=None):
super(SingleStageDetector, self).__init__()
# 这里下面的build和之前介绍的一样,从config读取对应的type,然后返回一个实例
self.backbone = builder.build_backbone(backbone)
if neck is not None:
self.neck = builder.build_neck(neck)
# 这里self.bbox_head就是一个FCOSHead的实例
self.bbox_head = builder.build_head(bbox_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
self.init_weights(pretrained=pretrained)所以初始化函数就是创建backbone,neck以及head的实例,其中和Faster R-CNN不一样的只有head使用的是FCOSHead。可以想象,这个FCOSHead类里面必然实现了一个前向,就是下图橘色框起来那个三个分支的图(分别是分类H * W *C, 回归 H * W* 4 以及 centerness H * W * 1),以及计算target和loss的代码。先继续看SingleStageDetector的实现:
# 训练的前向函数forward_train,在BaseDetector的成员函数forward()里会调用,
# 上一章讲过,forward()会在batch_processor调用,在训练流程控制里
# 传进来的参数都是data_loader的输出,这个以后有机会再看,总之能拿到数据集的图片和标签
def forward_train(self,img,img_metas,gt_bboxes,gt_labels,gt_bboxes_ignore=None):
x = self.extract_feat(img) #通过backbone和FPN提取多尺度的特征
outs = self.bbox_head(x) #即FCOSHead的实例调用成员函数forward
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas, self.train_cfg)
losses = self.bbox_head.loss( # 计算loss
*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
return losses前向的代码封装的非常清晰,那么重点就是在FCOSHead里面了,我们来看这个类。
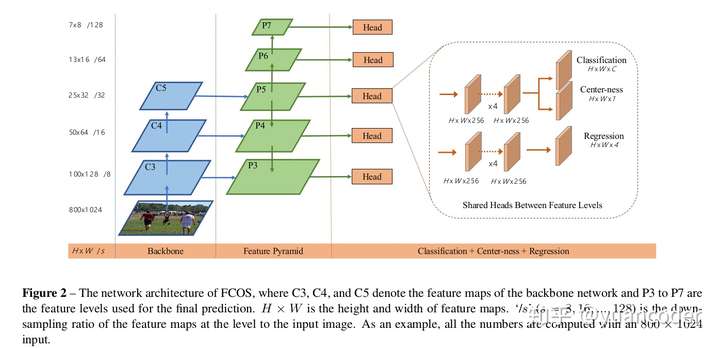
#首先初始化fcos头部网络结构,其实就是上图框框里的部分,
#两个分支,分别都有4个卷积,上面分叉为分类和centerness,下面接回归(当然,也可以把centerness和回归接在一起)
def _init_layers(self):
self.cls_convs = nn.ModuleList()
self.reg_convs = nn.ModuleList()
for i in range(self.stacked_convs):
chn = self.in_channels if i == 0 else self.feat_channels
#stacked_convs=4, 即接4个3*3的卷积,channel为256
self.cls_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
bias=self.norm_cfg is None))
self.reg_convs.append(
ConvModule(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
bias=self.norm_cfg is None))
# 分类的channel数需要注意一下,因为后面用的focal loss,所以为类别数-1
# 即对coco数据集就不是81而是80
# 本质上来说focal_loss调用的是BCE,并不引入类间竞争
self.fcos_cls = nn.Conv2d(
self.feat_channels, self.cls_out_channels, 3, padding=1)
# 回归,输出channel为4,也和faster RCNN不一样,anchorbox有多个,anchor点只有一个
# 譬如假如有9种anchor box,那么Faster R-CNN这边应该是36,而fcos只有4,减少了计算量
self.fcos_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1)
# 预测centerness,channel为1
# centerness预测了当前anchor点的中心程度,推理的时候可以给框打分
# 不在中心的框乘了centerness之后得分就降低了,容易被NMS过滤掉
self.fcos_centerness = nn.Conv2d(self.feat_channels, 1, 3, padding=1)
self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])
# 初始化了网络结构和权重之后就可以前向了,来看forward函数
def forward(self, feats):
# 传进来的feats就是通过backbone和FPN提取多尺度的特征(一般是一个长度为5的tuple)
# 注意这边用map把FPN的多个level给拆解了,可以简单理解为并行计算了
return multi_apply(self.forward_single,