

让我们来欣赏一下同事写的Robotframework脚本,高效定位的黄金法则
目录
核心理念:优先使用稳定、唯一的属性,而非易变的、依赖于位置或样式的属性。
同事离职交接后,运行的自动化脚本报错了,当我去定位的时候看到这段代码感觉天都塌了,这一坨我写成这样根本不知道该怎么看,属于防御性编程了,一整个头皮发麻。
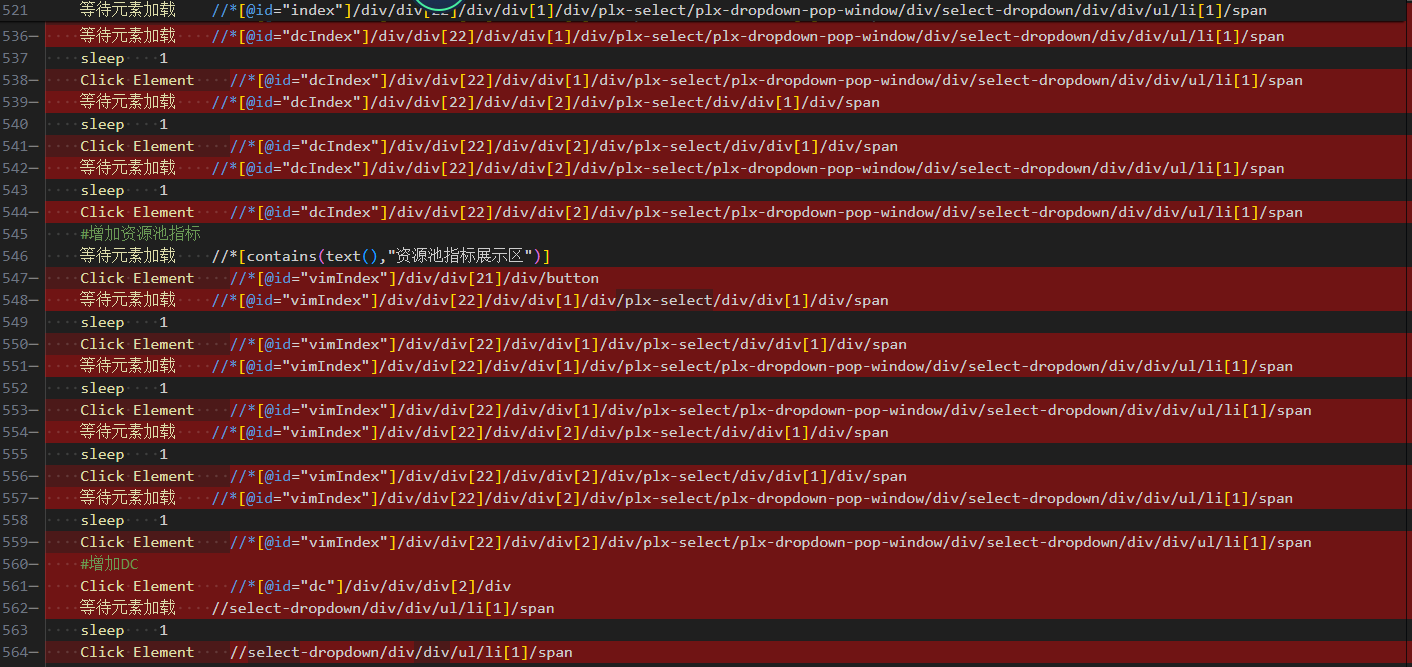
图片中这种定位方式的缺点就是当整个页面改动一处,那么这个整个脚本元素都要跟着修改,稳定性可维护性可读性非常差,别人根本无从下手,另外就是没有做到封装,一个小的步骤可以做一个封装,作为一个关键字这样用例可读性会更好。
核心理念:优先使用稳定、唯一的属性,而非易变的、依赖于位置或样式的属性。
一、 基础定位策略(由优到劣排序)
在Selenium WebDriver等工具中,定位器优先级通常如下:
-
ID定位器
-
方法:
By.id("elementId") -
优点: ID在HTML中应该是唯一的,定位速度最快,最稳定。
-
前提: 开发人员为元素赋予了唯一且固定的ID。
-
最佳实践: 首选方法。如果存在唯一ID,毫不犹豫地使用它。
-
-
Name定位器
-
方法:
By.name("elementName") -
优点: 对于表单元素(如input, select)比较常见,也相对稳定。
-
注意: Name属性不一定唯一,页面上可能有多个元素拥有相同的name。
-
-
Link Text / Partial Link Text
-
方法:
By.linkText("完整的链接文字")/By.partialLinkText("部分链接文字") -
优点: 专门用于定位超链接(
<a>标签),非常直观。 -
适用场景: 导航菜单、文本链接等。
-
-
CSS Selector
-
方法:
By.cssSelector("div.content > input.username") -
优点:
-
功能强大: 语法非常灵活,可以通过元素关系(父子、兄弟)、属性、状态等进行组合定位。
-
性能优异: 在现代浏览器中解析速度很快。
-
-
常用语法:
-
#id: 根据ID,等同于By.id -
.class: 根据class -
[attribute=value]: 根据属性,如[type='submit'] -
父元素 > 子元素: 直接子元素 -
元素1 元素2: 后代元素 -
元素1 + 元素2: 相邻兄弟元素
-
-
-
XPath
-
方法:
By.xpath("//div[@id='container']//input[@placeholder='请输入']") -
优点:
-
功能最强大: 可以遍历整个DOM树,支持轴(axis)定位(如父级、祖先、 preceding-sibling等),灵活性无与伦比。
-
可以文本定位: 可以使用
text()函数,如//button[text()='登录']。
-
-
缺点:
-
性能相对较差: 复杂的XPath表达式遍历整个DOM,可能比CSS Selector慢。
-
易写难精: 编写绝对路径或过于复杂的XPath会导致极度脆弱(brittle)。
-
-
二、 高级策略与最佳实践(提升稳定性的关键)
单纯会用定位器还不够,如何用得“好”才是关键。
-
使用相对路径和最小化定位范围
-
避免: 长的、绝对的XPath,如
/html/body/div[3]/div[2]/div/div[1]/form/input[1]。页面结构稍有变动就会失效。 -
推荐: 使用相对路径,并借助靠近目标元素的稳定父容器来缩小范围。
-
示例: 假设有一个稳定的父容器
id="login-form",可以这样写:-
CSS:
#login-form input.username -
XPath:
//form[@id='login-form']//input[@name='username']
-
-
-
-
使用多个属性进行组合定位
当一个属性不够唯一时,可以组合多个属性。-
CSS:
input.form-control[type='email'][placeholder='用户邮箱'] -
XPath:
//input[@class='form-control' and @type='email']
-
-
处理动态元素(Dynamic Elements)
-
问题: 元素的ID、Class可能是由前端框架(如React, Vue)动态生成的,每次加载都变化。
-
解决方案:
-
使用其他稳定属性: 寻找
name,data-*属性(如data-testid),或文本内容。 -
使用包含(contains)匹配: 如果ID的一部分是固定的。
-
CSS:
[id*='stable-part'](包含) -
XPath:
//div[contains(@id, 'stable-part')]
-
-
使用起始(starts-with)或结束(ends-with)匹配:
-
XPath:
//div[starts-with(@id, 'prefix-')]
-
-
-
-
利用“数据”属性(
data-*)-
与开发和产品团队约定,为重要的可交互元素添加专门的、用于测试的属性,如
data-testid="login-submit-btn"。 -
优点:
-
唯一目的: 专为测试而生,不会因为UI样式或业务逻辑变更而改变。
-
语义清晰: 一看就知道这个元素的测试用途。
-
-
定位:
By.cssSelector("[data-testid='login-submit-btn']")。这是最推荐的合作模式。
-
-
显式等待(Explicit Waits) - 最重要的实践!
-
问题: 元素可能因为网络、JS加载慢等原因尚未出现在DOM中或不可交互,直接定位会抛出
NoSuchElementException。 -
解决方案: 使用显式等待,让WebDriver等待某个条件成立后再进行操作。
-
方法: 使用
WebDriverWait结合expected_conditions。 -
示例(Python):
python
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By # 等待最多10秒,直到元素可被点击 element = WebDriverWait(driver, 10).until( EC.element_to_be_clickable((By.ID, "myDynamicButton")) ) element.click() -
常用条件:
presence_of_element_located,visibility_of_element_located,element_to_be_clickable。使用显式等待替代硬编码的time.sleep(),这是高效和稳定的基石。
-
-
使用Page Object Model(POM)设计模式
-
思想: 将页面的元素定位和操作封装在一个单独的类中。
-
优点:
-
可维护性: 如果UI元素发生变化,只需修改Page Object类中的一个地方。
-
可读性: 测试用例看起来更像业务逻辑,而不是一堆技术性的定位代码。
-
复用性: 多个测试用例可以复用同一个Page Object。
-
-
三、 工具辅助
-
浏览器开发者工具:
-
检查(Inspect): 右键点击元素,选择“检查”,查看其HTML结构。
-
Console: 使用
$$("css selector")测试CSS选择器,使用$x("xpath")测试XPath,看是否能正确返回元素。
-
-
浏览器插件:
-
Chrome的SelectorsHub: 非常强大的插件,可以自动生成、验证、评估多种定位器(ID, CSS, XPath),并给出推荐。
-
总结:高效定位的黄金法则
-
优先级:
ID>Name>CSS Selector>XPath> 其他。 -
稳定性第一: 使用显式等待,避免绝对路径,优先选择
data-*属性。 -
简洁明了: 定位表达式应尽可能短且具有描述性。
-
设计模式: 采用 Page Object Model 来管理定位器,与测试逻辑分离。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号