【python爬虫】动态图片爬取
爬取网站上的动态图片
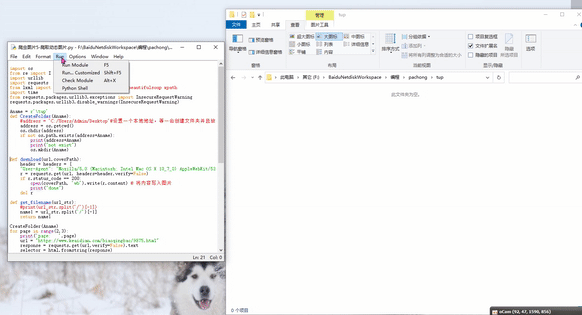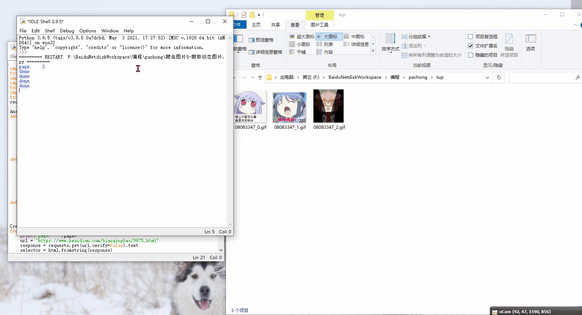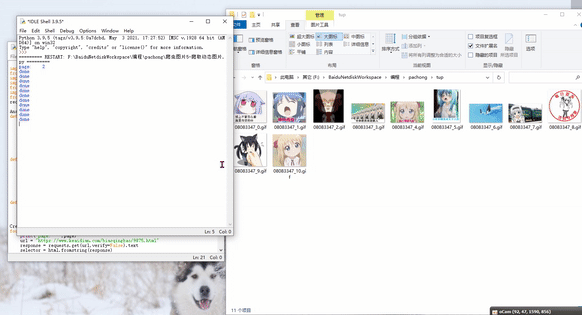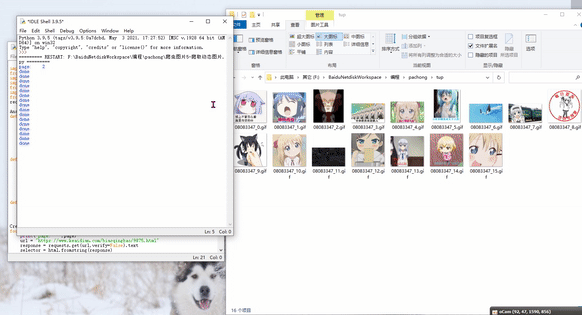
代码
import os
from re import I
import urllib
import requests
from lxml import html #定位用的lxml 还有其他如beautifulsoup xpath
import time
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
Aname = r'\tup'
def CreateFolder(Aname):
#address = 'C:/Users/Admin/Desktop'#设置一个本地地址,等一会创建文件夹并且放入
address = os.getcwd()
os.chdir(address)
if not os.path.exists(address+Aname):
print(address+Aname)
print("not exist")
os.mkdir(Aname)
def download(url,coverPath):
header = headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"}
r = requests.get(url, headers=header,verify=False)
if r.status_code == 200:
open(coverPath, 'wb').write(r.content) # 将内容写入图片
print("done")
del r
def get_filename(url_str):
#print(url_str.split('/')[-1])
name1 = url_str.split('/')[-1]
return name1
CreateFolder(Aname)
for page in range(2,3):
print('page: ',page)
url = "https://www.keaidian.com/biaoqingbao/9875.html"
response = requests.get(url,verify=False).text
selector = html.fromstring(response)
imgEle2 = selector.xpath('//li[@class="tx-img"]/a[1]')
label = 'tu%s'%page
#print(imgEle)#得到的元素
for index,i in enumerate(imgEle2):
#print(index,i)#i还不是url链接 是一个个a标签
imgUrl = i.xpath('@href')[0]#连接已得到
imgUrl = "https://www.keaidian.com"+imgUrl
#print(str)
imgName = get_filename(imgUrl)
#imgName = '%s_%s.jpg'%(label,index)
coverPath = '%s\%s\%s'%(os.getcwd(),Aname,imgName)
#print(coverPath)
download(imgUrl,coverPath)
#urllib.request.urlretrieve(imgUrl,coverPath)
#time.sleep(2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号