
第四次作业 猫狗大战
一、使用VGG模型进行猫狗大战
1、下载数据


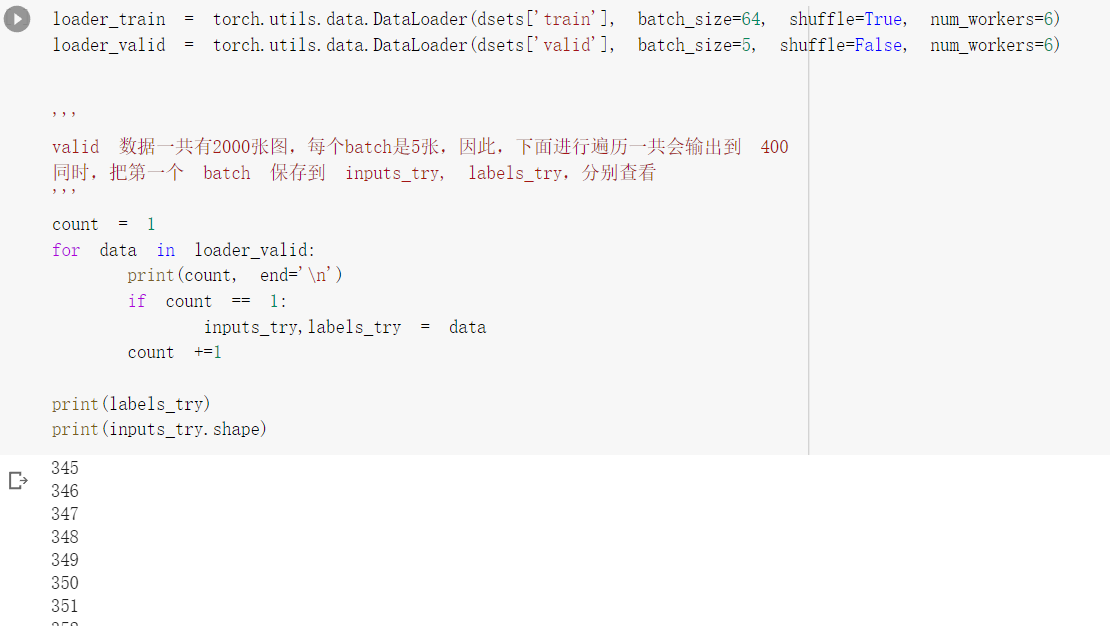
2、数据处理



3、创建VGG模型
4、修改最后一层,冻结前面层的参数
print(model_vgg) model_vgg_new = model_vgg; for param in model_vgg_new.parameters(): param.requires_grad = False model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2) model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1) model_vgg_new = model_vgg_new.to(device) print(model_vgg_new.classifier)

5. 训练并测试全连接层
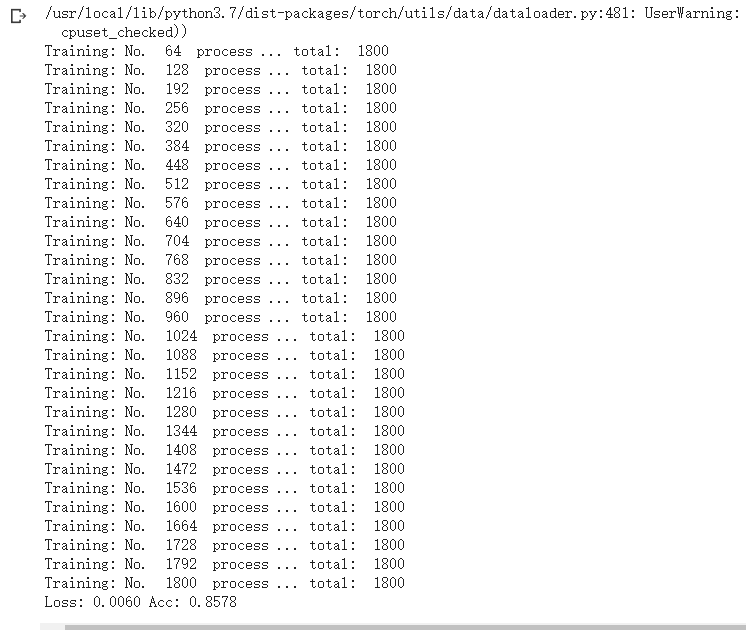
criterion = nn.NLLLoss() # 学习率 lr = 0.001 # 随机梯度下降 optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr) ''' 第二步:训练模型 ''' def train_model(model,dataloader,size,epochs=1,optimizer=None): model.train() for epoch in range(epochs): running_loss = 0.0 running_corrects = 0 count = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) optimizer = optimizer optimizer.zero_grad() loss.backward() optimizer.step() _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) count += len(inputs) print('Training: No. ', count, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format( epoch_loss, epoch_acc)) # 模型训练 train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1, optimizer=optimizer_vgg)
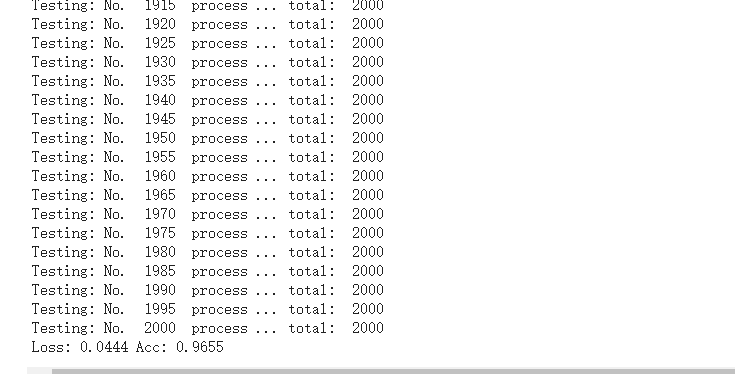
def test_model(model,dataloader,size): model.eval() predictions = np.zeros(size) all_classes = np.zeros(size) all_proba = np.zeros((size,2)) i = 0 running_loss = 0.0 running_corrects = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) predictions[i:i+len(classes)] = preds.to('cpu').numpy() all_classes[i:i+len(classes)] = classes.to('cpu').numpy() all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy() i += len(classes) print('Testing: No. ', i, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format( epoch_loss, epoch_acc)) return predictions, all_proba, all_classes predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])
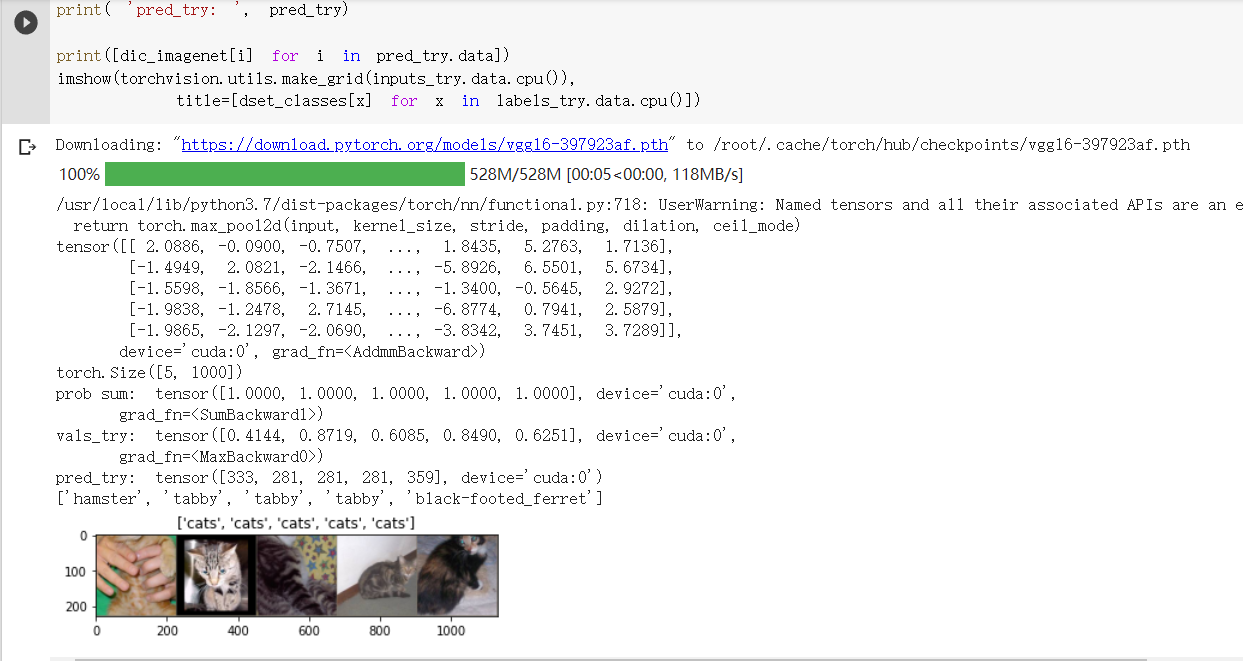
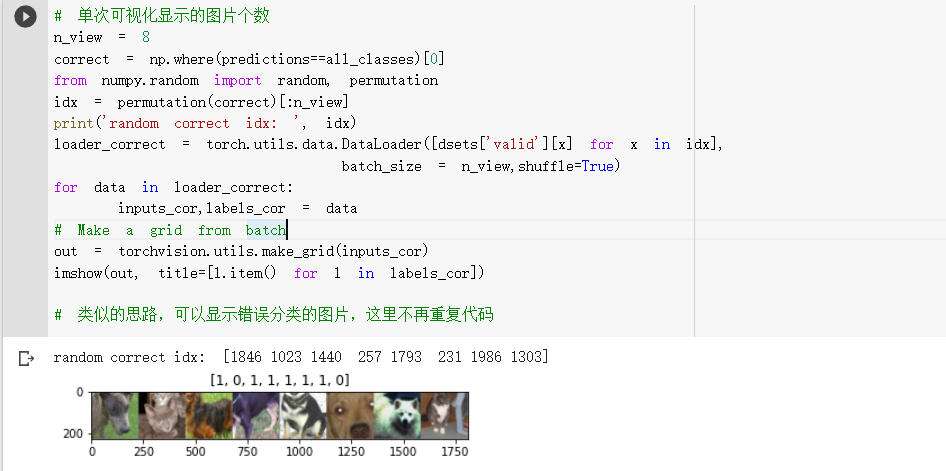
6. 可视化模型预测结果
二、利用fine-tune的VGG模型进行测试


 浙公网安备 33010602011771号
浙公网安备 33010602011771号