
C系列输入输出介绍
C
笔试输入输出
/* (1) 类型混排
* push 123
* pop
* front
*/
scanf("%s %d", &str, &x);
// %s 是以空白符为界定的,因此不用担心会读取一行
/* (2) 读取一行
*/
scanf("%[^\n]", &line); // scanf 可以进行简单的模式匹配
getline(&line, &size, stdin); // posix 的函数,可以自动分配大小
fgets(line, size, stdin); // 读取指定数目或一行
printf
-
打印颜色
颜色控制码-cnblogs// 一般格式为 printf("\033[控制码1;控制码2;控制码3...m %s \033[控制码m\n", str); // 例如下面将输出一个黄色的str printf("\033[32m %s \033[0m \n", str);


-
打印数据类型
维基百科-printf-format 参考-runoob.com
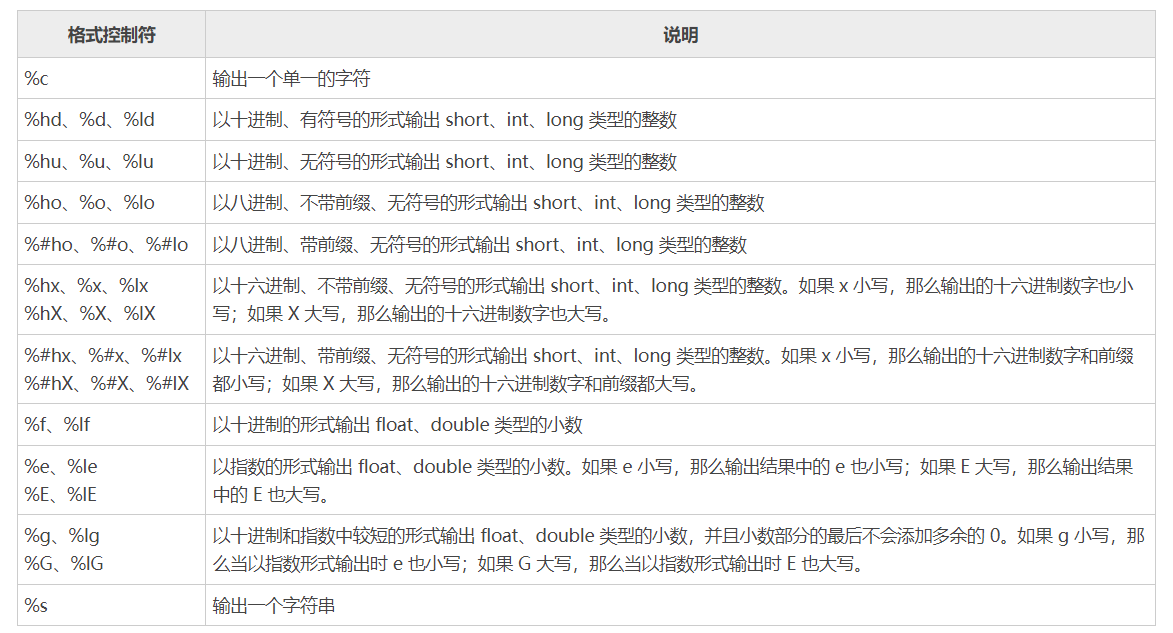
a A:以十六进制形式输出浮点数(C99)z:输出size_t类型的推荐做法
-
位宽限定符:
%[width]d:限定整数的最小位宽,可以用数字替代[width],如%5d表示整数占 5 位宽度。%[width].[precision]f:限定浮点数的位宽和小数点后的位数,可以用数字替代[width]和[precision],如%8.2f表示浮点数占 8 位宽度,小数点后保留 2 位。%[width]s:限定字符串的最小位宽,可以用数字替代[width],如%10s表示字符串占 10 位宽度。
-
填充限定符:
%-[width]d:左对齐限定整数的最小位宽,可以用数字替代[width],如%-5d表示整数左对齐并占 5 位宽度。%0[width]d:用零填充限定整数的最小位宽,可以用数字替代[width],如%04d表示整数用零填充并占 4 位宽度。
-
变参限定符:
%*c:动态指定字符的宽度,可以通过传递参数给printf()函数来指定字符的宽度,如printf("%*c", 5, '*')表示打印一个宽度为 5 的字符*。%.*s:动态指定字符串的宽度,可以通过传递参数给printf()函数来指定字符串的宽度,如printf("%.*s", 8, "Hello, World!")表示打印字符串的前 8 个字符。
-
其他特殊格式化方法:
%n:将已经打印的字符数保存到对应的int变量中,例如printf("Hello, %s%n", "World!", &count),count将保存字符串 "Hello, World!" 的字符数。%m:输出上一个发生的错误消息(通常与错误处理相关)。%p:打印指针的地址。
sprintf & vsprintf
二者都能格式化输出到字符串,区别在于,v系列能“定制”,你可以将其封装到你的函数中去,以应对参数不确定的情况。
#include <stdio.h>
int printf(const char *format, ...); // 到标准输出
int fprintf(FILE *stream, const char *format, ...); // 到文件
int dprintf(int fd, const char *format, ...); // 到文件
int sprintf(char *str, const char *format, ...); // 到字符串
int snprintf(char *str, size_t size, const char *format, ...); // 到字符串
#include <stdarg.h>
int vprintf(const char *format, va_list ap); // 也到标准输出
int vfprintf(FILE *stream, const char *format, va_list ap); // 也到文件
int vdprintf(int fd, const char *format, va_list ap); // 也到文件
int vsprintf(char *str, const char *format, va_list ap); // 也到字符串
int vsnprintf(char *str, size_t size, const char *format, va_list ap); // 也到字符串
C 库字符串处理函数
(1)输入输出:
//(1) <stdio.h>:
// 成功返回 s,失败返回 NULL;会把换行符读进 s 里面(做字符串比较的时候要注意)
char *fgets( char *s, int size, FILE *stream);
// 成功返回 nonnegative number,失败返回 EOF;不会输出 '\0',但会输出 '\n'到 stream 里面
int fputs(const char *s, FILE *stream);
//会读取换行符进入目标; 当 lineptr 已经被 malloc,但是不够大,则会自动 relloc;当目标为空指针,且 n 为 0 的时候会自动 malloc;无论getline成功与否,都要由用户来负责 free 这块内存
ssize_t getline (char **lineptr, size_t *n, FILE *stream);
ssize_t getdelim(char **lineptr, size_t *n, int delim, FILE *stream);
(2)处理:
// (1)查找
// 返回指向首次出现needle的指针。如strstr("hello", "ll");则返回指向第一个l的指针
char *strstr (const char *str, const char *needle);
// 返回指向首次出现字符c位置的指针
char *strchr (const char *str, int c);
// 查找 str 中,第一个不在 accept 列表中的字符位置
char *strpbrk(const char *str, const char *accept);
// 查找 str 中,开头出现 accept 中字符的个数。如str=“ABABCDE”,accept=“ABD”,则返回 4
size_t strspn (const char *s, const char *accept);
// 查找 str 中,开头 不 出现 reject 中字符的个数
size_t strcspn(const char *s, const char *reject);
// (2)比较字符串,相等返回 0
int strcmp (const char *s1, const char *s2); // 比较
int strncmp (const char *s1, const char *s2, size_t n); // 比较前 n 个字符
int strcasecmp (const char *s1, const char *s2); // 比较,但不区分大小写
int strncasecmp(const char *s1, const char *s2, size_t n); // 比较前 n 个字符且不区分大小写
// (3)以 delim 为分隔符,分割 str (一般要用到循环,即while(token != NULL) )
// 第一次调用要指明 str; 后面的每一次想分割同一个字符串的调用,都要把 str 置为 NULL
// 返回值是分割得到的子串,剩余部分是保存在内核(?)中,因此后续调用不再传递 str
char *strtok(char *str, const char *delim);
(3)格式转换:
// 字符串转为别的数据类型
#include <stdlib.h>
double atof (const char *nptr);
int atoi (const char *nptr);
long atol (const char *nptr);
long long atoll(const char *nptr);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号