
hadoo3.1.2环境搭建
实验使用3节点的hadoop平台,一个master和两个salve,同时master也作为工作节点。
集群信息如下
192.168.1.10 master (namenode,datanode)
192.168.1.20 slave-1 (datanode)
192.168.1.30 slave-2 (datanode)
实验开始
1. 网络配置(全部节点都要配置,并且以root用户执行命令)
1.1编辑/etc/hosts文件,输入每个节点的ip地址和主机名的映射。
192.168.1.10 master
192.168.1.20 slave-1
192.168.1.30 slave-2保存退出
1.2关闭防火墙和selinux
systemctl stop firewalld(关闭防火墙)
setenforce 0(关闭selinux)
vi /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted1.3 添加hadoop用户
useradd hadoop
passwd hadoop(密码自定义)
2.密钥登录
2.1 安装依赖包
yum install openssh* -y
yum install rsync -y
2.2 在master节点创建密钥对
su - hadoop
ssh-keygen -t rsa -P ''(生成密钥对)
ssh-copy-id master(复制公钥到对应主机,实现免密登录)
ssh-copy-id slave-1(复制公钥到对应主机,实现免密登录)
ssh-copy-id slave-2(复制公钥到对应主机,实现免密登录)
2.3 在两个slave节点创建密钥对
su - hadoop
ssh-keygen -t rsa -P ''(生成密钥对)
ssh-copy-id master(复制公钥到对应主机,实现免密登录)
ssh-copy-id localhost(复制公钥到对应主机,实现免密登录)
3. java环境安装
下载8版本的java包进行解压安装,配置环境变量
vi /etc/profile
# set java environment
export JAVA_HOME=/usr/java/jdk1.8.0_77 (所有路径根据实际情况而定)
export JRE_HOME=/usr/java/jdk1.8.0_77/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/binsource /etc/profile
4. hadoop集群配置(本例子采用hadoop3.1.2,且在master主机执行)
4.1 在hadoop官网下载对应的hadoop3.1.2版本
下载地址: https://hadoop.apache.org/release/3.1.2.html
4.2 解压安装并修改目录名称
将下载下来的压缩包进行解压到指定的路径
tar -xzvf hadoop-3.1.2.tar.gz -C /usr/
mv hadoop-3.1.2 hadoop
4.3 添加hadoop环境变量
vi /etc/profile
添加以下内容
# set hadoop environment
export HADOOP_HOME=/usr/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH4.4 编辑hadoop配置文件
4.4.1 修改JAVA_HOME变量
vi /usr/hadoop/etc/hadoop/hadoop-env.sh
找到带有export JAVA_HOME的行
添加或修改为以下内容,路径是java的安装路径
export JAVA_HOME=/usr/java/jdk1.8.0_144
4.4.2 配置 core-site.xml
vi /usr/hadoop/etc/hadoop/core-site.xml
配置放在<configuration></configuration>之间
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
</property>
4.4.3 配置 hdfs-site.xml文件
vi /usr/hadoop/etc/hadoop/hdfs-site.xml
配置放在<configuration></configuration>之间
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
4.4.4 配置 yarn-site.xml文件
vi /usr/hadoop/etc/hadoop/yarn-site.xml
配置放在<configuration></configuration>之间
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
4.4.5 配置mapred-site.xml文件
先查看有没有/usr/hadoop/etc/hadoop/mapred-site.xml文件没有则执行以下复制操作,有则跳过复制操作
cp mapred-site.xml.template mapred-site.xml(复制操作)
vi /usr/hadoop/etc/hadoop/mapred-site.xml
配置放在<configuration></configuration>之间
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
4.4.6 配置集群的节点功能
vi masters
删除所有内容,添加以下内容
mastervi workers
删除所有内容,添加以下内容
master
slave-1
slave-2
4.4.7 创建数据目录并修改目录属主
mkdir /usr/hadoop/tmp
mkdir /usr/hadoop/dfs/name -p
mkdir /usr/hadoop/dfs/data -p
chown -R hadoop:hadoop /usr/hadoop/
4.4.8 复制hadoop目录文件到其他节点
scp -r /usr/hadoop/ root@slave-1:/usr/
scp -r /usr/hadoop/ root@slave-2:/usr/
修改每个节点的/usr/hadoop目录属主为hadoop,属组也为hadoop
slave-1节点和slave-2节点执行:chown -R hadoop:hadoop /usr/hadoop/
5. 测试(master节点执行)
5.1 格式化数据目录
su - hadoop
hadoop namenode -format
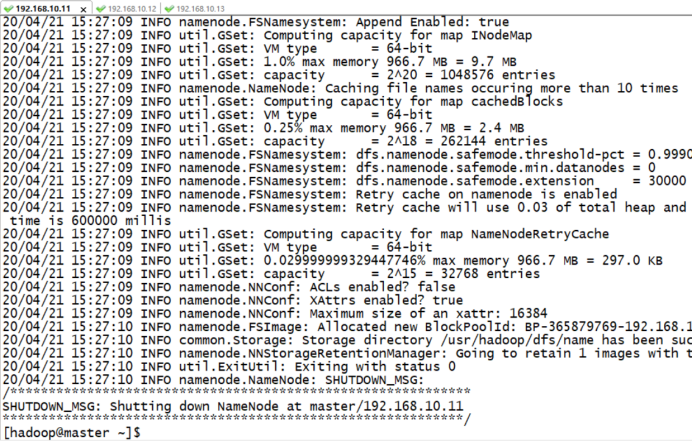
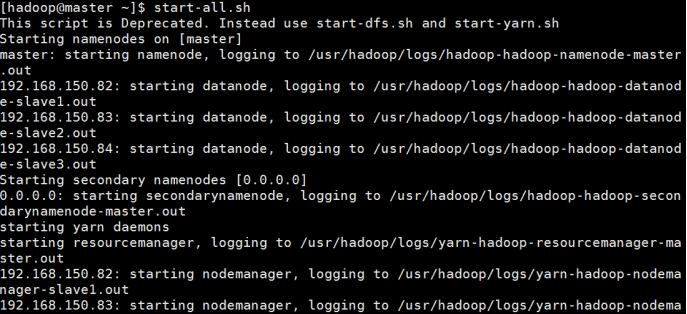
5.2 启动集群
start-all.sh
使用jps查看java进程
master
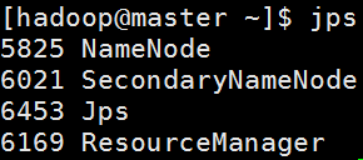 (这里还会有NodeManager和DataNode两个进程)
(这里还会有NodeManager和DataNode两个进程)
slave-1
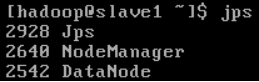
slave-2
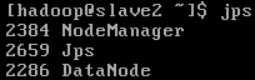
这样集群的部署就基本完成了
还可以通过web访问master的9870端口和8088端口查看集群情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号