
分类算法-3.多分类中的混淆矩阵
加载手写识别数字数据集
import numpy
from sklearn import datasets
import matplotlib.pyplot as plt
digits = datasets.load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.8,random_state=666)
用逻辑回归训练
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
# sklearn中默认使用OVR方式解决多分类问题
log_reg.fit(x_train,y_train)
y_predict = log_reg.predict(x_test)
log_reg.score(x_test,y_test)
查看多分类问题的混淆矩阵
from sklearn.metrics import confusion_matrix
cfm = confusion_matrix(y_test,y_predict)

将数据与灰度值对应起来:
# cmap为颜色映射,gray为像素灰度值
plt.matshow(cfm,cmap=plt.cm.gray)
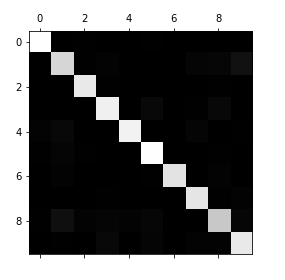
去除预测正确的对角线数据,查看混淆矩阵中的其他值
row_sum = numpy.sum(cfm,axis=1)
err_matrix = cfm / row_sum
numpy.fill_diagonal(err_matrix,0)
plt.matshow(err_matrix,cmap=plt.cm.gray)

上图不仅可以看出哪个地方犯的错误多,还可以看出是什么样的错误,例:算法会偏向于将值为1的数据预测为9,将值为8的数预测为1。
在算法方面,应该考虑调整1、8、9的决策阈值以增强算法的准确率。在手写识别数据集方面,应该考虑处理数据,如消除数据集的噪点和干扰点,提高清晰度和可识别程度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号