
2023数据采集与融合技术实践作业三
心得体会:
作业一:管道设错了,这一步停留了很久~~因为出错的代码包含在try-catch中,而catch方法体内并没有打印错误,这就造成了看起来一切正常,但就是没有输出的假象————
作业二:前一次作业是直接保存为csv文件,这次转成了spider框架+mysql数据库的形式,这让我修改了很久(之间的代码写得很乱、、、)
作业①:
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。 -
文件夹链接:https://gitee.com/showur/crawl_project/tree/master/3/WeatherProject
代码
items.py
class WeatherprojectItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
# title_ = scrapy.Field()
image_url = scrapy.Field()
passxxxxxxxxxx class WeatherprojectItem(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() # title_ = scrapy.Field() image_url = scrapy.Field() passclass ImgSpiderItem(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() # title_ = scrapy.Field() image_url = scrapy.Field() pass
pipelines.py
class wt_spiderPipeline(ImagesPipeline):
# def get_media_requests(self, item, info):
# image_url = item["pic_url"]
# yield scrapy.Request(image_url)
# def process_item(self, item, spider):
# image_url = item["pic_url"]
# # yield scrapy.Request(image_url)
# imageP = ImagesPipeline(images_store)
# # imageP.get_media_requests(item, spider)
# imageP.get_images(item, spider)
# return item
def file_path(self, request, response=None, info=None, *, item=None):
file_name = item['image_url'].split('/')[-1]
print(file_name)
return images_store + '/' + file_name
def get_media_requests(self, item, info):
url = item['image_url']
print(url)
yield scrapy.Request(url)
def item_completed(self, results, item, info):
# for r in results:
# item['image_path'] = r[1]['path']
return item
spider.py
import scrapy
import re
from WeatherProject.items import WeatherprojectItem
class wt_spider(scrapy.Spider):
name = "wt_spider"
start_url = "http://www.weather.com.cn"
total = 0
def start_requests(self):
yield scrapy.Request(self.start_url, callback=self.parse)
# def parse(self, response):
# html = response.text
# urlList = re.findall('<a href="(.*?)" ', html, re.S)
# # print(urlList)
# for url in urlList:
# self.url = url
# try:
# yield scrapy.Request(self.url, callback=self.picParse)
# except Exception as e:
# print("err:", e)
# pass
# def picParse(self, response):
def parse(self, response):
imgList = re.findall(r'<img.*?src="(.*?)"', response.text, re.S)
# print(imgList)
for k in imgList:
# print(self.total)
print(k)
if self.total > 102:
return
item = WeatherprojectItem()
item['image_url'] = k
item['name'] = self.total
self.total += 1
yield item
运行结果
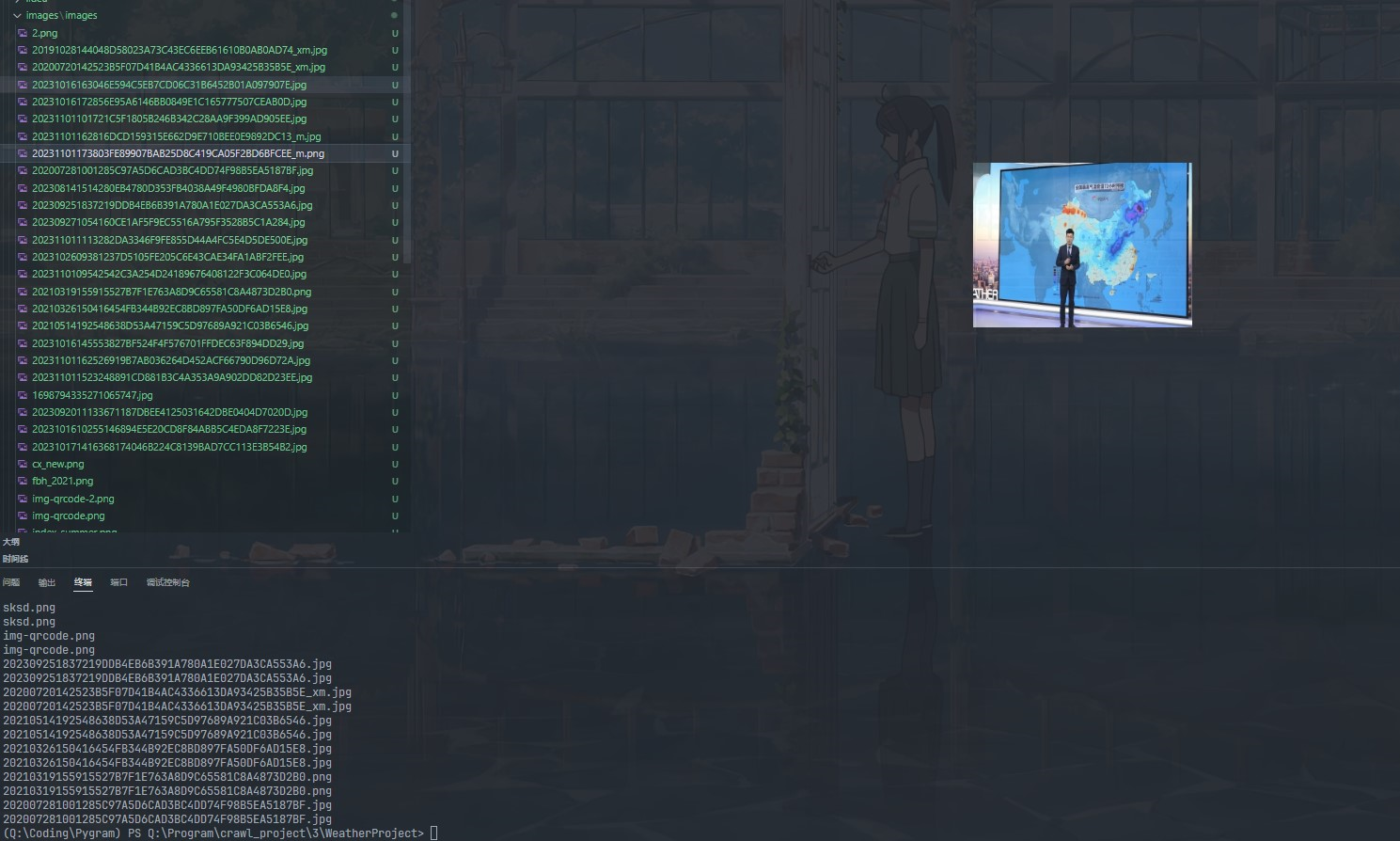
作业②:
-
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/ -
输出信息:
MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStock -
文件夹链接:https://gitee.com/showur/crawl_project/tree/master/3/WeatherProject
代码
items.py
class StockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
new_price = scrapy.Field()
price_limit = scrapy.Field()
change_amount = scrapy.Field()
turnover = scrapy.Field()
volume = scrapy.Field()
rise = scrapy.Field()
highest = scrapy.Field() # 最高
lowest = scrapy.Field() # 最低
today_open = scrapy.Field() # 今开
yesterday_receive = scrapy.Field() # 昨收
pass
pipelines.py
from itemadapter import ItemAdapter
from WeatherProject.settings import IMAGES_STORE as images_store
from scrapy.pipelines.images import ImagesPipeline
import scrapy
import pymysql
class StockSpiderPipeline:
count = 0
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root",passwd = "", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("use zhangh") // 默认使用zhangh.stock作为存储数据的库
self.cursor.execute('''create table if not exists stock
(id int AUTO_INCREMENT PRIMARY KEY,
股票代码 varchar(20),
名称 varchar(20),
最新价 varchar(20),
涨跌幅 varchar(20),
涨跌额 varchar(20),
成交量 varchar(20),
成交额 varchar(20),
振幅 varchar(20),
最高 varchar(20),
最低 varchar(20),
今开 varchar(20),
昨收 varchar(20))''')
self.cursor.execute("delete from stock")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "条股票信息")
def process_item(self, item, spider):
try:
self.count = self.count + 1
print("{:^2}{:>10}{:>10}{:>10}{:>10}{:>12}{:>13}{:>15}{:>12}{:>12}{:>12}{:>12}{:>12}".format(self.count, item['code'], item['name'],
item['new_price'], item['price_limit'],
item['change_amount'],
item['turnover'],
item['volume'], item['rise'],item['highest'],item['lowest'],item['today_open'],item['yesterday_receive']))
if self.opened:
self.cursor.execute("insert into stock (股票代码,名称,最新价,涨跌幅,涨跌额,成交额,成交量,振幅,最高,最低,今开,昨收) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(item['code'], item['name'],item['new_price'], item['price_limit'],item['change_amount'],item['turnover'],item['volume'], item['rise'],item['highest'],item['lowest'],item['today_open'],item['yesterday_receive']))
except Exception as err:
print(err)
return item
spider.py
import scrapy
import json
from WeatherProject.items import StockItem
class stockSpider(scrapy.Spider):
name = 'stockSpider'
page = 1
start_urls = [
'http://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240821834413285744_1602921989373&pn=' + str
(page) + '&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,'
'm:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,'
'f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602921989374']
def parse(self, response):
try:
data = response.body.decode('utf-8')
data = data[41:-2] # 将获取到的json文件字符串去掉前面的jQuery.....一大串东西,截取为标准的json格式,传入处理
responseJson = json.loads(data)
stocks = responseJson.get('data').get('diff')
for stock in stocks:
item = StockItem()
item['code'] = stock.get('f12')
item['name'] = stock.get('f14')
item['new_price'] = stock.get('f2')
item['price_limit'] = stock.get('f3')
item['change_amount'] = stock.get('f4')
item['turnover'] = stock.get('f5')
item['volume'] = stock.get('f6')
item['rise'] = stock.get('f7')
item['highest'] = stock.get('f15')
item['lowest'] = stock.get('f16')
item['today_open'] = stock.get('f17')
item['yesterday_receive'] = stock.get('f18')
yield item
url = response.url.replace("pn=" + str(self.page), "pn=" + str(self.page + 1)) # 实现翻页
self.page = self.page + 1
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
运行结果
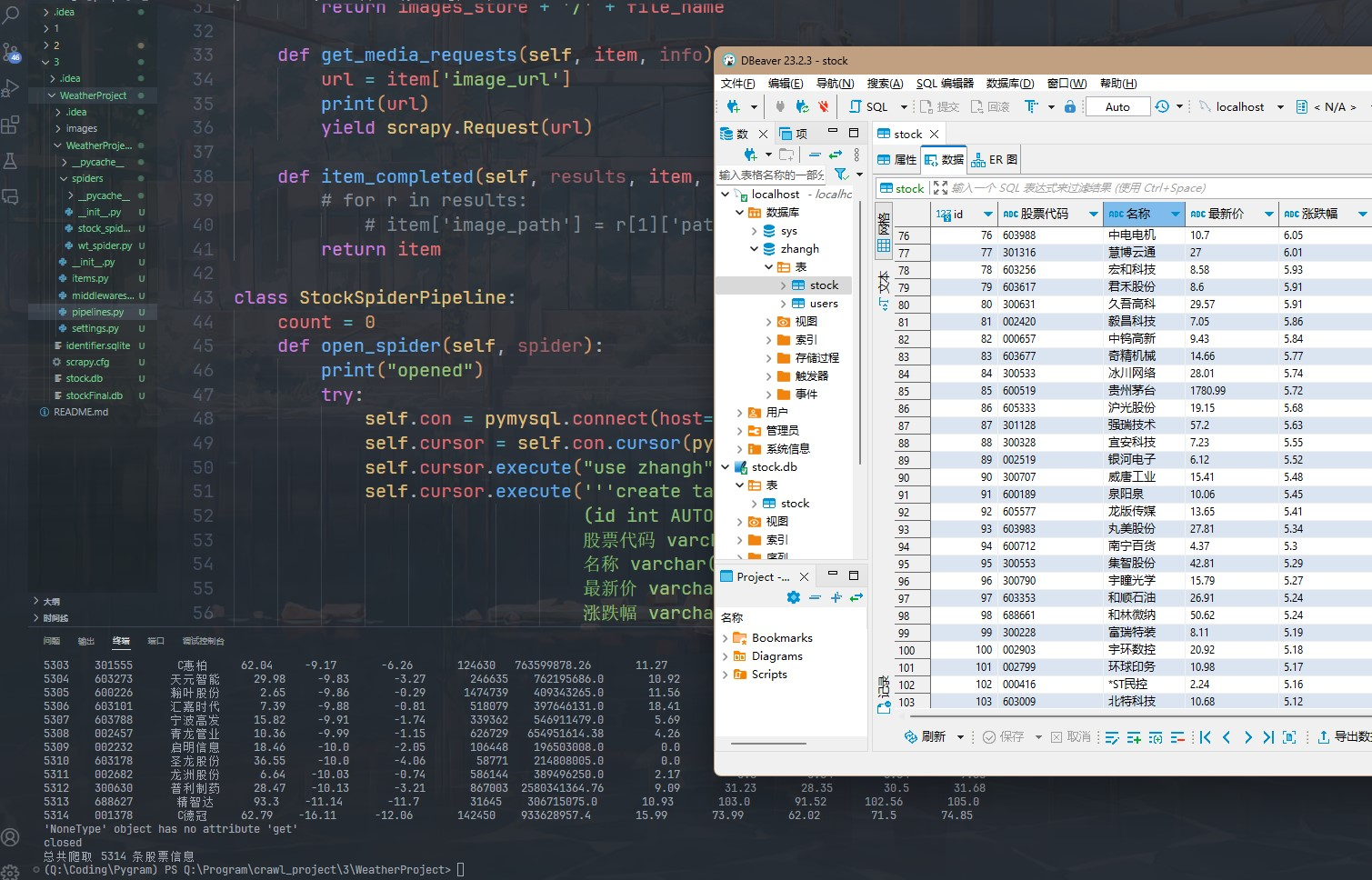
作业③:
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/ -
文件夹链接:https://gitee.com/showur/crawl_project/tree/master/3/WeatherProject
代码
items.py
class ForexItem(scrapy.Item):
name = scrapy.Field()
price1 = scrapy.Field()
price2 = scrapy.Field()
price3 = scrapy.Field()
price4 = scrapy.Field()
price5 = scrapy.Field()
date = scrapy.Field()
pipelines.py
class Forex_Pipeline:
def open_spider(self,spider):
print('%-10s%-10s%-10s%-10s%-10s%-10s%-10s' % ('货币名称','现汇买入价','现钞买入价','现汇卖出价','现钞卖出价','中行折算价','发布日期'))
def process_item(self, item, spider):
print('%-10s%-10s%-10s%-10s%-10s%-10s%-10s' % (item['name'],item['price1'],item['price2'],item['price3'],item['price4'],item['price5'],item['date']))
return item
spider.py
import scrapy
from WeatherProject.items import ForexItem
class ForexSpider(scrapy.Spider):
name = 'forex_spider'
# allowed_domains = ['www.boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
data = response.body.decode()
selector=scrapy.Selector(text=data)
data_lists = selector.xpath('//table[@align="left"]/tr')
for data_list in data_lists:
datas = data_list.xpath('.//td')
if datas != []:
item = ForexItem()
keys = ['name','price1','price2','price3','price4','price5','date']
str_lists = datas.extract()
for i in range(len(str_lists)-1):
item[keys[i]] = str_lists[i].strip('<td class="pjrq"></td>').strip()
yield item
运行结果
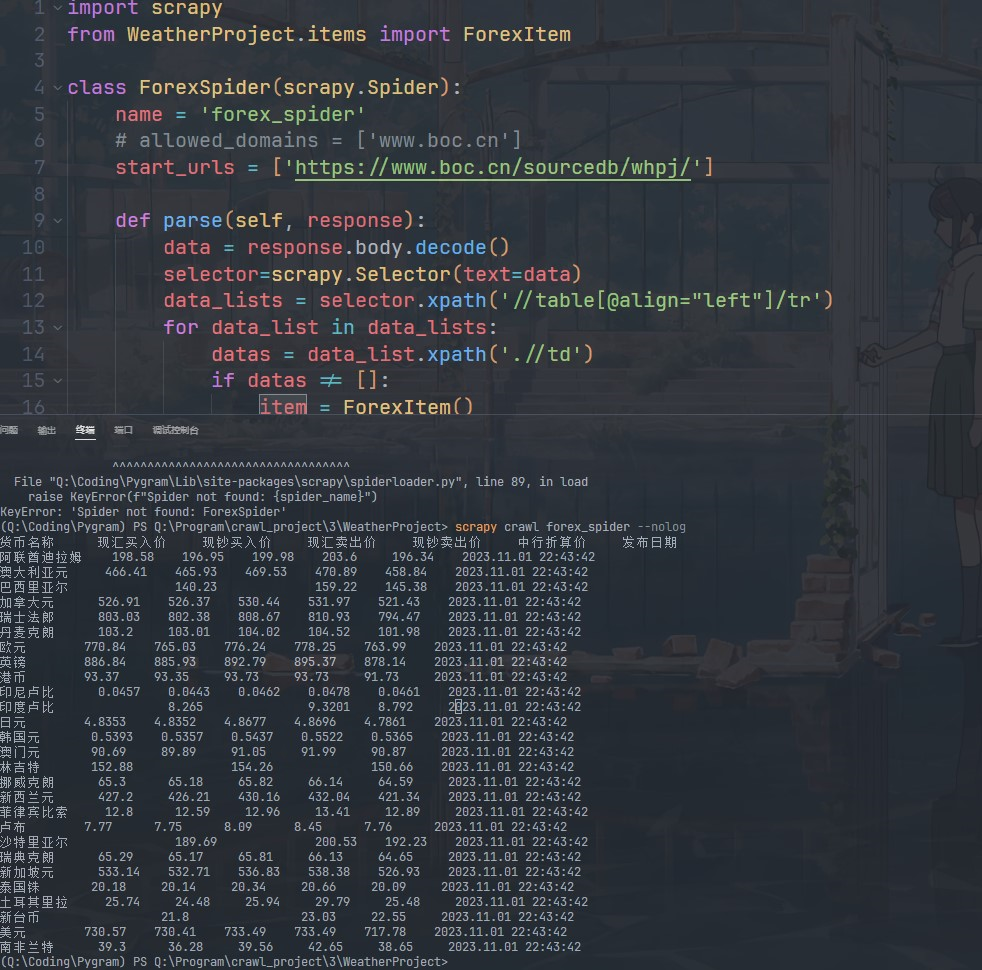

 浙公网安备 33010602011771号
浙公网安备 33010602011771号