

NLP教程(8) - NLP中的卷积神经网络
 本文介绍 NLP 中的卷积神经网络(CNN),讲解卷积神经网络的卷积层、池化层、多卷积核、多通道、卷积核、N-gram、filter、k-max pooling、文本分类等。
本文介绍 NLP 中的卷积神经网络(CNN),讲解卷积神经网络的卷积层、池化层、多卷积核、多通道、卷积核、N-gram、filter、k-max pooling、文本分类等。

- 作者:韩信子@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/36
- 本文地址:https://www.showmeai.tech/article-detail/247
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

本系列为斯坦福CS224n《自然语言处理与深度学习(Natural Language Processing with Deep Learning)》的全套学习笔记,对应的课程视频可以在 这里 查看。

ShowMeAI为CS224n课程的全部课件,做了中文翻译和注释,并制作成了 GIF动图!点击 第11讲-NLP中的卷积神经网络 查看的课件注释与带学解读。更多资料获取方式见文末。
引言
CS224n是顶级院校斯坦福出品的深度学习与自然语言处理方向专业课程,核心内容覆盖RNN、LSTM、CNN、transformer、bert、问答、摘要、文本生成、语言模型、阅读理解等前沿内容。
本篇笔记对应斯坦福CS224n自然语言处理专项课程的知识板块:NLP中的卷积神经网络。主要讲解卷积神经网络的结构,及其在NLP场景下的使用方式,一些模块和可调结构。
笔记核心词
- 卷积神经网络 / CNN
- 卷积层
- 池化层
- 多卷积核
- 多通道 / Multiple-Channels
- 卷积核
- N-gram
- filter
- k-max pooling
- 文本分类
1.NLP中的卷积神经网络
1.1 为什么使用CNN
卷积神经网络是一种特殊结构的神经网络,最早被广泛应用于计算机视觉领域,但在NLP领域同样有着显著的应用效果。它相对于传统神经网络,引入了局部感受野和多滤波器概念,能在控制参数量的情况下,对输入数据进行高效地处理。具体到NLP中,它接收词向量的序列,并首先为所有子短语创建短语向量(embedding),然后CNNs 基于卷积核并行完成数据处理计算。
(关于CNN的细节也可以参考ShowMeAI的对吴恩达老师课程的总结文章 深度学习教程 | 卷积神经网络解读,内含动图讲解)
1.2 什么是卷积
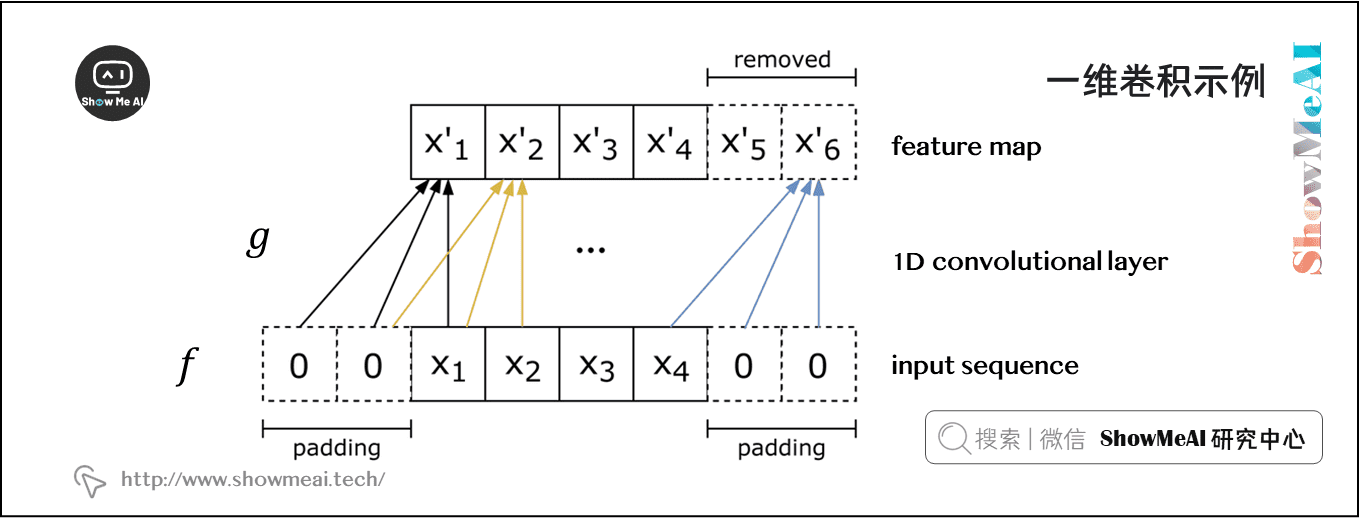
我们从一维的情况开始。考虑两个一维向量 \(f\) 和 \(g\) ,其中 \(f\) 是主向量,\(g\) 是 filter。\(f\) 和 \(g\) 之间的卷积,第 \(n\) 项处的值表示为 \((f \ast g)[n]\),它等于 \(\sum_{m=-M}^{M} f[n-m] g[m]\) 。
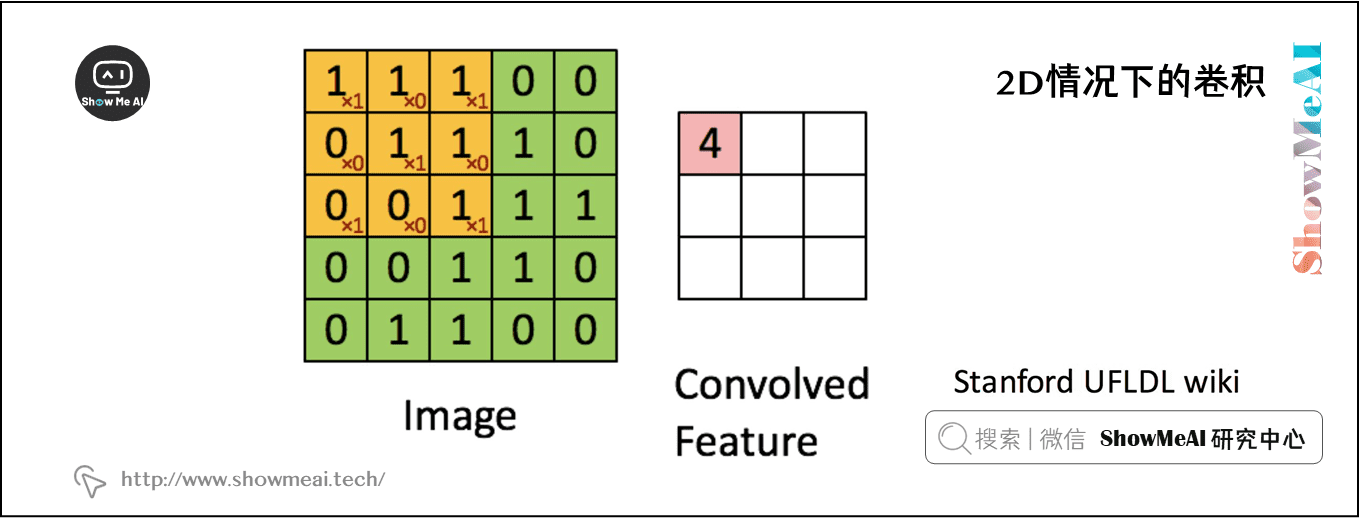
对于二维卷积而言,计算如下所示,\(9\times9\) 的绿色矩阵表示关注的主矩阵 \(f\) (在实际应用中就是输入数据矩阵)。\(3\times3\) 的红色矩阵表示 filter \(g\),当前正在计算的卷积位于起始位置,计算方式为 filter 和 input 区域的逐元素乘法再求和,计算结果为4。
这里使用 ShowMeAI 深度学习教程 | 卷积神经网络解读 文章中的一个动态计算过程:
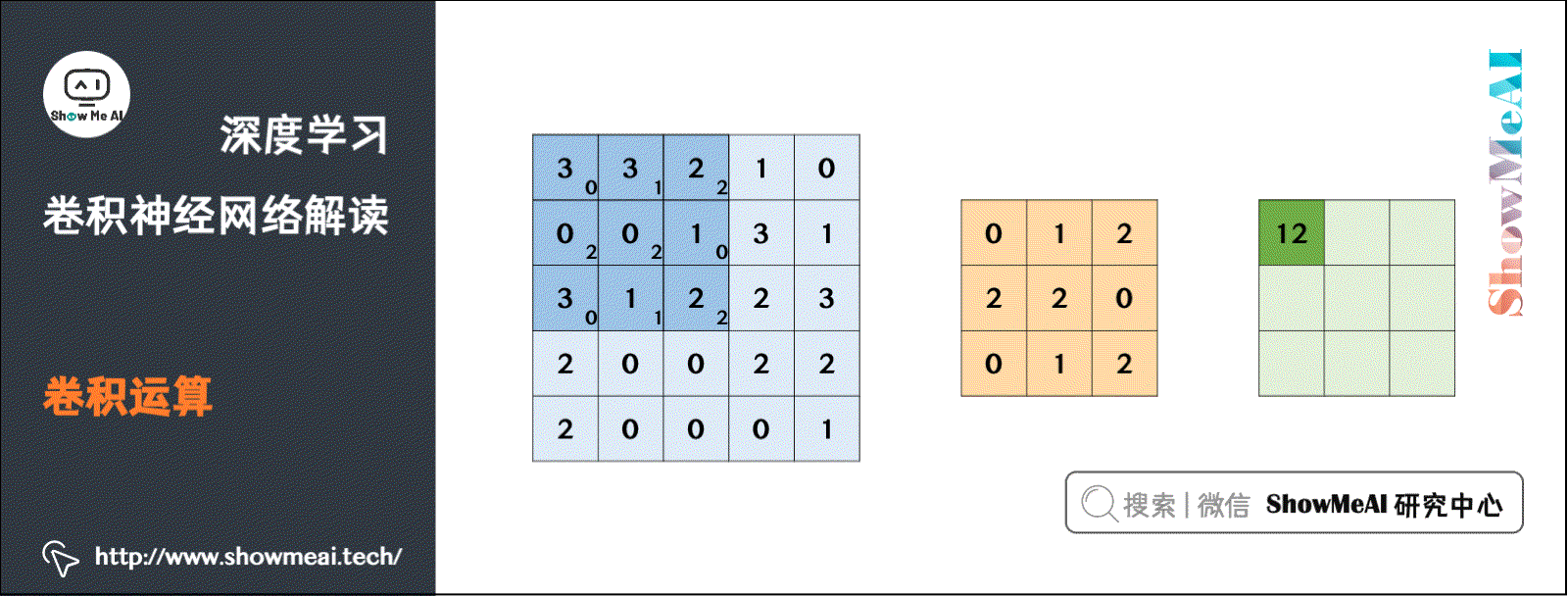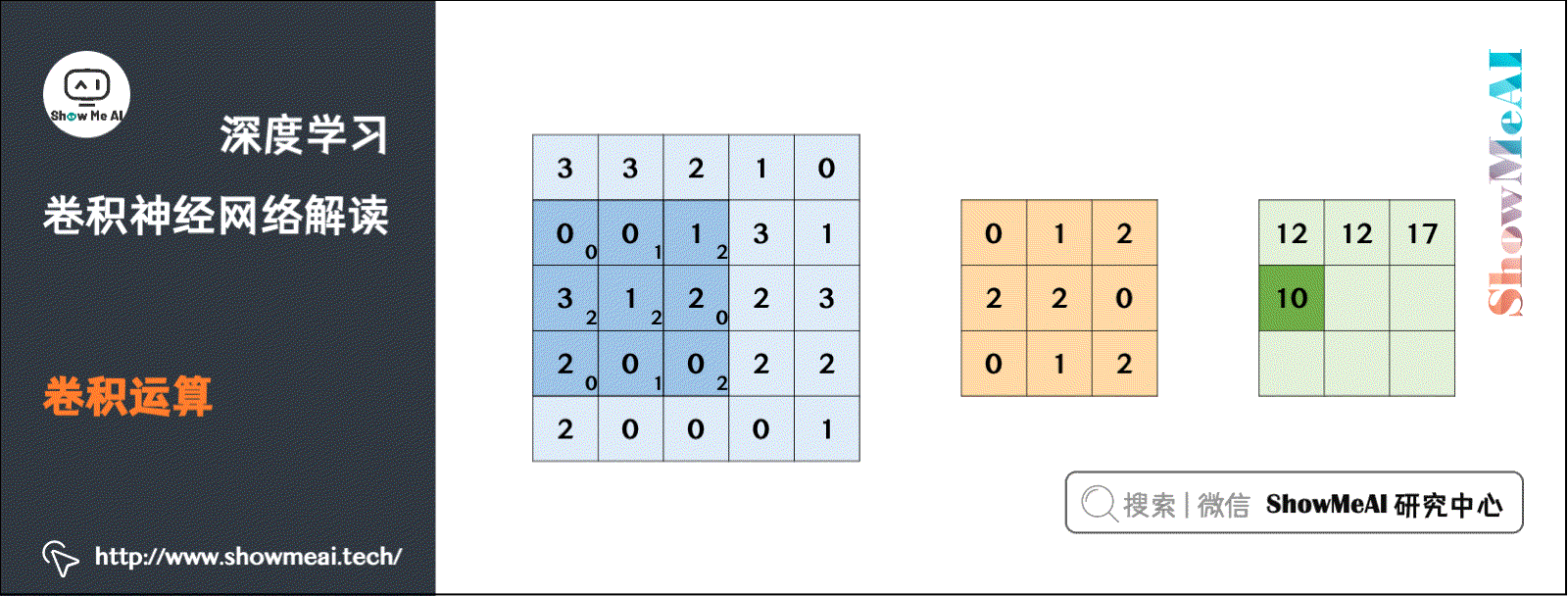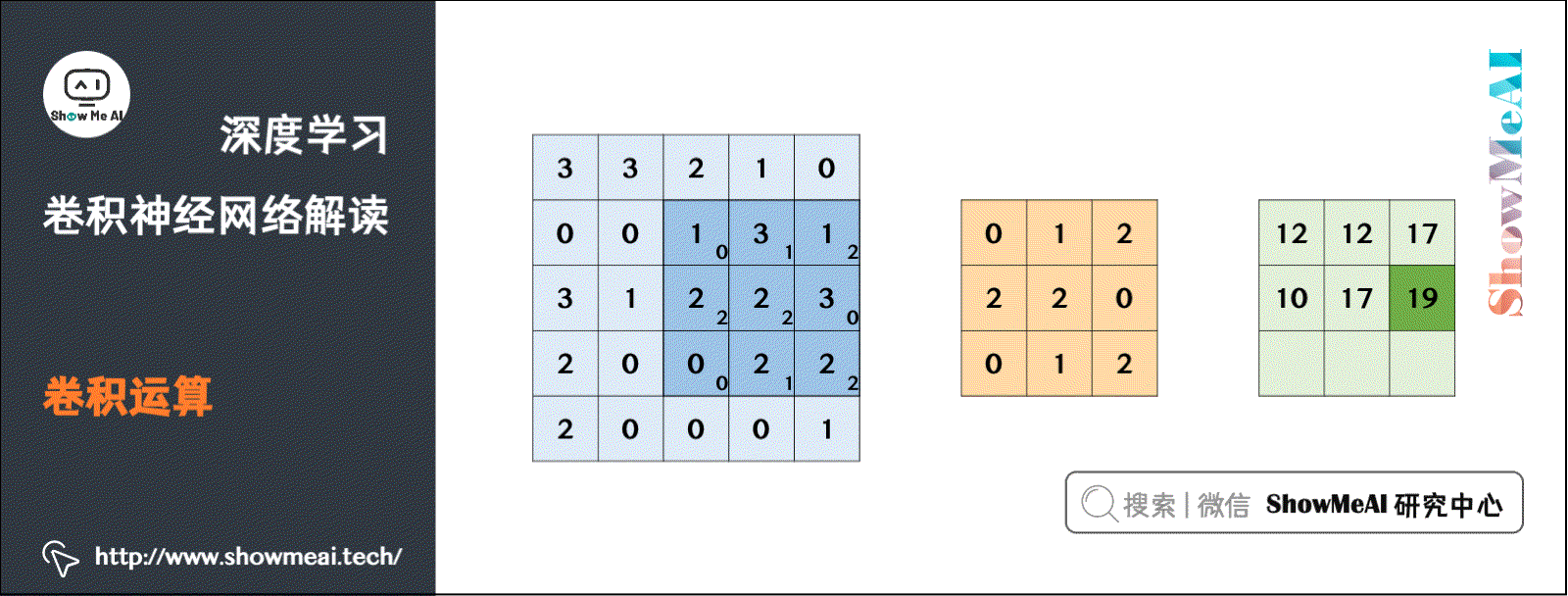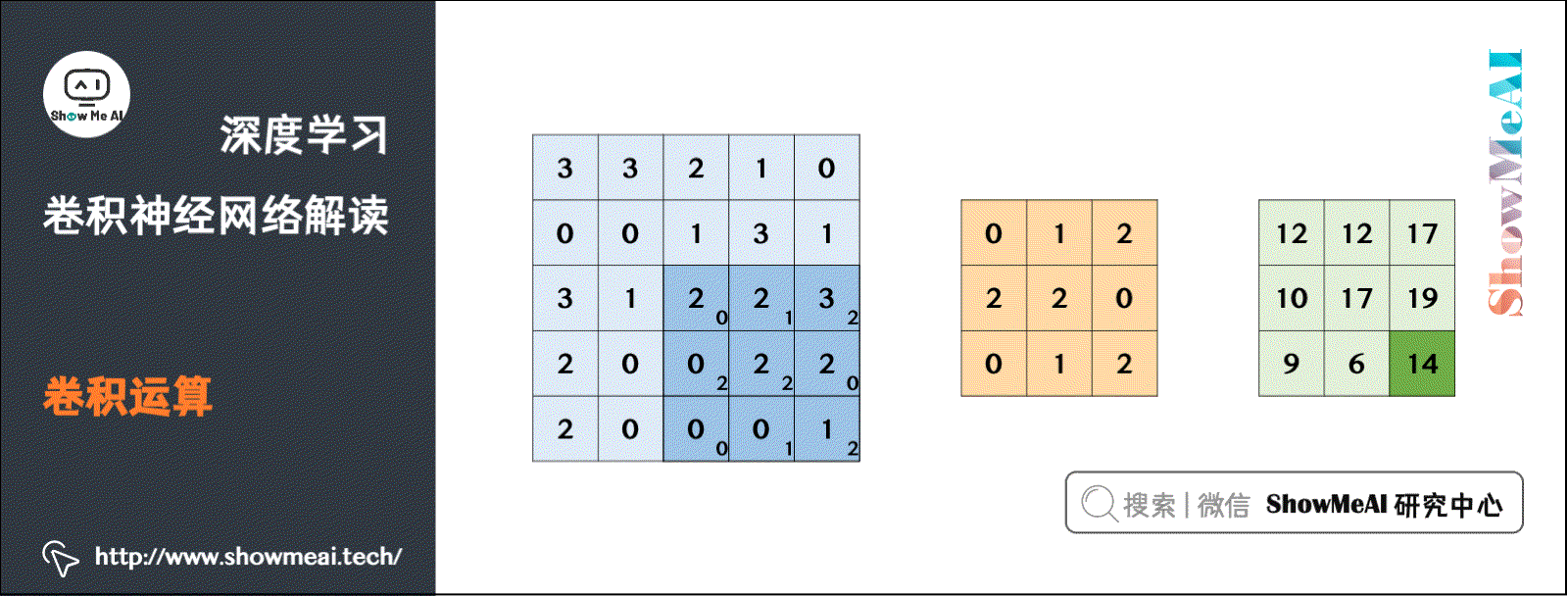
1.3 卷积层讲解
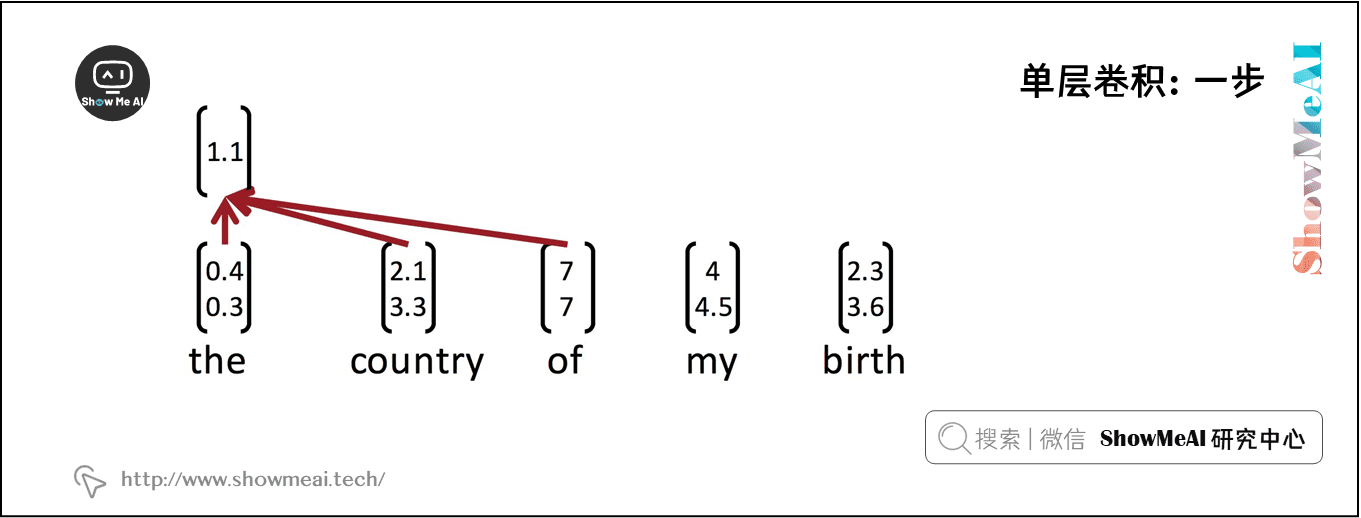
考虑单词向量 \(x_{i} \in R^{k}\) 和一个 \(n\) 个单词的句子的单词向量串联, \(x_{1 : n}=x_{1} \oplus x_{2} \ldots \oplus x_{n}\) 。最后,考虑卷积滤波器 \(w \in R^{h k}\) ,即作用于 \(h\) 个单词。对于 \(k = 2, n = 5, h = 3\),上图为NLP的单层卷积层。在 the country of my birth 这个句子中,连续三个单词的每一个可能组合都将得到一个值。
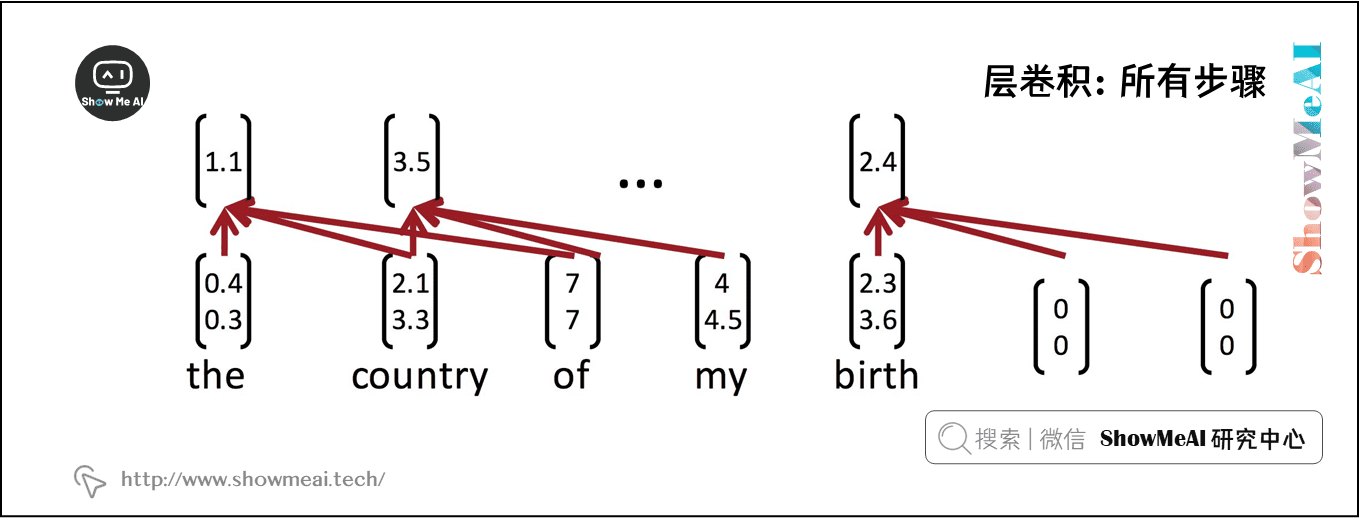
注意,滤波器 \(w\) 本身是一个向量,我们将有 \(c_{i}=f\left(w^{T} x_{i : i | h-1}+b\right)\) 来给出 \(\mathbf{c}=\left[c_{1}, c_{2} \dots c_{n-h+1}\right] \in R^{n-h+1}\) 。最后两个时间步,即从 my 或 birth 开始,我们没有足够的字向量来与滤波器相乘(因为 \(h = 3\))。如果我们需要与后两个词向量相关的卷积,一个常见的技巧是用\(h - 1\)个零向量填充句子的右边,如上图所示。
1.4 池化层讲解
假设我们不使用补零,我们将得到最终的卷积输出, \(\mathbf{c}\) 有 \(n-h+1\) 个数。通常,我们希望接收CNN的输出,并将其作为输入,输入到更深层,如前馈神经网络或RNN。但是,所有这些都需要一个固定长度的输入,而CNN输出的长度依赖于句子的长度 \(n\) 。解决这个问题的一个聪明的方法是使用max-pooling。CNN的输出 \(\mathbf{c} \in \mathbb{R}^{n-h-1}\) 是 max-pooling 层的输入。max-pooling 的输出层 \(\hat{c}=\max {\mathbf{c}}\) ,因此 \(\hat{c} \in \mathbb{R}\) 。
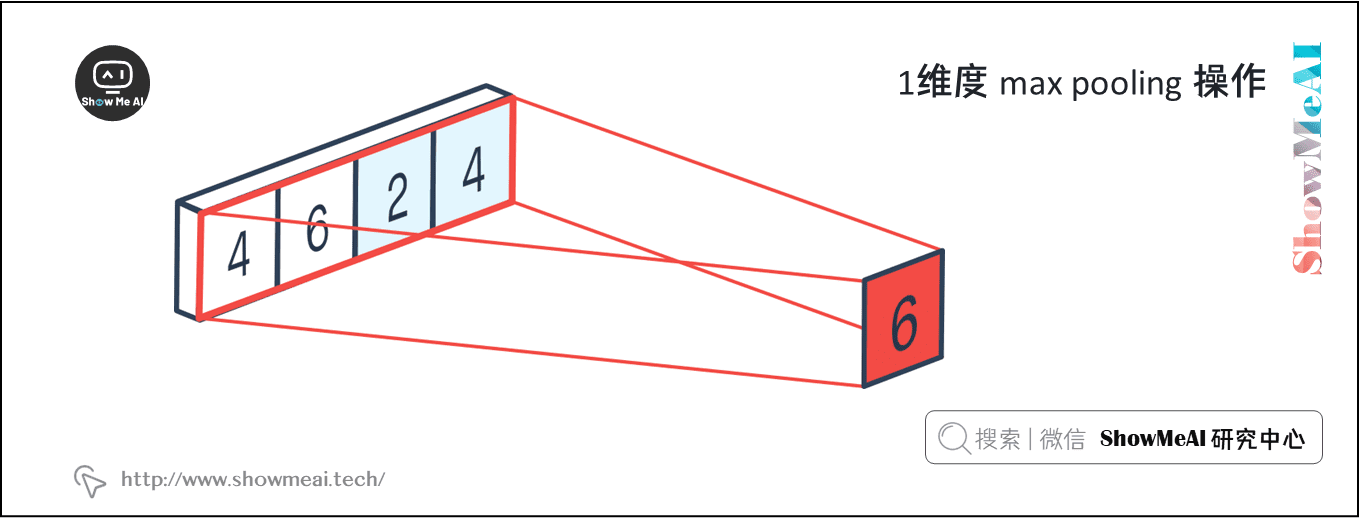
我们也可以使用最小池化,因为通常我们使用 ReLU 作为非线性激活函数而ReLU的下界是 \(0\)。因此,一个最小池化可能会被 ReLU 覆盖,所以我们几乎总是使用最大池化而不是最小池化。
1.5 多卷积核
在上面与图2相关的例子中,我们有 \(h = 2\),这意味着我们只使用一个特定的组合方法,即使用过滤器来查看 bi-grams。我们可以使用多个 bi-grams 过滤器,因为每个过滤器将学习识别不同类型的 bi-grams。更一般地说,我们并不仅限于使用 bi-grams ,还可以使用 tri-grams、 quad-grams 甚至更长的过滤器。每个过滤器都有一个关联的最大池化层。因此,CNN 层的最终输出将是一个长度等于过滤器数量的向量。
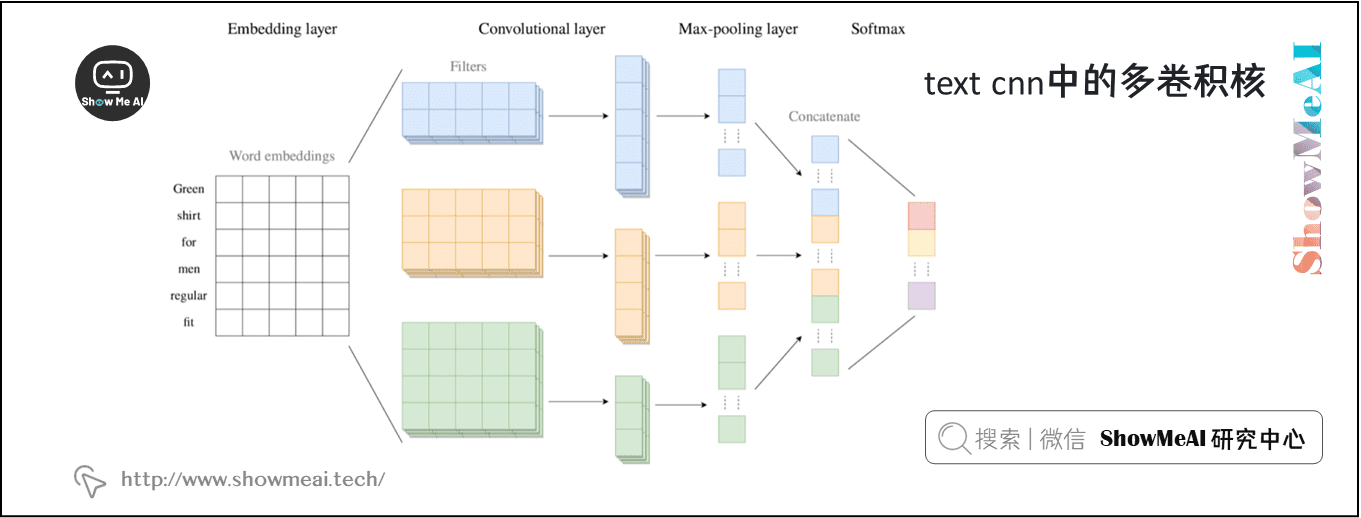
1.6 多通道
如果我们允许梯度流入这里使用的单词向量,那么单词向量可能会随着训练而发生显著变化。这是需要的,因为它将单词向量专门用于当前特定任务(远离 GloVe 初始化)。但是,如果单词只出现在测试集中而没有出现在训练集上呢?虽然出现在训练集中的其他语义相关的单词向量将从它们的起始点显著移动,但是这些单词仍将处于它们的初始点。神经网络将专门用于已更新的输入。因此,我们在使用这些单词的句子中会表现得很差。
一种方法是维护两组单词向量,一组“静态”(没有梯度流)和一组“动态”(通过 SGD 更新)。它们最初是一样的(GloVe 或者其他初始化)。这两个集合同时作为神经网络的输入。因此,初始化的词向量在神经网络的训练中始终起着重要的作用。在测试中给出看不见的单词可以提高正确理解的几率。
有几种处理这两个 channel 的方法,最常见的是在 CNN 中使用之前对它们进行平均。另一种方法是将 CNN 过滤器的长度加倍。也可以在经过卷积层之后得到feature maps再进行合并(比如下图一样做pooling操作合并)
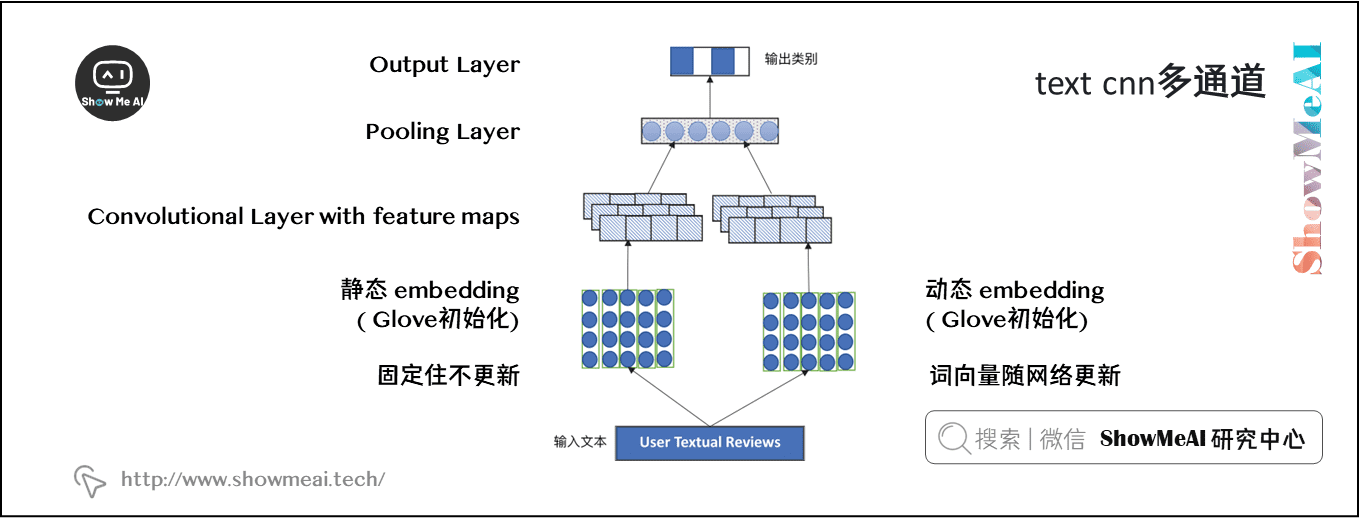
1.7 CNN结构选择
1) 宽卷积还是窄卷积
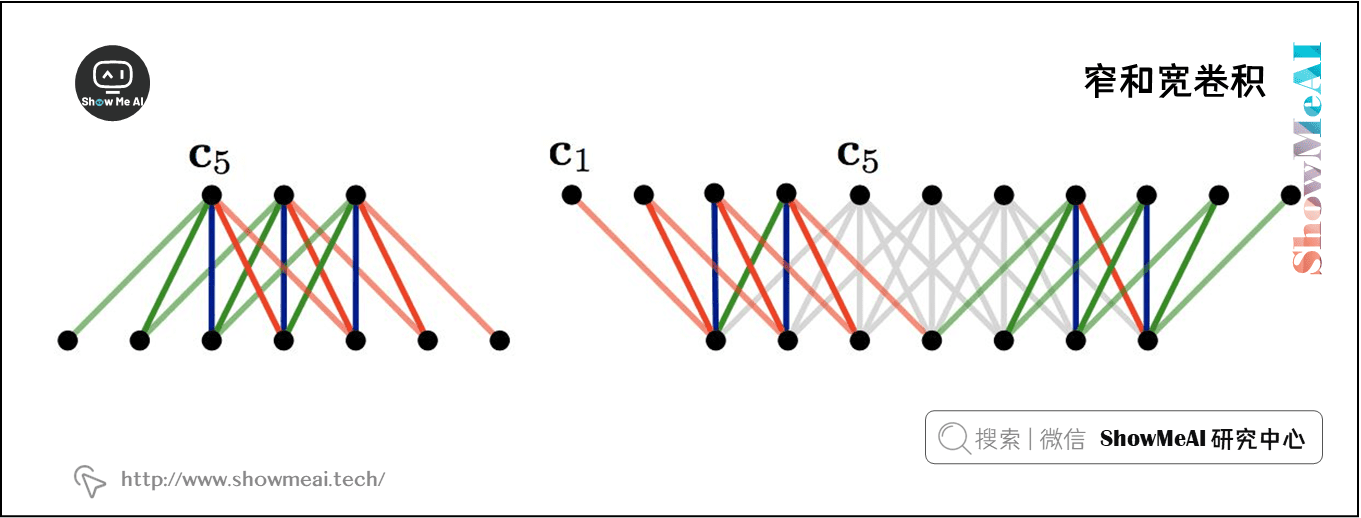
参见上图。另一种问这个问题的方法是我们应该缩小还是扩大?即我们是否使用 zero-pad?
如果我们使用窄卷积,我们只在一个滤波器的所有分量都有一个匹配输入分量的位置计算卷积。在输入的开始和结束边界处显然不是这样,如图4中的左侧网络所示。
如果我们使用宽卷积,我们有一个输出分量对应于卷积滤波器的每个对齐。为此,我们必须在输入的开始和结束处填充 \(h - 1\) 个零。
在窄卷积情况下,输出长度为 \(n - h+ 1\) ,而在宽卷积情况下,输出长度为 \(n+h - 1\)。
2) k-max池化
这是对最大池化层的概括。k-max 池化层不是只从它的输入中选择最大的值,而是选择 \(k\) 个最大的值(并且保持原有的顺序)。设置 \(k = 1\) 则是我们前面看到的最大池化层。

2.参考资料
- 本教程的在线阅读版本
- 《斯坦福CS224n深度学习与自然语言处理》课程学习指南
- 《斯坦福CS224n深度学习与自然语言处理》课程大作业解析
- 【双语字幕视频】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲)
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
NLP系列教程文章
- NLP教程(1)- 词向量、SVD分解与Word2vec
- NLP教程(2)- GloVe及词向量的训练与评估
- NLP教程(3)- 神经网络与反向传播
- NLP教程(4)- 句法分析与依存解析
- NLP教程(5)- 语言模型、RNN、GRU与LSTM
- NLP教程(6)- 神经机器翻译、seq2seq与注意力机制
- NLP教程(7)- 问答系统
- NLP教程(8)- NLP中的卷积神经网络
- NLP教程(9)- 句法分析与树形递归神经网络
斯坦福 CS224n 课程带学详解
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
- 斯坦福NLP课程 | 第3讲 - 神经网络知识回顾
- 斯坦福NLP课程 | 第4讲 - 神经网络反向传播与计算图
- 斯坦福NLP课程 | 第5讲 - 句法分析与依存解析
- 斯坦福NLP课程 | 第6讲 - 循环神经网络与语言模型
- 斯坦福NLP课程 | 第7讲 - 梯度消失问题与RNN变种
- 斯坦福NLP课程 | 第8讲 - 机器翻译、seq2seq与注意力机制
- 斯坦福NLP课程 | 第9讲 - cs224n课程大项目实用技巧与经验
- 斯坦福NLP课程 | 第10讲 - NLP中的问答系统
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
- 斯坦福NLP课程 | 第12讲 - 子词模型
- 斯坦福NLP课程 | 第13讲 - 基于上下文的表征与NLP预训练模型
- 斯坦福NLP课程 | 第14讲 - Transformers自注意力与生成模型
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
- 斯坦福NLP课程 | 第16讲 - 指代消解问题与神经网络方法
- 斯坦福NLP课程 | 第17讲 - 多任务学习(以问答系统为例)
- 斯坦福NLP课程 | 第18讲 - 句法分析与树形递归神经网络
- 斯坦福NLP课程 | 第19讲 - AI安全偏见与公平
- 斯坦福NLP课程 | 第20讲 - NLP与深度学习的未来


 浙公网安备 33010602011771号
浙公网安备 33010602011771号