Kafka学习笔记
一.核心概念:
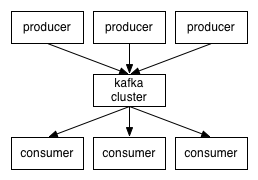
Kafka是一个分布式消息中间件,以集群的方式运行,可以由多个服务组成,每个服务叫做一个broker
Kafka中每条消息是由一个key,一个value和时间戳构成。
Kafka会对其数据分区,每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。每个消息都有一个连续的序列号(offset),用来在分区中唯一标识。读取时的数据指针由Kafka消费者维护。
Kafka集群在一定时间内保留所有发布的消息,不管这些消息有没有被消费,这个时间可以配置,之后消息将被丢弃。
Kafka分区的特性保证单个服务器上保存的数据量不会太大,且提高了并发。
Kafka为所有数据提供副本,保证了已订程度的容错。
Leader-Follower模式: 每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求,而follower被动的复制数据。一台服务器可能同时是一个分区的leader,另一个分区的follower
避免了所有请求只由几台服务器处理
producer通过负载均衡或分区函数选择分区(partition)。
Kafka在多个消费者并行消费的情况下很难保证消息的先后顺序,但如果像传统消息队列那样只用一个消费者又会降低消费速度,Kafka的分区机制保证了一个topic分区下的先后顺序,但多个跨分区先后顺序无法保证。
同一个消费者组里消费者数量不能比partition数量更多,否则多出来的消费者只会空等待。
消息模式:
1.队列模式:每个消息只被其中一个consumer读到
2.发布订阅模式:消息被广播到所有的consumer
3.consumer group:consumers可以加入一个consumer 组,组里所有成员竞争一个topic(如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,
这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中)
Kafka为什么不使用内存存储消息?
使用内存存储重启是速度太慢,Java对象占用内存太多。
消息事务:
1.最多一次,也可能不传
2.最少一次,可能重复
3.精确的一次
Kafka允许producer灵活的指定级别。比如producer可以指定必须等待消息被提交的通知,或者完全的异步发送消息而不等待任何通知,或者仅仅等待leader声明它拿到了消息(followers没有必要),该特性通过producer端的ack属性配置
consumer方面:
- consumer可以先读取消息,然后将offset写入日志文件中,然后再处理消息。这存在一种可能就是在存储offset后还没处理消息就crash了,新的consumer继续从这个offset处理,那么就会有些消息永远不会被处理,这就是上面说的“最多一次”。
- consumer可以先读取消息,处理消息,最后记录offset,当然如果在记录offset之前就crash了,新的consumer会重复的消费一些消息,这就是上面说的“最少一次”。
- “精确一次”可以通过将提交分为两个阶段来解决:保存了offset后提交一次,消息处理成功之后再提交一次。但是还有个更简单的做法:将消息的offset和消息被处理后的结果保存在一起。比如用Hadoop ETL处理消息时,将处理后的结果和offset同时保存在HDFS中,这样就能保证消息和offser同时被处理了。
流处理:
获取输入topic-》进行处理-》写入输入topic
Kafka提供了更复杂的Stream API用于聚合计算
参考:
https://blog.csdn.net/tangdong3415/article/details/53432166
http://orchome.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号