LlamaIndex高级使用
什么是 LlamaIndex 在 Rag 发挥的作用 以及与传统 Rag 的区别
1.LlamaIndex 简介
LlamaIndex(原 GPT Index)是一个专门为大模型构建索引、检索和数据管道的框架,核心目标是让 LLM 更好地连接和利用私有数据。
传统 RAG 通常是这样实现的:
# 传统 RAG 伪代码
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
# 1. 切分文档
texts = text_splitter.split_documents(documents)
# 2. 向量化 + 存储
vectorstore = FAISS.from_documents(texts, OpenAIEmbeddings())
# 3. 检索 + 生成
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever()
)
问题:
- 数据加载、切分、索引需要自己写很多代码
- 检索策略单一(通常是简单的向量相似度)
- 缺乏对数据结构的深度优化
- 难以处理复杂的多模态、多源数据
LlamaIndex 在 RAG 中的作用
1. 数据连接层
from llama_index import SimpleDirectoryReader, VectorStoreIndex
# 一行代码加载多种数据源
documents = SimpleDirectoryReader('data').load_data()
# 支持 PDF、Markdown、JSON、数据库、API、Notion 等 100+ 数据源
2. 智能索引策略
from llama_index import VectorStoreIndex, ListIndex, TreeIndex
# 不同索引策略适应不同场景
vector_index = VectorStoreIndex.from_documents(documents) # 向量索引
tree_index = TreeIndex.from_documents(documents) # 树形索引(层次化)
list_index = ListIndex.from_documents(documents) # 列表索引(顺序检索)
3. 高级检索能力
# 混合检索:向量 + ��键词
query_engine = index.as_query_engine(
retrieval_mode="hybrid", # 混合检索
similarity_top_k=5,
alpha=0.7 # 向量检索权重
)
# 自动重查询(Query Transformation)
query_engine = index.as_query_engine(
mode="recursive_retrieve", # 递归检索
use_async=True,
)
4. 结构化数据解析
from llama_index.readers import SimpleReader
# 自动识别表格、图表、层级结构
documents = reader.load_data(
file_path="report.pdf",
extract_tables=True, # 提取表格
extract_images=True # 提取图片
)
核心优势示例
传统 RAG 检索(简单向量检索)
只能找到语义相似的片段
query = "公司的财务状况如何?"
返回:提到"财务"的某个片段,可能不准确
LlamaIndex 检索(智能路由 + 多层检索)
自动理解查询意图,选择最优检索路径
query = "公司的财务状况如何?"
- 识别这是关于财务的查询
- 路由到财务相关索引(如果有分片)
- 先检索关键字 + 向量混合
- 自动重排序结果
- 返回最相关的财务报表片段
什么时候用 LlamaIndex?
✅ 适合使用 LlamaIndex 的场景:
- 数据源复杂(多种格式、多模态)
- 需要高精度检索(医疗、法律、金融)
- 文档结构化程度高(技术文档、财报)
- 需要灵活的检索策略(不只是向量相似度)
❌ 可以用传统 RAG 的场景:
- 简单的文本问答
- 数据源单一(纯文本)
- 快速原型验证
总结
LlamaIndex 本质上是 RAG 的"专业版":
- 传统 RAG:自己搭积木,需要处理每个环节
- LlamaIndex:封装了数据→索引→检索的全流程,提供更智能的检索策略
可以把 LlamaIndex 理解为 "给 LLM 准备数据的操作系统",让数据检索这件事变得更专业、更高效。
2. llamaindex 核心组件
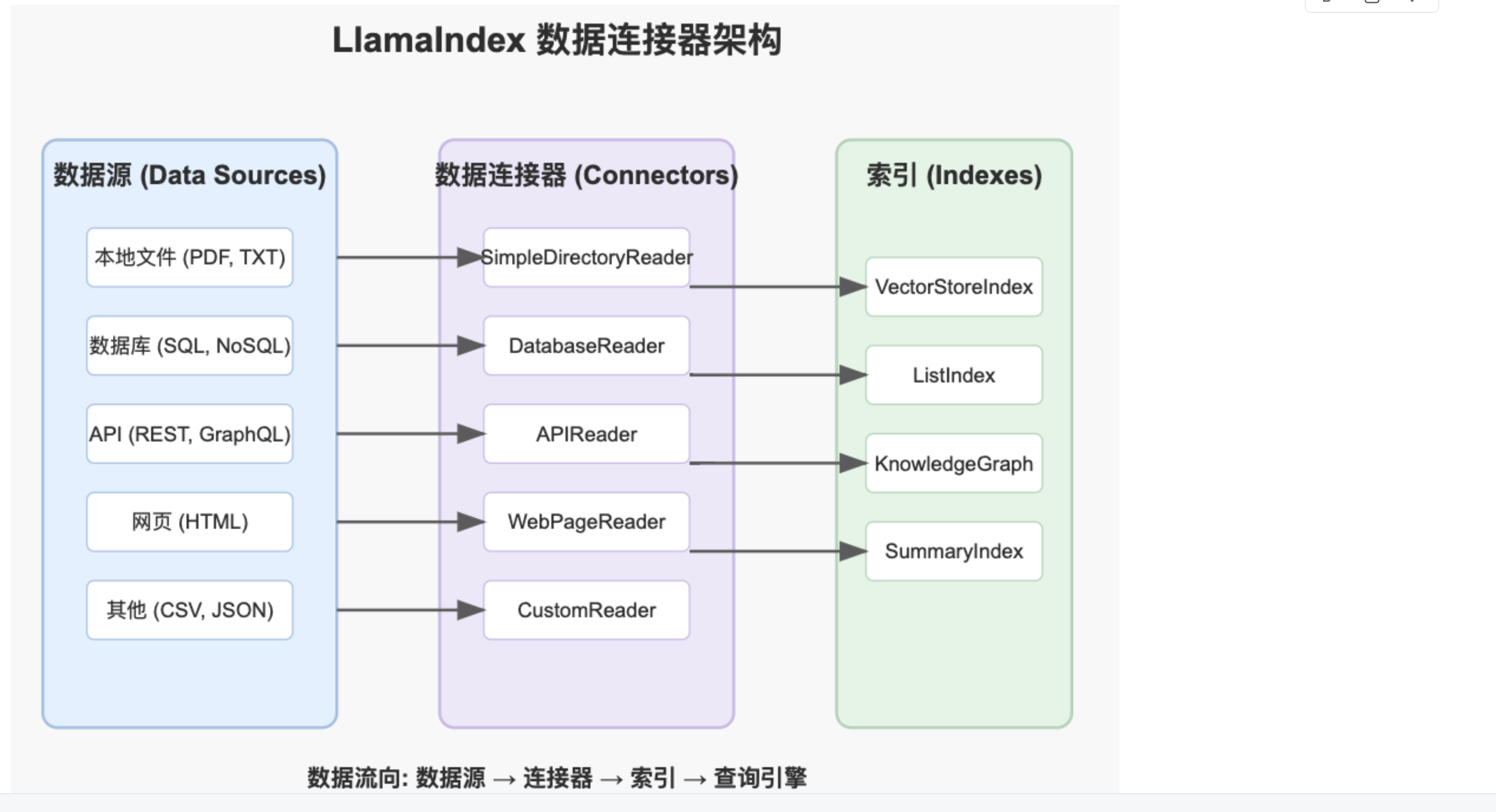
plaintext
1. Data Connectors(数据连接器)
功能:用于从各种数据源(数据库、API、文件系统等)提取数据,并将其转换为适合 LlamaIndex 处理的格式。
支持的数据源:
- 本地文件(TXT、PDF、CSV、JSON、Markdown 等)
- 数据库(PostgreSQL、MongoDB、SQL 等)
- Web 爬取(网站、Notion、Google Drive、Slack)
- API(调用 REST API 或 GraphQL API 获取数据)
代码示例:
import os
# 设置环境变量(LlamaIndex 会自动读取)
os.environ['OPENAI_API_KEY'] = 'sk-wEIft9KDlqY9'
os.environ['OPENAI_API_BASE'] = 'https://xiaoai.plus/v1'
#%%
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 读取本地文档
reader = SimpleDirectoryReader(
input_dir="./data",
required_exts=[".pdf"],
recursive=True #递归读取子目录
)
# 创建文档读取器(方式二:简单方式)
# 注意:这行覆盖了上面的 reader,所以上面的配置没用了
reader = SimpleDirectoryReader("./data") # 读取 data 目录下所有支持的文件
documents_origin = reader.load_data()
#%%
from pprint import pprint
for document in documents_origin:
pprint(document.text)
print('-'*130)
index = VectorStoreIndex.from_documents(documents_origin)
#步骤三,构建查询引擎
query_engine = index.as_query_engine()
#步骤四,得到结果
response = query_engine.query("同仁堂安宫牛黄丸的市场价格,中文回答")
print(response)
上述是一个基础的读取器,但是还存在两个问题
* 我们能不能继续扩大我们的处理数据来源呢:包含本地文件、网页、数据库等等
* 我们发现他并不能很好地读取图片、表格的数据【RAG面试必问问题】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号