RAG深入向量算法与Milvus实战
RAG深入向量算法与Milvus实战
1、三大向量相似度度量

- 余弦相似度 关注方向 【角度】
- 应用:文本相似度
- 欧式距离 关注位置【距离】
- 应用:主要匹配为支点,因此主要应用在人脸识别
- 内积/点积 关注 方向【方向 大小】
- 应用: 用户偏好 X 商品特征 主要用于商品推荐
一句话总结: 需要归一化数据用余弦,位置敏感用欧式,综合评分用内积
2、向量搜索最核心的两种算法

-
K 最近邻 (K- nearest neighbor - kNN )-精确搜索
-
算法特点:
- 暴力搜索,遍历所有数据点
- 时间复杂度 O(n-d)
- 准确率 100%
- 10亿数据需要10s+
-
近似最近邻 (approximate nearest neighbor - aNN) -近似搜索
-
算法特点:
-
索引优化:跳过大部分数据
-
时间复杂度O(logn)
-
准确率:95-99%
-
10亿数据只需要100ms
核心思想是:通过预建索引,将搜索空间划分,避免全量扫描
-
-
3、主流的ANN算法
1. **HNSW(分层导航小世界)**
-
多层图结构,逐层精细搜索
-
速度快、精度高(99%)
-
查询延迟 50ms
-
适合高精度要求场景
- IVF(倒排文件索引)
-
K-means 聚类分桶
-
先找最近簇中心,再簇内搜索
-
内存效率高,适合大规模数据
-
查询延迟 100ms,准确率 95%
- LSH(局部敏感哈希)
-
随机投影哈希
-
按相似性分桶
-
构建最快(10分钟),内存占用最低(3.1TB)
-
适合高维稀疏数据,准确率 90%
性能对比(基于十亿级 768 维向量数据)
┌──────┬──────────┬──────────┬───────┬────────┐
│ 算法 │ 构建时间 │ 查询延迟 │ 内存 │ 准确率 │
├──────┼──────────┼──────────┼───────┼────────┤
│ KNN │ 无需构建 │ 10s+ │ 3TB │ 100% │
├──────┼──────────┼──────────┼───────┼────────┤
│ HNSW │ 2小时 │ 50ms │ 3.5TB │ 99% │ 常用
├──────┼──────────┼──────────┼───────┼────────┤
│ IVF │ 30分钟 │ 100ms │ 3.2TB │ 95% │ 常用
├──────┼──────────┼──────────┼───────┼────────┤
│ LSH │ 10分钟 │ 80ms │ 3.1TB │ 90% │
└──────┴──────────┴──────────┴───────┴────────┘
核心结论:KNN 在大规模数据下不可用;HNSW 是速度和精度的最佳平衡;IVF 适合大规模数据;LSH 适合稀疏数据场景。


4、Milvus实战
4.1离线文档入库
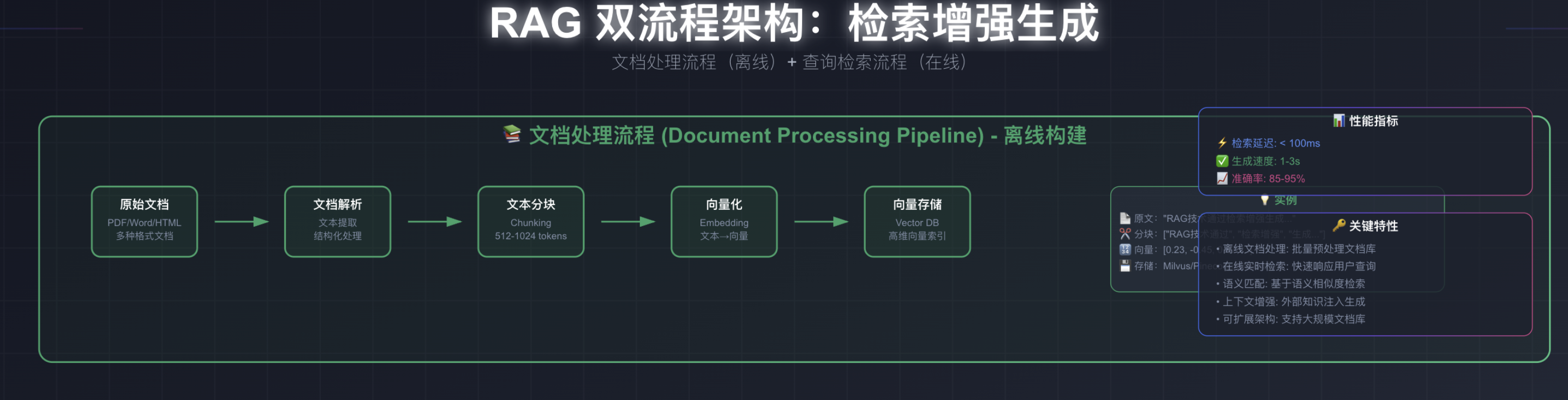
这是一个文档处理的构建流程,里面的一个关键点是文本分块,我昨天在写项目的时候,好奇为什么要分块,分块不是把好好的语译中断了吗? 但是实际上大模型没办法一次性处理太多token,分块的作用是把一本书拆分成一个个章节,文本中断问题也会有对应的策略去处理,比如取文本的上下文。特别考验切分技术。也是工业级项目最关键的一个步骤


 浙公网安备 33010602011771号
浙公网安备 33010602011771号