RAG和Embeddings模型
一、Embeddings模型
1.什么是Embeddings模型
- Embedding模型是指将高维度的数据(例如文字、图片、视频)映射到低维度空间的过程。简单来说,embedding向量就是一个N维的实值向量,它将输入的数据表示成一个连续的数值空间中的点。Embeddings的学习通常基于无监督或弱监督的方法。对于自然语言处理任务,常用的Embeddings方法包括Word2Vec、GloVe和FastText(属于算法层面)。
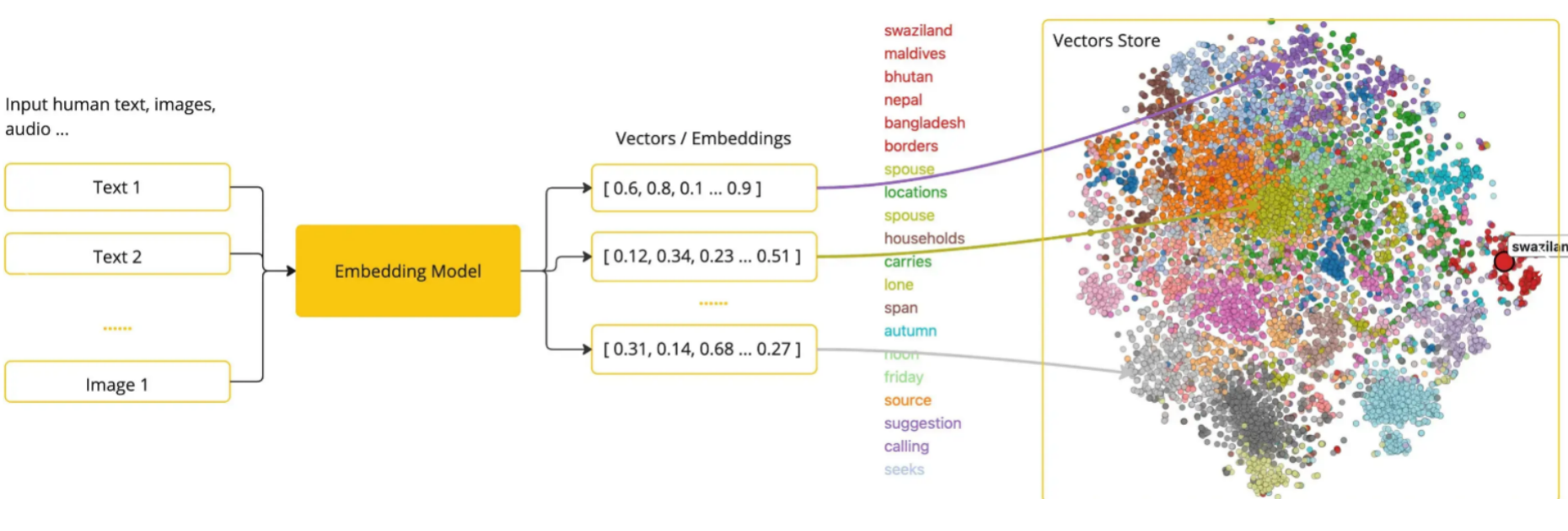
一句话概括
将文本转化为一组向量,向量会嵌入到一个分布图当中,距离越近,说明两者关联度越高。
2.向量空间(Vector Space)
所有的数据都变成向量,这些向量组成一个庞大的矩阵。在这个世界里,每个词、句子、图片、用户…都被表示成一个“点”(即向量),大家都有自己的“坐标”。距离表示相似度
向量之间越近:意义越相似
向量之间越远:意义越不同我们可以通过“距离”和“方向”来理解它们的关系。
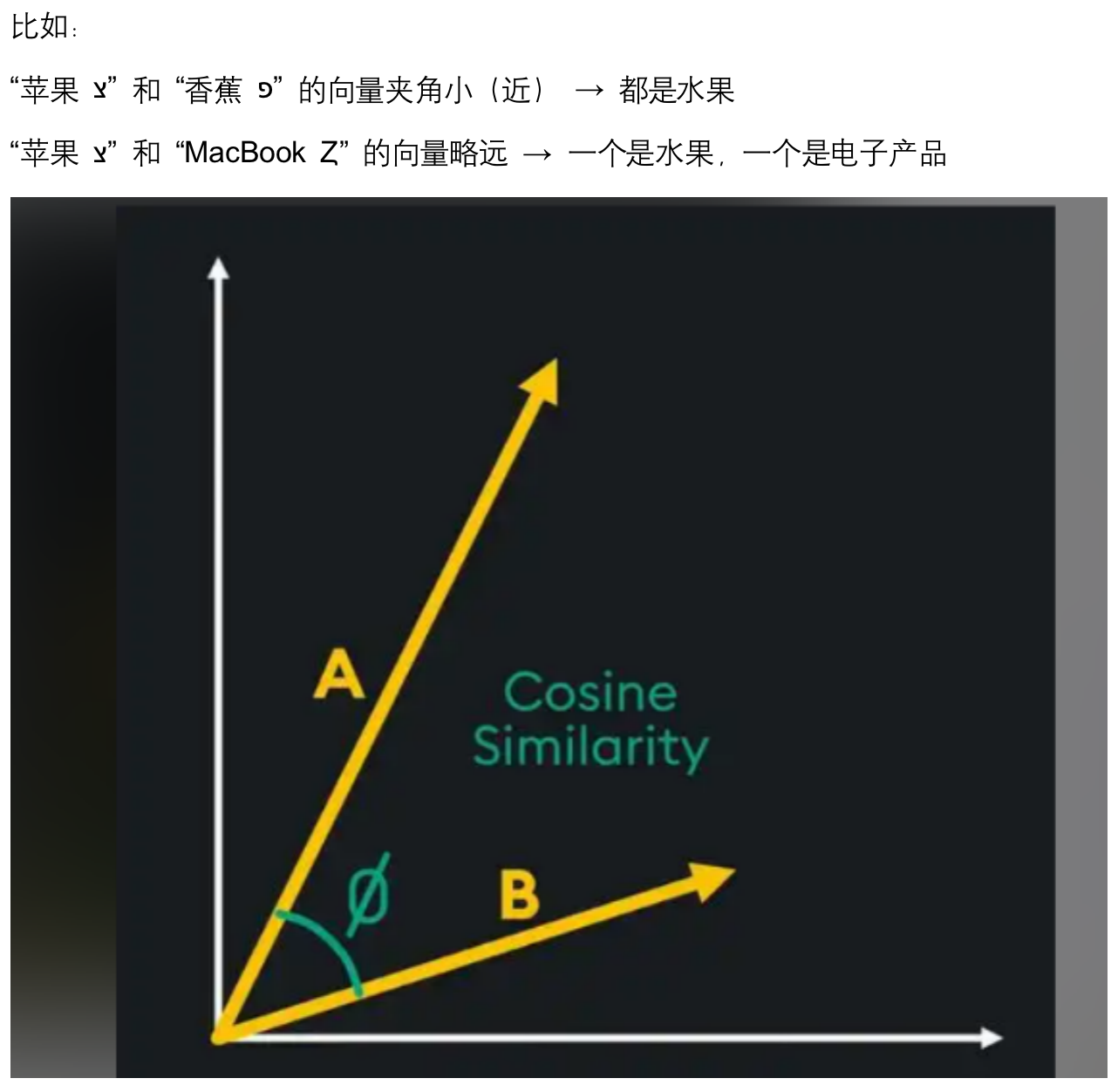
使用场景
向量空间能解决什么问题呢?
• 降维:在高维度空间中,数据点之间可能存在很大的距离,使得样本稀疏,嵌入模型可以减少数据稀疏性。
• 捕捉语义信息:Embedding不仅仅是降维,更重要的是,它能够捕捉到数据的语义信息。语义相近的词在向量上也是相近的
• 特征表示:原始数据的特征往往难以直接使用,通过嵌入模型可以将特征转换成更有意义的表示。
• 计算效率:在低维度空间中对数据进行处理和分析往往更加高效。
3.向量基础学习-深度理解什么是向量
# 1. 创建向量
print("\n【1. 创建向量】")
vector_a = np.array([1, 2, 3])
vector_b = np.array([4, 5, 6])
print(f"向量A: {vector_a}")
print(f"向量B: {vector_b}")
print(f"向量A的维度: {len(vector_a)}维")
output:
向量A: [1 2 3]
向量B: [4 5 6]
向量A的维度: 3维
# # 1. 创建向量
# print("\n【1. 创建向量】")
vector_a = np.array([1, 2, 3])
vector_b = np.array([4, 5, 6])
# 点积(重要!)
dot_product = np.dot(vector_a, vector_b)
print(f"A · B (点积) = {dot_product}")
print(f"计算过程: 1×4 + 2×5 + 3×6 = {1*4 + 2*5 + 3*6}")
# 3. 向量长度(模)
print("\n【3. 向量长度】")
length_a = np.linalg.norm(vector_a)
length_b = np.linalg.norm(vector_b)
#
print(f"向量A的长度: {length_a:.4f}")
print(f"计算过程: √(1² + 2² + 3²) = √{1**2 + 2**2 + 3**2} = {length_a:.4f}")
print(f"向量B的长度: {length_b:.4f}")
output:
向量A: [1 2 3]
向量B: [4 5 6]
A · B (点积) = 32
计算过程: 1×4 + 2×5 + 3×6 = 32
【3. 向量长度】
向量A的长度: 3.7417
计算过程: √(1² + 2² + 3²) = √14 = 3.7417
向量B的长度: 8.7750
计算相似度(余弦相似度)
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
#
# 模拟两个相似句子的向量
sentence1 = np.array([0.8, 0.6, 0.2, 0.1, 0.9]) # "今天天气不错"
sentence2 = np.array([0.75, 0.65, 0.15, 0.12, 0.85]) # "今天天气很好"
sentence3 = np.array([0.1, 0.2, 0.9, 0.8, 0.15]) # "Python是编程语言"
sim_1_2 = cosine_similarity(sentence1, sentence2)
sim_1_3 = cosine_similarity(sentence1, sentence3)
#
print(f"\n句子1和句子2的相似度: {sim_1_2:.4f} (很相似!)")
print(f"句子1和句子3的相似度: {sim_1_3:.4f} (不太相似)")
句子1和句子2的相似度: 0.9976 (很相似!)
句子1和句子3的相似度: 0.3536 (不太相似)
4.langchain的文本嵌入模型(Embeddings)
*嵌入模型创建文本片段的向量表示。您可以将向量视为一个数字数组,它捕捉了文本的语义含义。 通过这种方式表示文本,您可以执行数学运算,从而进行诸如搜索其他在意义上最相似的文本等操作。
Embeddings 类是一个与文本嵌入模型接口的类,有很多嵌入大模型供应商(OpenAI、Hugging Face,BGE 等)这个类为它们提供了一个标准接口
5.下面引入一个openaiEmbedding的案例
#导入 OpenAI 的 Embedding 工具
from langchain_openai import OpenAIEmbeddings
from openai import OpenAI
from env_utils import OPENAI_API_KEY, OPENAI_BASE_URL
# 初始化模型
openai_embeddings = OpenAIEmbeddings(
api_key=OPENAI_API_KEY,
base_url=OPENAI_BASE_URL,
model="text-embedding-3-large",
dimensions=256
)
# 关键参数说明:
#model="text-embedding-3-large" - OpenAI 最好的 Embedding 模型
#dimensions=256 - 重点! 把原本 3072 维压缩到 256 维
resp = openai_embeddings.embed_documents(
[
"I like large language models",
"今天天气非常不错"
]
)
print(resp[0])
print(len(resp[0]))
向量化文本
resp = openai_embeddings.embed_documents([
"I like large language models", # 英文文本
"今天天气非常不错" # 中文文本
])
发生了什么?
输入: 2个文本
↓
发送到 OpenAI API
↓
OpenAI 处理并返回向量
↓
输出: 2个向量(每个256维)
返回值结构:
resp = [
[0.123, -0.456, ..., 0.789], # 第1个文本的向量(256个数字)
[0.345, 0.678, ..., 0.234] # 第2个文本的向量(256个数字)
]
总的来说,embedding便是把文字转化为数字向量 这段代码用 OpenAI 的 API 把 2 个文本(英文+中文)转换成了 2 个 256 维的数字向量,用于后续的语义搜索或相似度计算。
传统搜索中:你输入“苹果”,只能匹配“水果”
向量搜索:你输入“苹果”,它可以将苹果转化为数字向量,并给你匹配到水果、ipone
6.私有化部署Qwen3-Embedding
为了部署Embedding模型,我们需要引入对应的工具库,目前主要有几类:
- Sentence-Transformers: Sentence-Transformers库是基于HuggingFace的Transformers库构建的,它专门设计用于生成句子级别的嵌入。它引入了一些特定的模型和池化技术,使得生成的嵌入能够更好地捕捉句子的语义信息。Sentence-Transformers库特别适合于需要计算句子相似度、进行语义搜索和挖掘同义词等任务。
- HuggingFace Transformers: HuggingFace的Transformers库是一个广泛使用的NLP库,它提供了多种预训练模型,如BERT、GPT-2、RoBERTa等。这些模型可以应用于各种NLP任务,如文本分类、命名实体识别、问答系统等。Transformers库支持多种编程语言,并且支持模型的微调和自定义模型的创建。虽然Transformers库的功能强大,但它主要关注于模型的使用,而不是直接提供句子级别的嵌入。
- Langchain集成的HuggingFaceBgeEmbeddings。与3一样。
- FlagEmbedding: 这是一个相对较新的库,其核心在于能够将任意文本映射到低维稠密向量空间,以便于后续的检索、分类、聚类或语义匹配等任务。FlagEmbedding的一大特色是它可以支持为大模型调用外部知识,这意味着它不仅可以处理纯文本数据,还能整合其他类型的信息源,如知识图谱等,以提供更丰富的语义表示。
总的来说,FlagEmbedding强调的是稠密向量的生成和外部知识的融合;HuggingFace Transformers提供了一个广泛的预训练模型集合,适用于多种NLP任务;而Sentence-Transformers则专注于生成高质量的句子嵌入,适合那些需要深入理解句子语义的应用场景。
from sentence_transformers import SentenceTransformer
# pip install sentence-transformers
# 引入Qwen3模型
qwen3_embedding = SentenceTransformer('Qwen/Qwen3-Embedding-0.6B')
resp = qwen3_embedding.encode(
[
"I like large language models",
"今天天气非常不错"
]
)
7.BGE-Large的Embadding+Huggingface私有化
- HuggingFace 上的 BGE 模型是最好的开源嵌入模型之一。 BGE 模型由北京人工智能研究院 (BAAI) 创建。 是一家从事 AI 研发的私营非营利组织
配置HuggingFace镜像站:https://hf-mirror.com/pip install --upgrade --quiet sentence_transformers
下面来看一个示例
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-small-zh-v1.5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
bge_hf_embedding = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
resp = bge_hf_embedding.embed_documents(
[
"I like large language models",
"今天天气非常不错"
]
)
print(resp[0])
print(len(resp[0]))
8.一个美食评论案例
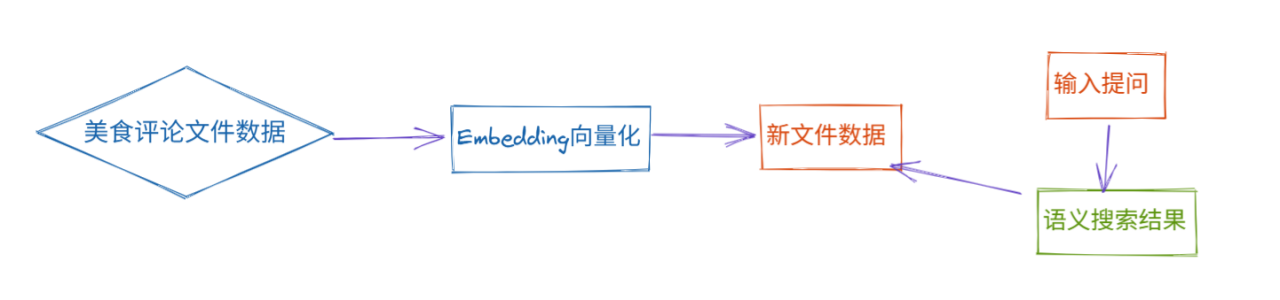
在开始这个案例之前,我们要先讲一下 余弦距离这个概念
- 余弦距离(Cosine Distance)的计算,用于衡量两个向量在方向上的相似性。代表 文本语义的相似性
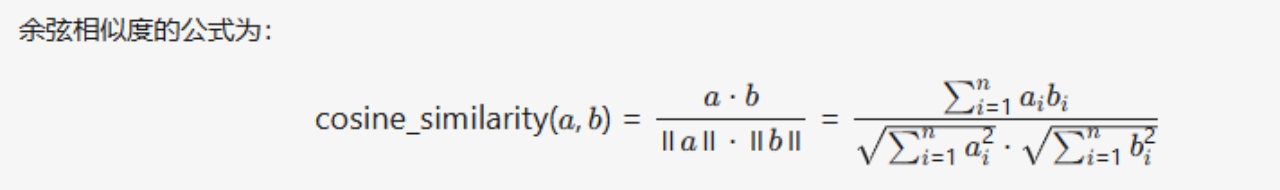
||a|| : 计算向量 a 的欧几里得范数(L2范数),即向量的长度。公式为 sqrt(a₁² + a₂² + ... + aₙ²)
ab: 计算向量 a 和 b 的点积(内积),即对应元素相乘后求和。
完整代码:
import ast
import pandas as pd
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
import numpy as np
model_name = "BAAI/bge-small-zh-v1.5" # 北京智源研究院开发的中文嵌入模型,专门用于将文本转换为向量。
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
# 初始化模型
bge_hf_embedding = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
# 将单个文本转化为向量
def text_2_embedding(text):
"""通过调用Embedding模型 得到向量"""
resp = bge_hf_embedding.embed_documents(
[text]
)
return resp[0]
def consine_distance(a,b):
return np.dot(a,b) / (np.linalg.norm(a) * np.linalg.norm(b))
def embedding_2_file(source_file,target_file):
"""读取原始的美食评论数据,通过调用Embedding模型 得到向量 并保存到新文件中"""
# 步骤1 准备数据 读取数据
df = pd.read_csv(source_file,index_col=0)
df = df[['Time','Summary','Text']]
# 步骤2 数据清洗 合并数据
# df = df.dropna()
# 评论的摘要和内容合并成一个字段 方便后续处理
df['text_content'] = 'Summary: ' + df.Summary.str.strip() + '; Text: ' + df.Text.str.strip() #
# 步骤3 向量化 存到一个新的文件中
df['embedding'] = df.text_content.apply(lambda x:text_2_embedding(x))
df.to_csv(target_file)
# Time Summary Text text_content embedding
# 2023-01-01 很好吃 菜品新鲜... Summary: 很好吃; Text: 菜品新鲜... [0.12, -0.45, ...]
# 2023-01-02 一般般 价格有点贵 Summary: 一般般; Text: 价格有点贵 [0.34, 0.67, ...]
def search_text(input,embedding_file,top_n=3):
"""
根据用户输入的问题进行语译检索,返回最相似的top n 结果
"""
df_data = pd.read_csv(embedding_file)
# 把字符串转化为向量
df_data['embedding_vector'] = df_data['embedding'].apply(ast.literal_eval)
# 将用户输入转换为向量
input_vector = text_2_embedding(input)
df_data['similarity'] = df_data.embedding_vector.apply(lambda x: consine_distance(x,input_vector))
res = (
df_data.sort_values("similarity",ascending=False)
.head(top_n)
.text_content.str.replace("Summary: ","")
.str.replace('; Text: ',';')
)
for r in res:
print(r)
print("-" * 30)
if __name__ == '__main__':
embedding_2_file('../datas/fine_food_reviews_1k.csv','../datas/output_embedding.csv')
search_text('buy coffee','../datas/output_embedding.csv')
9.向量数据库
储和搜索非结构化数据的最常见方法之一是将其嵌入并存储生成的嵌入向量, 然后在查询时嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。 向量存储负责存储嵌入数据并执行向量搜索, 为您处理这些。
什么是向量数据库:
传统的数据库主要处理结构化数据,而向量数据库则专注于处理非结构化数据经过嵌入模型(embedding model)转换而来的向量数据。这些向量是高维空间中的点,它们捕获了原始数据的语义信息。向量数据库的核心能力是进行相似性搜索,即根据查询向量找到最相似的向量,从而实现语义级别的搜索和匹配。
下面介绍一些常用的向量数据库
- Chroma 是一个开源的向量数据库,专注于简化文本嵌入的存储和检索过程。Chroma 采用 Apache 2.0 许可证。它的主要特点包括:
1.支持多种存储后端:Chroma支持多种底层存储选项,如DuckDB(适用于独立应用)和ClickHouse(适用于大规模扩展)。
2.多语言支持:Chroma提供了Python和JavaScript/TypeScript的SDK,方便开发者快速集成。
3.简单易用:Chroma的设计理念是“简单至上”,旨在提升开发者的效率。
4.高性能:Chroma不仅支持快速的相似度搜索,还提供了对搜索结果的分析功能。 - Faiss是由Facebook AI Research团队开发的一个库,旨在高效地进行大规模向量相似性搜索。它不仅支持CPU,还能利用GPU进行加速,非常适合处理大量高维数据。Faiss提供了多种索引类型,以适应不同的需求,从简单的平面索引(Flat Index)到更复杂的倒排文件索引(IVF)和乘积量化索引(PQ)。
- Milvus 由 Zilliz 开发,并捐赠给了 Linux 基金会下的 LF AI & Data 基金会,现已成为世界领先的开源向量数据库项目之一
•Milvus 采用 Apache 2.0 许可发布,大多数贡献者都是高性能计算(HPC)领域的专家,擅长构建大规模系统和优化硬件感知代码
Chroma向量数据库代码案例:
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
# 1.初始化模型
print("开始初始化模型...")
model_name = "BAAI/bge-small-zh-v1.5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
bge_hf_embedding = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
print("模型初始化完成!")
# 2.准备数据 Document对象
print("准备文档数据...")
#page_content: 实际文本内容(会被向量化)
# metadata: 附加信息(不会被向量化,但会保留在搜索结果中)
document_1 = Document(
page_content="今天早餐我吃了巧克力薄煎饼和炒鸡蛋",
metadata={"source": "tweet", "time": "上午"}
)
document_2 = Document(
page_content="今天天气不错",
metadata={"source": "news"}
)
document_3 = Document(
page_content="我有种不好的预感啊",
metadata={"source": "tweet"}
)
document_4 = Document(
page_content="Python是一门非常适合初学者的编程语言",
metadata={"source": "blog", "category": "技术"}
)
document_5 = Document(
page_content="这家餐厅的牛排做得太棒了,强烈推荐",
metadata={"source": "review", "rating": "5"}
)
document_6 = Document(
page_content="明天会下雨,记得带伞",
metadata={"source": "weather", "time": "下午"}
)
document_7 = Document(
page_content="刚看完一部很感人的电影,哭了好久",
metadata={"source": "tweet", "emotion": "sad"}
)
document_8 = Document(
page_content="LangChain是一个强大的AI应用开发框架",
metadata={"source": "documentation", "category": "技术"}
)
document_9 = Document(
page_content="周末打算去爬山,呼吸新鲜空气",
metadata={"source": "tweet", "time": "晚上"}
)
document_10 = Document(
page_content="股市今天大涨,投资者信心增强",
metadata={"source": "news", "category": "财经"}
)
documents = [
document_1, document_2, document_3, document_4, document_5,
document_6, document_7, document_8, document_9, document_10
]
# 3.创建向量数据库并添加文档
print(f"创建Chroma向量数据库并添加 {len(documents)} 个文档...")
vector_store = Chroma.from_documents(
documents=documents, # 要存储的文件列表
embedding=bge_hf_embedding, # 使用的嵌入模型
collection_name="my_collection" # 类似表名
)
vector_store.s
print("文档添加完成!")
# ID | 向量 | 原始文档 | 元数据
# 1 | [0.12, -0.34, ...] | "今天早餐..." | {source: "tweet"}
# 2 | [0.23, 0.45, ...] | "今天天气不错" | {source: "news"}
# 4.相似度搜索
print("\n开始相似度搜索:'今天的投资建议'")
results = vector_store.similarity_search("今天的投资建议", k=2)
print(f"\n找到 {len(results)} 个最相似的结果:\n")
for i, res in enumerate(results, 1):
print(f"结果 {i}:")
print(f" 内容: {res.page_content}")
print(f" 元数据: {res.metadata}")
print()
# 5.带分数的相似度搜索
print("\n带相似度分数的搜索:")
# results_with_scores = vector_store.similarity_search_with_score("周末干什么", k=3)
#
# for i, (doc, score) in enumerate(results_with_scores, 1):
# print(f"结果 {i} (相似度分数: {score:.4f}):")
# print(f" 内容: {doc.page_content}")
# print(f" 元数据: {doc.metadata}")
# print()
二、RAG
1.什么是RAG
我们在很多场景下或多或少都听过RAG这个词,那究竟是什么rag呢。
RAG全称** Retrieval-Augmented Generation **检索增强生成,通过结合LLMs的内在知识和外部数据库的非参数化数据,提高了模型在知识密集型任务中的准确性和可信度。
就是说,我们一般使用的大模型,deepseek或者chatgpt都是比较大而全的,但是针对公司具体的业务,会显得有些泛滥,这时候继就需要通过RAG检索增强生成来达到这个要求。
RAG的过程
我们看下面的图,RAG是怎样一个过程

- 首先对于企业来说,都会有自己公司的文档,知识库,可以是文本,图片,csv等等,首先会通过提取,切片,更精准的提取出关键信息,通过将关键信息,向量化,生成我们的向量模型,再通过向量数据库来进行数据的存储。用户拿原始问题经过向量化之后,与向量数据库的数据进行相似度匹配,提取有关问题的最近结果的k个切片,将原始问题和检索到的chunk压缩组合提示词输如人给大模型,来得到我们想要的结果,这就是RAG的过程。
熟悉dify的知道,好像dify的知识库切片就是干这个的,但是图形化dify的操作准确度,自由操作度会很受限。
下面我们来做一个案例来感受RAG的用法,这是一个带对话历史记忆的 RAG(检索增强生成)系统,让我逐块详细解释:
1.导入依赖
2.初始化核心组件
# 加载自定义的 Qwen3 嵌入模型
qwen3_embedding = CustomQwen3Embeddings("Qwen/Qwen3-Embedding-0.6B")
# 构建向量数据库(持久化到本地)
vector_store = Chroma(
embedding_function=qwen3_embedding, # 使用 Qwen3 做文本向量化
collection_name="t_agent_blog", # 集合名称
persist_directory="../chroma_db" # 数据持久化目录
)
注解:
qwen3_embedding:将文本转换为向量(768维)
vector_store:存储文档向量,支持相似度检索
3.数据准备函数 爬虫+数据存储
def create_dense_db():
"""把网络上关于Agent博客数据写入向量数据库"""
# 1. 加载网页内容
loader = WebBaseLoader(
web_path=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
# 只解析特定部分(提高效率)
parse_only=bs4.SoupStrainer(
"div", class_=("post-content", "post-title", "post-header")
)
)
)
docs_list = loader.load() # 返回 Document 对象列表
# 2. 文本切割(长文档切成小块)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块最多1000字符
chunk_overlap=200 # 块之间重叠200字符(保持上下文连贯)
)
splits = text_splitter.split_documents(docs_list)
# 3. 写入向量数据库
ids = ['id' + str(i + 1) for i in range(len(splits))]
vector_store.add_documents(documents=splits, ids=ids)
从网页抓取 AI Agent 相关博客
切割成小块(避免单个文档太长)
向量化后存入 Chroma 数据库
4.历史感知检索器(核心1)上面都好理解 关键是这一步 这是 RAG 系统中最关键的部分,解决了多轮对话中的指代消解问题。让我深入展开:
4.1 定义上下文感知提示词
核心问题:为什么需要历史感知?
我们来看一个场景示例:
# 第一轮对话
用户: "什么是任务分解?"
AI: "任务分解是将复杂任务拆解为简单子任务的过程..."
# 第二轮对话
用户: "有哪些常见方法?" # ← 问题来了!
问题分析:
❌ 直接用 "有哪些常见方法?" 去向量数据库检索 → 检索不到相关内容
✅ 需要改写为 "任务分解有哪些常见方法?" → 检索成功
这就是历史感知检索器要解决的核心问题!
contextualize_q_system_prompt = (
"给定聊天历史和最新的用户问题(可能引用聊天历史中的上下文),"
"将其重新表述为独立问题(不需要聊天历史也能理解)。"
"不要回答问题,只需要在需要时重新表述问题,否则保持原样。"
)
作用: 将依赖上下文的问题改写为独立问题
示例:
用户第一轮:"什么是任务分解?"
用户第二轮:"有哪些常见方法?" ← 这个问题依赖历史
LLM 改写为:"任务分解有哪些常见方法?" ← 独立问题
创建提示词模板 作用就是问题改写
contextualize_q_prompt = ChatPromptTemplate.from_messages([
("system", contextualize_q_system_prompt), # 系统指令
MessagesPlaceholder("chat_history"), # 历史消息占位符
("human", "{input}"), # 用户当前输入
])
4.3 创建检索器
# 普通检索器(从向量数据库检索相关文档)
retriever = vector_store.as_retriever(search_kwargs={"k": 2}) # 返回最相关的2个文档
# 历史感知检索器(先改写问题,再检索)
history_aware_retriever = create_history_aware_retriever(
llm, # 大语言模型(用于改写问题)
retriever, # 普通检索器
contextualize_q_prompt # 改写问题的提示词
)
- RAG 问答链(核心2)
5.1 定义QA提示词
qa_prompt_text = (
"你是一个问答任务助手。"
"使用以下检索到的上下文来回答问题"
"如果你不知道答案,就说你不知道"
"回答最多三句话,保持简洁"
"\n\n"
"{context}" # 从向量数据库检索到的上下文
)
qa_prompt = ChatPromptTemplate.from_messages([
("system", qa_prompt_text),
MessagesPlaceholder("chat_history"), # 历史对话
("human", "{input}"), # 用户问题
])
- 会话历史管理
- 实际调用
完整代码
import bs4
from langchain_classic.chains.combine_documents import create_stuff_documents_chain
from langchain_classic.chains.history_aware_retriever import create_history_aware_retriever
from langchain_classic.chains.retrieval import create_retrieval_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_text_splitters import RecursiveCharacterTextSplitter
from onnxruntime.transformers.models.stable_diffusion.benchmark import warmup_prompts
from embeddings_demo.custom_embedding import CustomQwen3Embeddings
from langchain_demo.my_llm import llm
# 加载向量模型
qwen3_embedding = CustomQwen3Embeddings("Qwen/Qwen3-Embedding-0.6B")
# 构建向量数据库
vector_store = Chroma(
embedding_function=qwen3_embedding,
collection_name="t_agent_blog",
persist_directory="../chroma_db"
)
# 爬取知识库加入数据库
def create_dense_db():
"""把网络上关于Agent博客数据写入向量数据库"""
# 加载网页 网页加载器
loader = WebBaseLoader(
web_path = ("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
# pip install beautifulsoup4
parse_only=bs4.SoupStrainer(# 只解析特定部分(提高效率) 只保留特定的部分
"div", class_=("post-content", "post-title", "post-header")
)
)
)
docs_list = loader.load()
# 切割
# 初始化文本分割器,设置块大小1000 重叠200
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) # 将原始文档 分割成几部分
splits = text_splitter.split_documents(docs_list)
# 把doc写到向量数据库
ids = ['id' + str(i + 1) for i in range(len(splits))]
vector_store.add_documents(documents=splits,ids=ids)
# 上下文感知模版 用于将聊天历史问题转化为独立问题
contextualize_q_system_prompt = (
"给定聊天历史和最新的用户问题(可能引用聊天历史中的上下文),"
"将其重新表述为独立问题(不需要聊天历史也能理解)。"
"不要回答问题,只需要在需要时重新表述问题,否则保持原样。"
)
# 创建聊天提示词模版
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
# 普通检索器(从向量数据库检索相关文档)
retriever = vector_store.as_retriever(search_kwargs={"k": 2}) # 返回最相关的2个文档
# 历史感知检索器(先改写问题,再检索)
history_aware_retriever = create_history_aware_retriever(
llm, # 大语言模型(用于改写问题)
retriever, # 普通检索器
contextualize_q_prompt # 改写问题的提示词
)
# 工作流程:
#
# 接收用户问题 + 历史对话
# LLM 将问题改写为独立问题
# 用独立问题去向量数据库检索
# 返回相关文档
# 历史感知检索器 (上一部分) │
# │ ✓ 改写问题 │
# │ ✓ 检索文档 │
# │ ✗ 不生成答案 │
# │ ✗ 不管理历史
# ---------------------------------------------------
# RAG代码
# 系统提示词,定义助手的行为和回答规范
qa_prompt_text = (
"你是一个问答任务助手。"
"使用以下检索到的上下文来回答问题"
"如果你不知道答案,就说你不知道"
"回答最多三句话,保持简洁"
"\n\n"
"{context}" # 从向量数据库当中检索出上下文
)
# 创建QA提示词模板
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_prompt_text),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
# 创建文档处理链
question_chain = create_stuff_documents_chain(llm, qa_prompt)
# 创建RAG链
rag_chain = create_retrieval_chain(history_aware_retriever, question_chain)
# 存储聊天记录 : (内存,关系型数据库或者redis数据库)
store = {}
# 获取当前会话的聊天记录
def get_session_history(session_id):
"""从内存中的历史消息列表中 返回当前会话的所有历史消息"""
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory() # 如果是新用户,创建一个空的历史记录对象
return store[session_id] # 无论是新用户还是老用户,都返回历史记录对象
return store[session_id] # 无论是新用户还是老用户,都返回历史记录对象
#
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain, # 参数1:要包装的链
get_session_history, # 参数2:获取历史的函数
input_messages_key="input", # 参数3:告诉它用户输入在哪个key
history_messages_key="chat_history", # 参数4:告诉它历史记录要放在哪个key
output_messages_key="answer", # 输出结果方便
)
# 调用会话RAG链,询问什么是任务分解
# RAG 问答链 (本部分) │
# │ ✓ 生成答案 (question_chain) │
# │ ✓ 利用历史保持对话连贯 │
# │ ✓ 自动管理历史 (RunnableWithMessageHistory) │
# │ ✓ 多用户隔离 (session_id)
resp1 = conversational_rag_chain.invoke(
{"input":"what is Task Decomposition?"},
config = {
"configurable":{"session_id":"abc123"} # 使用会话idabc123
}
)
print(resp1["answer"])
# 调用会话RAG链,询问什么是任务分解
resp2 = conversational_rag_chain.invoke(
{"input":"Types of Memory"},
config = {
"configurable":{"session_id":"abc123"} # 使用会话idabc123
}
)
print(resp2["answer"])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号