

Redis(十一)——集群模式
1、概念
集群是Redis的分布式方案,通过分片来进行数据共享,并提供复制和故障转移功能。
主从模式的读写分离提高了读并发,但是写的上限还是一台redis服务器,集群模式则可以提高写能力。
2、启动集群节点
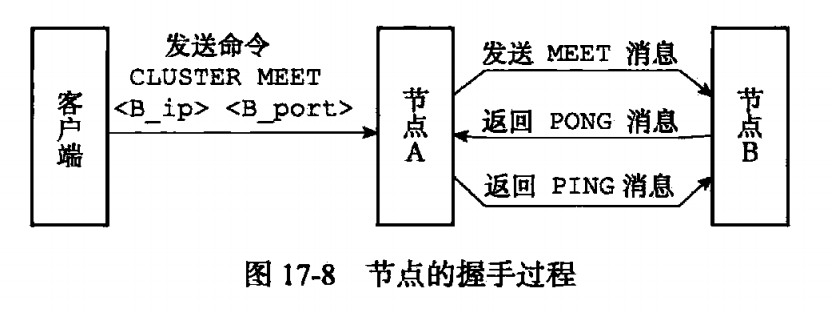
Redis服务器启动时根据cluster-enabled配置选择开启后作为单机模式还是集群模式。集群模式下,一开始各个服务器节点相互独立,通过命令连接形成集群。A节点向B节点发送命令【cluster meet <ip> <port>】进行握手,这里的ip+port是B节点的。
3、集群数据结构
(1)clusterNode表示一个节点的各种基本信息,包括创建时间、地址、端口、配置纪元、名字、所连的节点等信息,属性【clusterLink* link】表示所连的节点。
typedef struct clusterNode{ //创建节点的时间 mstime_t ctime; //节点名字,40个十六进制符 char name[40]; //各种标识,主从节点、上线下线 int flags; //配置纪元,用于故障转移 unit64_t configEpoch; //ip地址 char ip[REDIS_IP_STR_LEN]; //端口 int port; //保存连接节点所需的有关信息 clusterLink* link; //哪些槽归自己处理 unsigned char slots[16384/8]; //本节点处理多少个槽 int numslots; //... } clusterNode;
(2)clusterLink保存了连接节点所需的有关信息,其中缓冲区是给节点用的,而不是客户端。
typedef struct clusterLink{ //创建连接的时间 mstime_t ctime; //TCP套接字描述符 int fd; //输出缓冲区,保存要发给其他节点的信息 sds sndbuf; //输入缓冲区,保存从其他节点接收到的信息 sds rcvbuf; //连接关联的节点,没有则设空 struct clusterNode* node; }clusterLink;
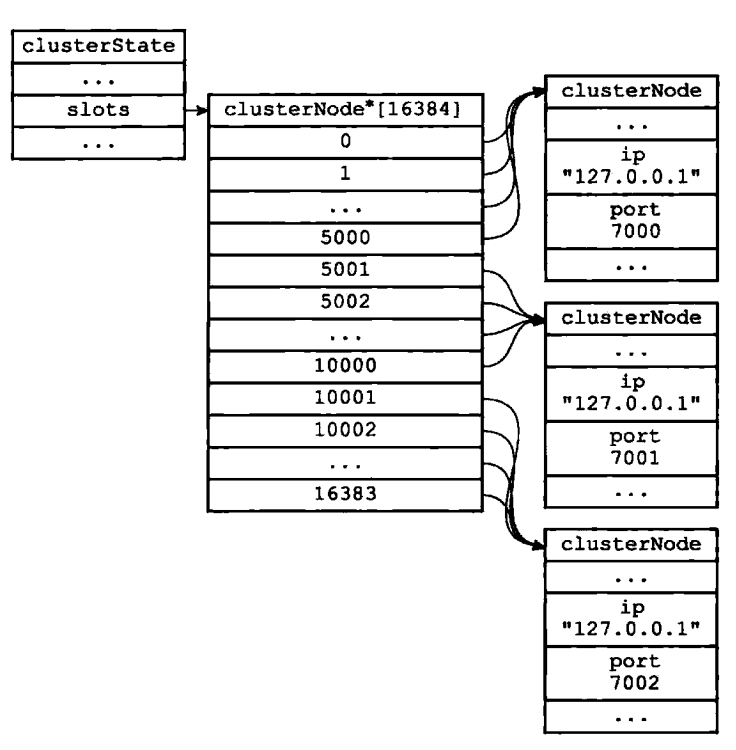
(3)clusterState是每个节点都会有的结构,记录的是集群信息,nodes字典包含了全部的节点。
typedef struct clusterState{ //指向当前节点的指针 clusterNode* myself; //配置纪元 unit64_t currentEpoch; //集群状态 int state; //集群中至少处理一个槽的节点数量 int size; //集群节点名单,key为节点名,val为clusterNode结构 dict* nodes; //每个槽都归哪个节点管? clusterNode *slots[16384]; //... }clusterState;
4、握手过程
A将B添加到自己的clusterState.nodes字典里,然后给B发meet消息;
B接收A的消息,添加A到自己的clusterState.nodes字典里,返回一个pong消息;
A再回一条ping消息,握手成功。
5、槽
Redis集群通过分片来保存键值对,整个数据库被分为16384个槽(slot),每个节点处理0-16384个槽,全部槽都有节点处理时集群才处于上线状态(ok),否则处于下线状态(fail)。
(1)槽数据结构
单个节点clusterNode有属性记录自己负责处理哪些槽,并且会群发给其他集群节点,每个节点都知道各个槽都归谁管。
unsigned char slots[16384/8];//二进制位数组,1表示处理,0表示不处理
int numslots;//本节点负责的槽点数量

集群clusterState纪录各个槽都归谁管。
clusterNode* slots[16384];//要么指向NULL,要么指向节点
clusterNode和clusterState都有slots数组设计巧妙,缺一不可。
- 缺少clusterNode.slots:想知道某个节点处理的槽:需要遍历clusterState.slots。
- 缺少clusterState.slots:想知道某个槽归谁管:需要遍历clusterState.nodes字典,遍历每个clusterNode.slots进行判断。
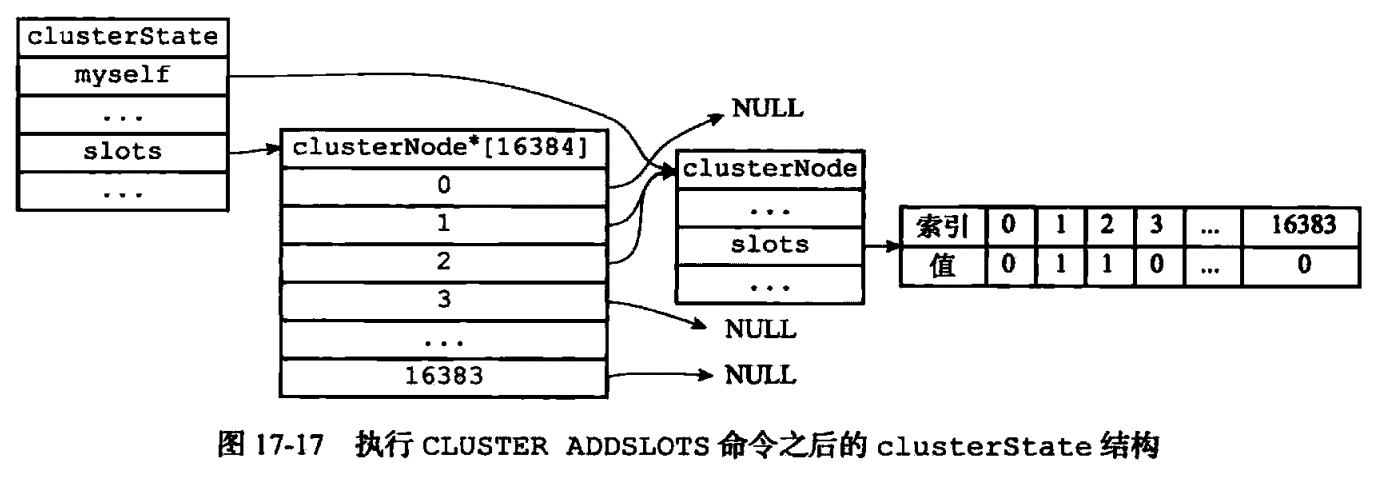
(2)槽指派(分片)
通过命令【cluster addslots <slot> [slot ...]】,例如【cluster addslots 1 2】。
如果指派的槽只要有一个被指派过了则返回错误,因此该命令不会覆盖,重新指派槽有其他操作。设置完clusterState.slots和clusterNode.slots之后,会群发告知其他节点哪些槽归我管。
(3)计算键属于哪个槽
CRC16(key)&16383
(4)维护槽和key的关系
clusterState.slots_to_key是个跳跃表,分值score是槽号。
(5)重新分片
重新指派槽操作是由redis的集群管理软件redis-trib负责执行的,单个槽迁移距离:节点A要往B迁移槽100的健值对。
- 1)通知B准备好从A接入数据 「cluster setslot 100 importing A.id」
- 2)通知A准备好迁出数据给B 「cluster setslot 100 migrating B.id」
- 3)找A获取最多count个槽100的键名 「cluster getkeysinslot 100 count」
- 4)步骤3获取的每个键名都向B发送命令迁移数据 「migrate B.id B.port key 0 timeout」
- 5)重复执行步骤3和步骤4,直到所有属于槽100的键都迁移完成
- 6)随便找个节点通知槽100已经指派给节点B cluster setslot 100 node B.id

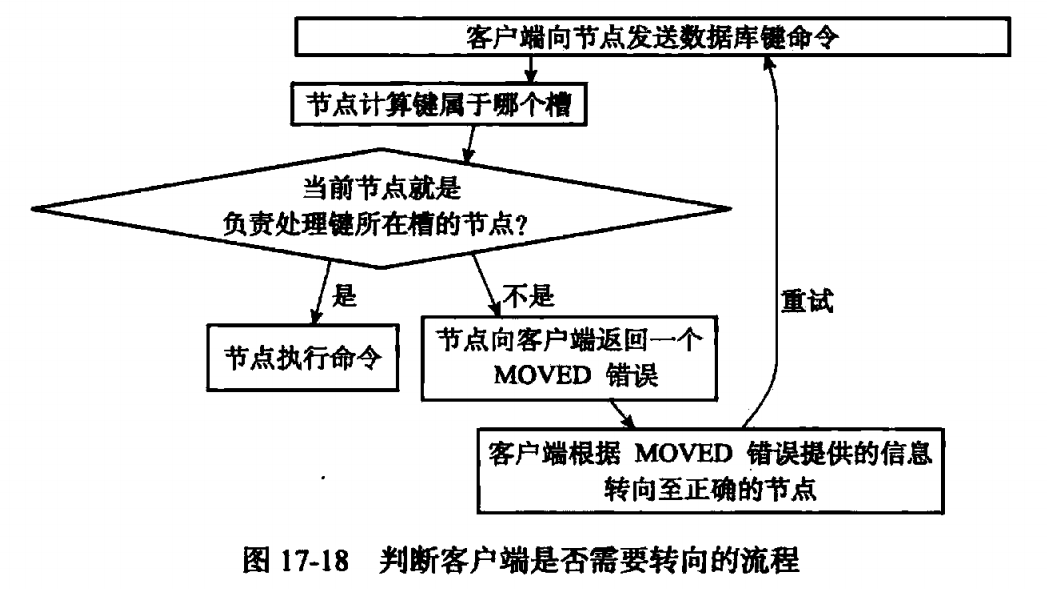
(6)MOVE错误
向节点A操作key=name的键,节点A发现这个key所在的槽归节点B管,集群模式会隐藏错误,自动重定向B,执行客户端的命令,返回客户端的结果会提示重定向的节点。MOVE错误的解决是永久的,下次客户端要操作key=name的键就直接去找B了。
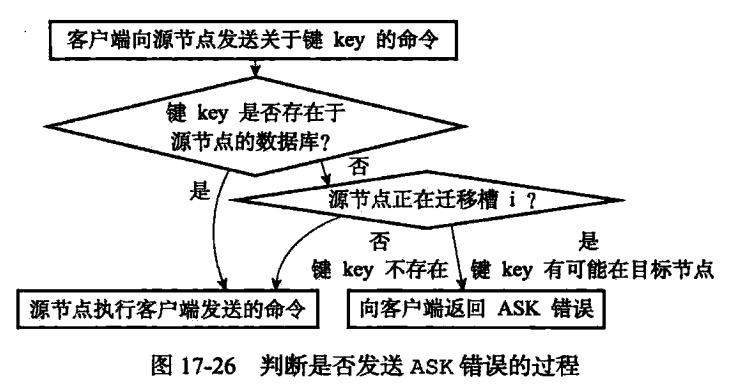
(7)ASK错误
发生在槽迁移的过程中,类似MOVE错误,会隐藏错误且自动重定向。但是ASK错误的解决是一次性的,下次客户端还是找A节点操作。
6、故障检测
集群节点之间会有心跳检测,如果超过半数的主节点都认为A下线了,则A会被标记为「已下线」,并广播通知。
7、故障转移
和主从模式差不多,选出新节点,新的主节点会把槽都指派给自己,广播通知:「老子上位了,这些槽都归老子管」
8、新增一个节点会发生什么?
- 先将该节点加入到集群中,与各个节点建立连接。此时新节点并不处理槽。
- 集群重分配:对集群与新节点重新分配槽,使各个节点处理的槽数量尽可能相同。
- 数据迁移:将原节点的槽数据迁移到新节点上,迁移完成后就可以承载读写负载。
- 客户端重新定位:客户端查询key会打到新的节点上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号