

face detection[Multi-view face detection&& MTCNN]
MTCNN
0 引言
MTCNN的灵感来自《A convolutional neural network cascade for face detection》,凯鹏认为,
- 该作者卷积层中的滤波器缺少多样化限制了模型的判别能力;
- 相比其他多累目标检测和分类任务,人脸检测就是一个极具挑战的二分类任务,所以每一层需要更少数量的滤波器。
所以凯鹏减少了滤波器的个数,并将5x5的大小变成3x3的大小,然后加深了网络的通道数量。
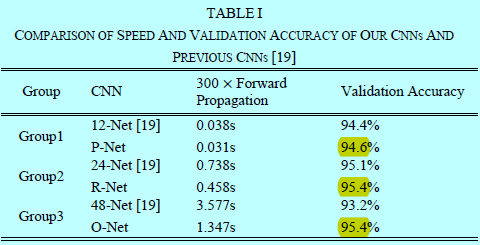
上图就是MTCNN的网络层与级联CNN的网络层的对比。
MTCNN主要贡献就是一个框架可以同时预测人脸区域并且同时预测人脸关键点,且能够在线进行硬样本的挖掘,从而提升性能。通过采用多任务学习将级联CNN进行统一起来,该提出的CNN框架中包含三个阶段:
- 通过一个浅层CNN快速的生成候选框;
- 然后通过一个更复杂的CNN拒绝大量的非人脸框;
- 最后使用一个更强劲的CNN去再次调整结果,并输出5个关键点位置。
1 结构
这里我们先给出MTCNN的操作流程图和对应的网络结构图

图1.1 MTCNN操作流程图
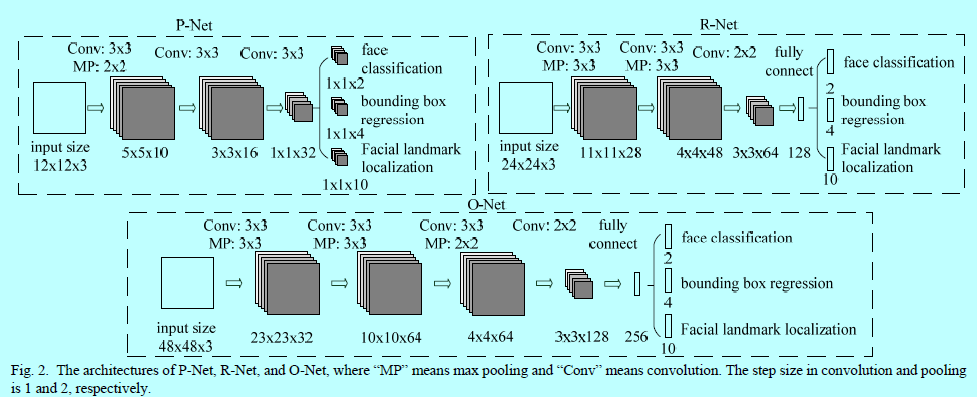
图1.2 MTCNN的网络结构图
如图1.1所示,给定一张图片,先对图片进行金字塔构建,保证整个网络结构的尺度不变性。
- 阶段1:利用一个全卷积网络,叫做proposal network(P-net),用于获取候选人脸窗口和他们的框回归向量。然后通过估计的边界框回归向量对候选框进行校正。然后用NMS来融合高度重叠的候选框。
- 阶段2:所有的候选框被送入另一个CNN中,叫做Refine Network(R-Net),该网络可以拒绝大量的假候选框,基于边界框回归进行校正,并执行NMS;
- 阶段3:该阶段相似于第二个阶段,但是在该阶段中,我们通过更多的有监督信息去识别人脸区域,最后,该网络会输出5个人脸关键点位置。
2 训练过程
MTCNN用了三个任务去训练整个CNN检测器:
- 是否是人脸的分类;
- 边界框的回归;
- 人脸关键点的定位。
2.1 人脸分类
这是一个二分类问题,那么采用交叉熵loss:
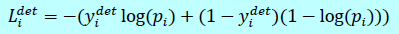
这里\(p_i\)是网络预测\(x_i\)是人脸的概率,其中\(y_j^{det}\in {0,1}\)是ground-truth
2.2 边界框回归
对每个候选框,都预测基于最近的ground truth的偏移量(边界框的【左上角的坐标,宽,高】四个量),这是一个回归问题,使用欧式距离:
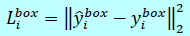
其中\(\hat y_j^{box}\)是网络预测的结果;\(y_i^{box}\)是ground-truth;
2.3 人脸关键点定位
和边界框回归任务一样,采用欧式距离进行回归

这里\(\hat y_i^{landmark}\)是人脸关键点的预测值;\(y_i^{landmark}\)是ground truth。
2.4 多源训练
因为在每个CNN中有不同的任务存在,所以这里在学习过程中也有不同类型的训练样本,比如人脸,非人脸,半对齐的人脸等等。这种情况下,上面三个公式在某些情况下就不能完全使用,比如对背景区域采用上,就只启动\(L_i^{det}\),并直接将其他两个loss置0。这是通过采用类型指示器完成的,如果将上述三个loss函数统一起来,就瑞下图:

这里\(N\)是样本个数,\(\alpha_j\)表示任务重要程度,这里使用的值是:
- 在P-net和R-net中:\(\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=0.5\);
- 在O-net中:\(\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=1\)
其中\(\beta_j^j\in {0,1}\)是采样类型指示器。
2.5 在线硬样本挖掘
不同于传统的,基于原始分类器训练后的硬样本挖掘,这里使用的是在线硬样本挖掘。在每个mini-batch中,先基于所有样本前向一次,并计算loss值,然后进行排序,选择前70%的作为硬样本。这样只需要计算这部分硬样本的BP,不需要计算所有样本的BP。其内在含义就是,如果loss值小意味着当前样本拟合的不错了,就不需要训练了,主要就是关注分类严重错误的那些样本。
我们这里比较关心,通过图像金字塔对原图进行缩放之后,是如何经过整个Pnet,Rnet和Onet的,有两种方法:
- 图像金字塔只经过Pnet,然后进行融合结果;
- 每一个尺度的图像经过所有三个网络,然后最后再做结果融合。
这里我们调试了下pangyupo/mxnet_mtcnn_face_detection的代码。



从上图可以知道,首先计算多个缩放因子,然后一个缩放因子对应一个进程进行处理,最后将结果通过除以缩放因子,将结果还原到scale=1的原图空间中。即图像金字塔只存在于Pnet过程中。
# https://github.com/pangyupo/mxnet_mtcnn_face_detection/blob/master/helper.py
def generate_bbox(map, reg, scale, threshold):
"""
generate bbox from feature map
Parameters:
----------
map: numpy array , n x m x 1
detect score for each position
reg: numpy array , n x m x 4
bbox
scale: float number
scale of this detection
threshold: float number
detect threshold
Returns:
-------
bbox array
"""
stride = 2
cellsize = 12
t_index = np.where(map>threshold)
# find nothing
if t_index[0].size == 0:
return np.array([])
dx1, dy1, dx2, dy2 = [reg[0, i, t_index[0], t_index[1]] for i in range(4)]
reg = np.array([dx1, dy1, dx2, dy2])
score = map[t_index[0], t_index[1]]
# 获取当前结果之后,通过下面的除以scale,将结果映射回scale=1的原图中。
boundingbox = np.vstack([np.round((stride*t_index[1]+1)/scale),
np.round((stride*t_index[0]+1)/scale),
np.round((stride*t_index[1]+1+cellsize)/scale),
np.round((stride*t_index[0]+1+cellsize)/scale),
score,
reg])
return boundingbox.T
def detect_first_stage(img, net, scale, threshold):
"""
run PNet for first stage
Parameters:
----------
img: numpy array, bgr order
input image
scale: float number
how much should the input image scale
net: PNet
worker
Returns:
-------
total_boxes : bboxes
"""
height, width, _ = img.shape
hs = int(math.ceil(height * scale))
ws = int(math.ceil(width * scale))
im_data = cv2.resize(img, (ws,hs)) # 基于缩放因子对图片进行缩放
# adjust for the network input
input_buf = adjust_input(im_data)
output = net.predict(input_buf) # 获取PNet网络的输出
'''添加如下代码
print(f'len(output):{len(output)} output[0].shape:{output[0].shape} output[1].shape:{output[1].shape}')
输出结果为(下面为4个进程的输出结果,对应4个不同的缩放因子):
# 第一个结果中的32 61 表示的是对应的划框map中的结果,即此缩放因子下一共有31x61个划框
len(output):2 output[0].shape:(1, 4, 32, 61) output[1].shape:(1, 2, 32, 61)
len(output):2 output[0].shape:(1, 4, 48, 88) output[1].shape:(1, 2, 48, 88)
len(output):2 output[0].shape:(1, 4, 69, 126) output[1].shape:(1, 2, 69, 126)
len(output):2 output[0].shape:(1, 4, 99, 179) output[1].shape:(1, 2, 99, 179)
通过shape的数量可以判定,P-Net只输出【边界框的四个预测值;是否有人脸的两个预测值】,并不输出对应的人脸关键点位置
然后通过下面的generate_bbox函数,带上缩放因子统一的将每个缩放因子结果再映射回原图中,从而完成图像金字塔的结果融合
'''
boxes = generate_bbox(output[1][0,1,:,:], output[0], scale, threshold)
if boxes.size == 0:
return None
# nms
pick = nms(boxes[:,0:5], 0.5, mode='Union')
boxes = boxes[pick]
return boxes
def detect_first_stage_warpper( args ):
return detect_first_stage(*args)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号