

face recognition[翻译][深度人脸识别:综述]
这里翻译下《Deep face recognition: a survey v4》.
1 引言
由于它的非侵入性和自然特征,人脸识别已经成为身份识别中重要的生物认证技术,也已经应用到许多领域,如军事,进入,公共安全和日常生活。FR自然在CVPR会议中也占据了十分长的时间。早在1990年代,随着特征脸的提出[157],FR就成为了一个比较热门的研究领域。过去基于特征进行FR的里程碑方法在图1中有所展示
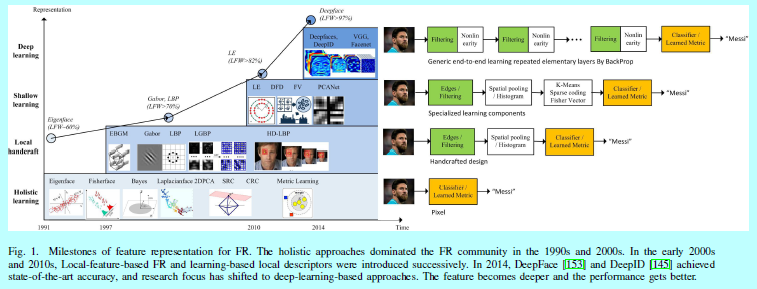
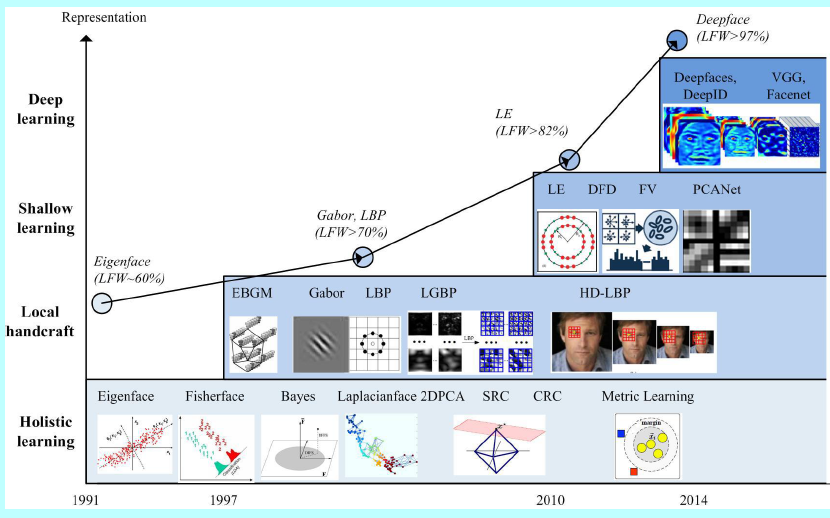
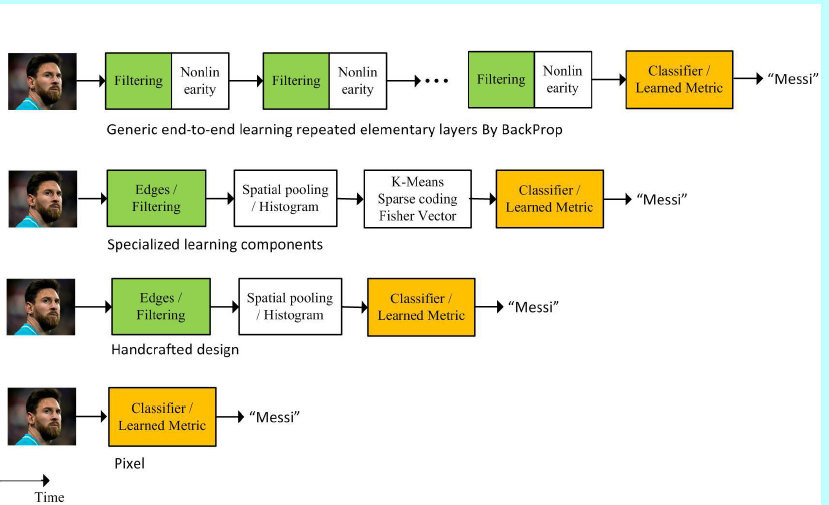
如图1所示,其中介绍了4个主流技术的发展过程:
- holistic 方法:通过某种分布假设去直接获取低维度的表征,如线性子空间[13,14,111],流行[43,67,191],稀疏表示[40,42,176,212]。该思想在1990年代占据了主流,直到2000年左右。然而,一个众所周知的问题就是这些理论可解释性的整体方法往往无法处理无约束下的人脸变化,因为它们都是来自预先假设的分布。
- 在2000年代,该问题转化成了基于局部特征的FR,Gabor[98],LBP[5]还有它们的多级别和高维度的扩展版本[26,41,213]。基于局部过滤的方式,在一些不变性要求上获得了较为鲁棒的性能。可是,手工设计的特征缺少特异性和紧凑性。
- 在2010年代早期,人们又提出了基于学习的局部描述子方法[21,22,89],其中局部滤波器都是通过学习得到的,从而有了更好的特异性,而且编码的编码本也让特征具有更好的紧凑性。然而这些浅层表征仍然有着不可避免的限制,它们对于复杂的非线性人脸外观变化的鲁棒性并不好。
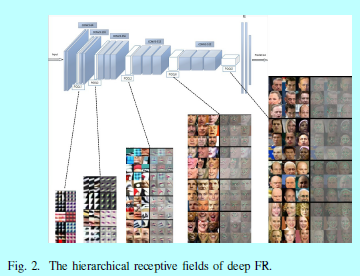
- 浅层方法试图通过一层或者2层表征学习来完成FR问题,而深度学习方法是用一个非线性处理单元的多层级联去进行特征提取和变换。它们学到的多层表征可以对应不同层级的抽取。这些层级构成了概念的层次结构,显示了在复杂数据集上的超越特征不变性,如图2所示。
在2014年,DeepFace[153]和DeepID[145]在LFW[74]数据集上获得了最好的效果,首次在无约束场景下超越人类。从这以后,研究者们就开始将研究目光转向了深度学习的方法。FR不同于通用的目标分类任务[88],因为人脸天然的特殊性:
- 类间差别不大,因为大家脸都长得差不多;
- 类内差别很大,同一个人在不同的姿态,光照,表情,年龄,和遮挡下有着十分巨大的变化。
这些挑战激发了许多新颖的结构和损失函数,从而提升了深度模型的判别性和泛化性。同时,越来越大的人脸数据集和更多人脸处理方法被提出。
正是因为大量的训练数据和GPU的普及,在近五年中,深度FR技术在学术benchmark数据集上不断的刷新之前的记录,而且随后在真实世界中也有不少的应用落地。在近些年,也有不少基于FR[3,18,78,136,222]和它的子领域综述,如光照不变性FR[234],3D FR[136],姿态不变FR[216]等等。然而这些综述都只覆盖了浅层FR的方法,在本文中,作者关注最新的基于深度特征学习的FR进展,还有对应的数据集的发展,人类处理方式和人脸匹配的发展等等。人脸检测和人脸对齐超出了本文的讨论范围,可以看Ranjan的工作[123],其对完整的深度FR流程有简洁的介绍。具体的,本文的贡献如下:
- 是一个关于深度FR上网络结构和损失函数的系统性综述,各种不同的损失函数被归类为:基于欧式距离的,基于角/余弦边际的损失,基于softmax损失和它的变种。主流的网络结构如DeepFace[153],DeepID系列[145,146,149,177],VGGFace[116],FaceNet[137]和VGGFace2[20],还有其他特别为FR设计的结构;
- 将人脸处理方法进行了归类,划分成2类:one-to-many的增强和many-to-one的归一化,并讨论了如何用GAN[53]去促进FR。
- 分析了几大重要的数据集,主流的benchmark,如LFW[74],IJB-A/B/C[87,174],Megaface[83],MS-Celeb-1M[59]。在以下四个角度去进行介绍:训练方式,评估任务,评估指标,识别场景。
- 总结了许多对深度FR来说仍然十分具有挑战性的特定FR场景,如反欺骗,跨姿态FR,跨年龄FR。这些场景解释了未来深度FR需要努力的方向。
本文组织架构如下:
- 第二部分,介绍了一些背景概念和术语,然后简短的介绍了FR每个组件;
- 第三部分,介绍了不同的网络结构和损失函数;
- 第四部分,总结了人脸处理的一些算法;
- 第五部分,介绍了一些数据集和评估方法
- 第六部分, 介绍了在不同场景下的一些深度FR方法。
- 第七部分,总结和展望。
2 概述
2.1 背景概念和术语
如[123]所述,人脸识别包含三个部分,如图3
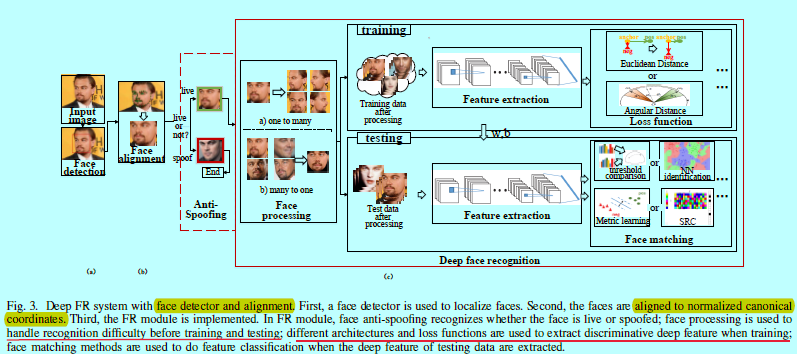
- 人脸检测:用来在图像和视频中定位人脸;
- 人脸关键点检测:用来对齐人脸到规范化的坐标上;
- FR模块:基于对齐的人脸做人脸验证或者识别
本文主要关注上述的FR模块。而FR模块又可以划分成人脸验证和人脸识别。不论是哪种,都需要提供训练集(gallery)和测试集(probe)。人脸验证是基于测试集和训练集计算当前两张人脸是否属于同一个人(1:1);人脸识别是计算当前测试人脸与人脸库中哪一张最相近(1:N)。当测试的人脸出现在训练集中,该问题叫做闭集识别(closed-set identification),当测试的人脸不在训练集中,该问题叫开集识别(open-set identification)。
2.2 人脸识别的组成部分
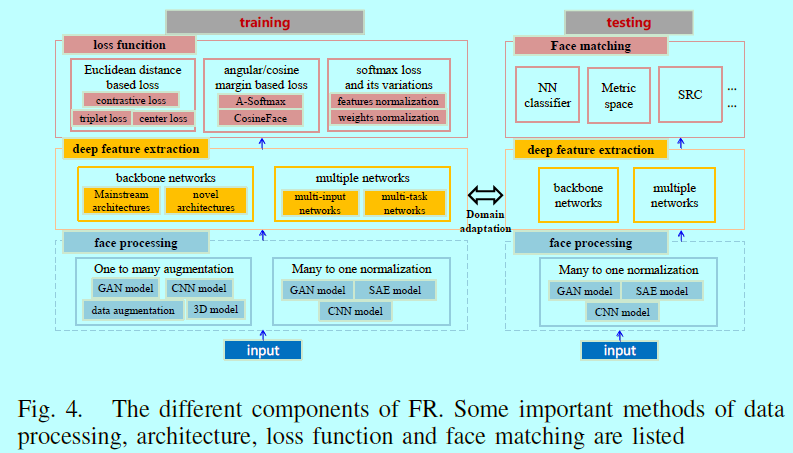
在人脸图片输入到FR模块之前,还需要进行人脸反欺骗(即活体检测,用来识别当前的人脸是活的还是一张相片),从而避免一部分的攻击(这在第六部分有所介绍)。然后就可以进行人脸识别了。如图3(c),一个FR模块包含人脸处理,深度特征提取,人脸匹配。其可以描述成:
这里\(I_i\)和\(I_j\)是两张人脸图像;\(P\)表示处理个人内部变化,如姿态,光照,表情和遮挡;\(F\)表示特征提取,用于编码身份信息;\(M\)表示匹配算法,用于计算它们之间的相似度。
人脸处理
虽然深度学习方法展现了其强大的表征能力,Ghazi[52]还是发现对于不同的条件,如姿态,光照,表情,遮挡等问题仍然影响着深度FR的性能,所以人脸处理依然是必须的,特别是姿态。因为姿态的变化一直被认为是自动FR应用中一个主要的挑战。本文主要总结了用深度学习去处理姿态的方法,其他的变化也可以用相似的方法去处理。
人脸处理方法可以划分成2个类别:one-to-many的增强;many-to-one的归一化,如表1所示。
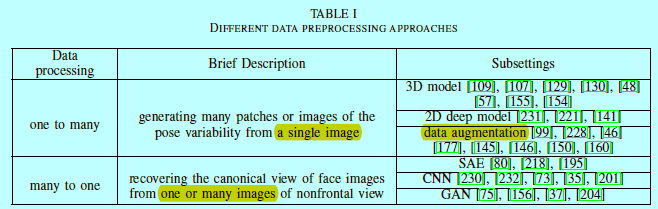
- one-to-many增强:从单张图片中生成许多块或者图片来进行姿态变化的多样性,保证深度网络能学到姿态不变性表征;
- many-to-one归一化:从单张或多张非正脸图片中恢复人脸图片到规范的角度;然后FR可以如在约束条件下进行识别或验证。
深度特征提取
主要涉及网络结构。网络可以划分成骨干网络和多重网络,如表2
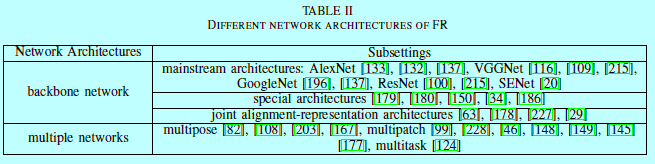
因为Imagenet的成功[131],大量经典网络层出不穷,如alexnet[88],vggnet[142],googlenet[151],resnet[64],senet[72],被广泛用在FR的baseline模型中;当然在主流之外,仍然有很多特意为FR设计的网络可以提升效率。更多地,当使用这些骨干网络作为基本网络构建块的时候,FR模块通常会基于多个输入或者任务训练多个不同的网络。Hu[70]认为多重网络可以累积结果从而提升准确度。
损失函数:softmax损失因具有不错的可分性而一直被用在目标识别中。然而对于FR,当类内差异大于类间差异时,softmax就不足以很好的区分了。所以人们也在如何构建新的损失函数使得学到的特征不但具有可分性还具有判别性。如表3

- 基于欧式距离的loss:基于欧式距离去压缩类内方差,并扩大类间方差;
- 基于角/余弦边际的loss:以角的相似性去学习判别性的人脸特征,使得学到的特征有潜在更大的角/余弦分离;
- softmax和它的变种:直接使用softmax损失或者修改softmax以提升性能。如基于特征或者权重的L2正则,还有噪音注入。
人脸匹配
在深度网络经过大量的数据和合适的损失函数训练之后,可以将每个测试图片经过该网络,从而获取该图片的深度特征表征。一旦提取了该深度特征,就可以直接用许多去计算两个特征之间的相似性,如余弦距离,L2距离;然后通过最近邻或者阈值比较的方式去完成人脸识别和验证的任务。另外还能通过对深度特征进行后处理阿荣你还提升人脸匹配的效率和速度,例如度量学习,基于稀疏表示的分类器(sparse-representation-based classifier,SRC)。在图4中,总结了FR各种模块和他们通常使用的方法,以方便读者对FR有个宏观视角。
3 网络结构和训练损失函数
因为地球上有几十亿的人脸,所以在真实世界中,FR其实算得上是一个细粒度的目标分类任务。对于大多数应用,是无法在训练阶段包含需要判别人脸的(即测试的人脸通常不会在训练集中),这就使得FR成为了一个”zero-shot“学习任务。还好,因为所有的人脸的形状和纹理都差不多,所以从一个小比例的人脸数据集上学到的表征能很好的泛化到剩下的地球人上。最简单的方法自然是尽可能的扩大训练集中的ID。例如网络巨头Facebook和Google宣称他们的可训练的人脸ID库有\(10^6-10^7\)个ID[137,153]。不过可惜的是,这些都是私有不公开的,还有这些巨头的计算力也十分巨大。这些都是学术界无法得到的。当前学术界可用的公开训练集只包含\(10^3-10^5\)个ID。然而学术界在不断的尝试设计高效的损失函数去使得在较小的训练数据及上深度特征更具有判别性。
在本部分,我们总结了学术界关于不同损失函数的发展。
3.1 判别性损失函数的演变
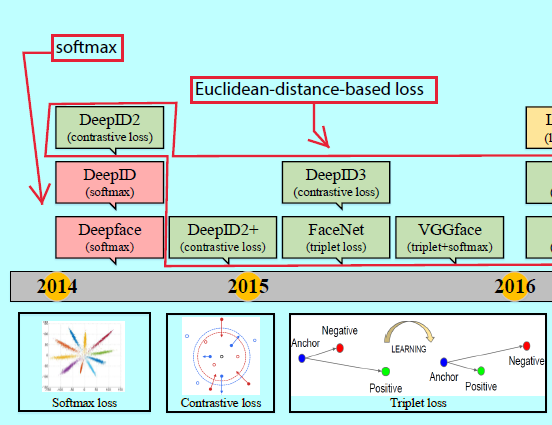
从目标分类网络发展至今,如alexnet,最开始的FR网络如Deepface[153]和DeepID[149]都是采用基于softmax loss的交叉时进行特征学习的。然后人们发现softmax不足以去学习有大边际的特征,所以更多的研究者开始利用判别性损失函数去增强泛化能力。这也变成了深度FR研究中最火热的研究点,如图5.
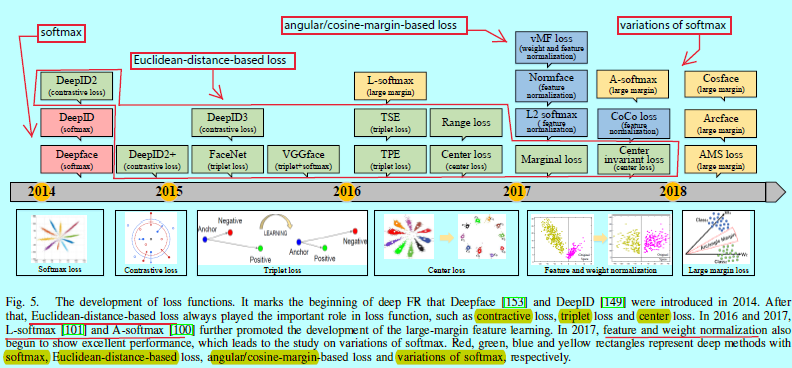
在2017年之前,基于欧式距离的损失函数占据主流;在2017年,角/余弦边际的损失函数,特征与权重归一化这两个开始流行。虽然许多损失函数的基本思想差不多,不过最新的损失函数都是设计成采用更容易的参数或者采样方法去方便训练。
基于欧式距离的loss
欧式距离loss是一种度量学习[171,185],即通过将图片嵌入到欧式空间中,完成压缩类内方差扩大类间方差的目的。contrastive loss和triplet loss都是较为常用的损失函数。contrastive loss[145,146,150,177,198]需要人脸图像对(face image pairs),然后将其中的正对(positive pairs)拉近,将负对(negative pairs)推远。
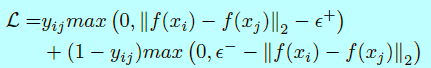
这里\(y_{ij}=1\)意味着\(x_i\)和\(x_j\)是匹配的样本,当\(y_{ij}=-1\)意味着他们是不匹配的样本。\(f( \cdot )\)是特征嵌入向量,\(\epsilon^+\)和\(\epsilon^-\)控制着匹配对和不匹配对的边际。DeepID2[177]通过将人脸识别(softmax)和人脸验证(contrastive loss)的监督信号结合起来去学习判别性表征,并用联合贝叶斯(JB)去获取一个鲁棒性的嵌入向量空间。DeepID2+[145]增大了隐藏表征的维度并在前面的网络层增加了监督信号,而DeepID3[146]更是引入了VGGNet和GoogleNet。然而contrastive loss的主要问题是边际参数十分难选择。
不同于contrastive loss是计算匹配对和不匹配对的绝对距离,triplet loss考虑他们之间的相对距离。随着google提出FaceNet[137],triplet loss[46,99,116,132,133,137]被引入到FR中。不过它需要人脸三元组,然后最小化锚点与同一个ID的其他正样本之间的距离,最大化锚点与其他ID的负样本之间的距离。FaceNet使用硬triplet人脸样本去完成公式如
这里\(x_i^a\),\(x_i^p\),\(x_i^n\)分别是锚点,正样本和负样本。\(\alpha\)是边际;\(f(\cdot )\)表示一个非线性变换通过将图片嵌入到特征空间中。受FaceNet的启发,TPE[132]和TSE[133]是去学习一个线性映射\(W\)到construct triplet loss,其中TPE满足等式3,TSE部分满足等式4
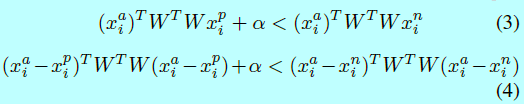
其他方法有结合triplet loss和softmax loss[36,46,99,228]。他们首先用softmax训练网络,然后用triplet loss做微调。然而,contrastive loss和triplet loss有时候会遇到训练的不稳定,这主要与选择的训练样本有关。一些论文就开始寻找简单的代替方法。center loss[173]和它的变种[39,183,215]对于压缩类内方差是个好选择。在[173]中,center loss学到每个类的中心,然后惩罚深度特征和他们的类中心的距离。这个loss可以定义成如下形式
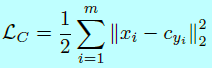
这里\(x_i\)表示属于\(y_i\)类的第\(i\)个深度特征,\(c_{y_i}\)表示\(y_i\)类的深度特征的中心。为了处理长尾问题,range loss[215]用于最小化一个类中k个最大range的harmonic均值,然后最大化一个batch中最短类间距离。Wu[183]提出了一个center-invariant loss,其用于惩罚每个类中心之间的距离。Deng[39]选择最远的类内样本和最近的类间样本用于计算边际损失(margin loss)。然而center loss和他的变种仍然受制于分类层在GPU内存中的占用,而且最好每个ID有平衡的足够的训练数据。
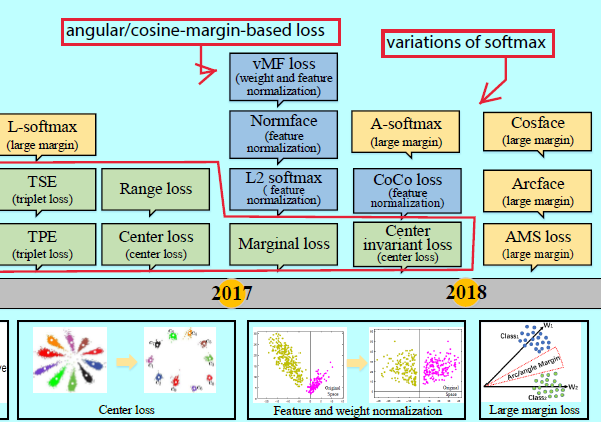
基于角/余弦边际的loss
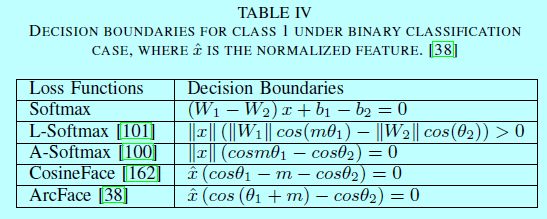
在2017年,人们对深度FR中的损失函数有了更深层次的理解,认为样本应该更严格的分离样本以避免对困难样本的误分类。角/余弦边际loss[38,100,101,102,162]被提出用来让学到的特征在更大角/余弦距离上能够潜在可分。Liu[101]将原始softmax loss重新定义到一个大边际(large-margin softmax, L-softmax) loss,这需要\(||W_1|| ||x|| cos(m\theta_1) > ||W_2||||x||cos(\theta_2)\),这里\(m\)是引入角边际的正整数,\(W\)是最后一层全连接层的权重,\(x\)表示深度特征,\(\theta\)是他们之间的角度。因为余弦函数的非单调性,在L-softmax中引入分段函数以保证单调性。该loss函数定义为:
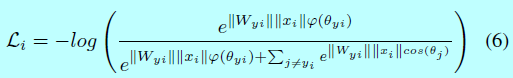
其中
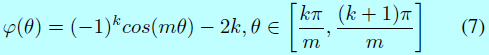
然而L-softmax比较难收敛,softmax loss总是被结合进去,以方便和确保收敛,然后通过一个动态超参数\(\lambda\)去控制权重。通过增加额外的softmax loss,该loss的新形式为:
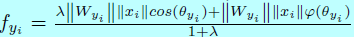
基于L-Softmax,A-Softmax loss随之被提出[100],通过L2范数(\(||W||=1\))去归一化权重\(W\),这样归一化后的向量就落在了超球面上,然后可以通过在超球面流行上学习一个角边际(图6)去获取判别性的人脸特征。
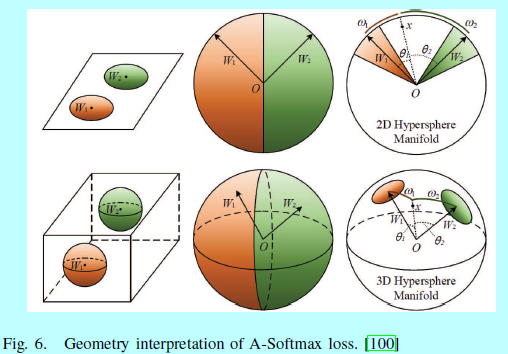
Liu[102]引入一个深度超球面卷积网络(SphereNet),采用超球面卷积作为其基本卷积算子,并通过角边际的loss进行监督。为了克服L-Softmax和A-Softmax的优化困难,他们以乘法方式结合角边际,ArcFace[38]和ConsineFace[162],AMS loss[164]各自引入一个额外的角/余弦边际\(cos(\theta + m)\)和\(cos\theta -m\)。他们都很容易实现,且没有超参数\(\lambda\),而且更清晰,并且不需要通过softmax的监督去完成收敛。表4中展示了基于二分类的决策面。
相对基于欧式距离的loss而言,角/余弦边际loss显式的在一个超球面流行上增加判别性约束,本质上匹配了人脸落在该流行上的先验。
softmax及其变种
在2017年,除了将softmax loss重定义到一个角/余弦边际loss中,仍然有许多基于softmax本身的工作。如对softmax loss中的特征或者权重做归一化。这可以写成如下形式:
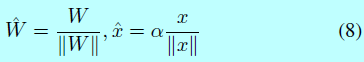
这里\(\alpha\)是一个尺度参数。缩放\(x\)到一个固定的半径\(\alpha\)是很重要的,如[163]证明了归一化特征和权重到1 可以让softmax loss在训练集上陷入到一个很大的值。特征和权重归一化是高效的tricks,而且可以用在其他loss上。
在[38,100,102,162]中,loss函数只归一化权重并用角/余弦边际进行训练可以让学到的特征更具判别性。相较之下,许多工作[60, 122] 自适应特征归一化只是解决了softmax的样本分布的偏置。基于[115]的观测结果,用softmax loss加上L2-范数学到的特征具有人脸质量的信息性,L2-softmax[122]强制让所有的特征通过特征归一化使得他们具有相同的L2范数,这样高质量的正脸和有着极端姿态的模糊人脸就有相似的注意力。Hasnet[60]不是通过缩放参数\(\alpha\),而是用\(\hat x=\frac{x-\mu}{\sqrt{\sigma^2}}\)来归一化特征,这里\(\mu\)和\(\sigma^2\)是均值和方差。归一化特征和权重[61,104,163]已经变成了一个通用的策略了。在[163]中,Wang从分析角度和几何角度揭示了归一化操作的必须性。在特征和权重归一化后,CoCo loss[104]优化额数据特征内部的余弦距离,而[61]使用von Mises-Fisher(vMF)混合模型区作为理论基础,提出了一个新颖的vMF混合loss和对应的vMF 深度特征。
在归一化之外,同时也有其他策略来修改softmax;如Chen[23]通过在softmax中注入退火噪音,提出一个噪音的softmax去模拟早期饱和。
3.2 网络结构的演变
骨干网络
骨干网络,也就是主流结构,在深度FR中使用的网络结构基本都和深度目标分类一样,都是从alexnet发展到senet。我们这里按照最具影响力的结构发展来介绍,如图7.
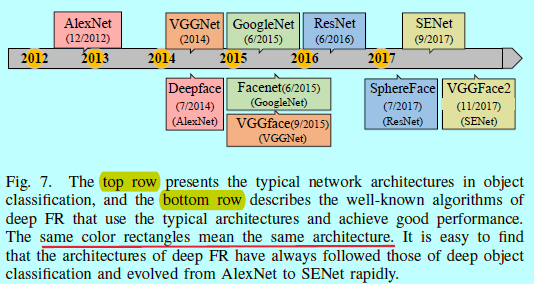
在2012年,Alexnet[88]在Imagenet上获得了最好的结果,超过第二名一大截。alexnet包含了5层卷积层和三层全连接层,他同时整合了多种技术,如ReLU,dropout,数据增强等等。然后在2014年,VGGNet[142]被提出,其中包含非常小的卷积过滤器(3x3),和在每次2x2池化之后,将通道数进行加倍。它成功的让CNN的深度提升到了16-19层,其网络结果表明了通过深度结构学习非线性映射的灵活性。在2015年,22层的GooleNet[151]引入一个"inception模块"。在2016年。。。。 主流结构如图8.
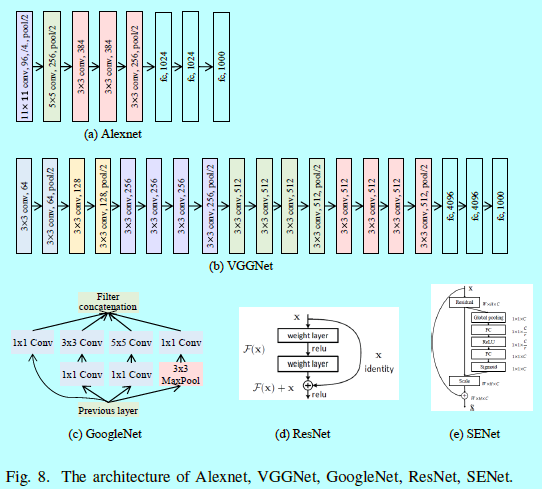
受到目标分类中的进展影响,深度FR也追寻着这些主流结构的使用。在2014年,DeepFace[153]是第一个采用了7层局部连接层的一个9层CNN。通过对数据进行三维对齐,它在LFW上获得了97.35%的准确度。在2015年,FaceNet[137]使用一个私有的人脸数据集去训练googlenet,通过一个新颖的在线triplet挖掘方式生成许多人脸块,然后在对齐的匹配/不匹配人脸块三元组上使用triplet loss函数,获得了99.63%的准确度。同年VGGface[116]也公开了一个人脸数据集,在该数据集上训练的VGGNet然后通过类似FaceNet的triplet loss进行微调,在LFW上获得了98.95%的结果。在2017年,SphereFace[100]使用一个64层的Resnet结构,并提出了angular softmax(A-softmax) loss,通过使用角边际学到了判别性人脸表征,将结果提升到了99.42%。在2017年底,出现了一个新的人脸数据集,VGGface2[20],其包含了在姿态,年龄,光照,种族,职业都有很大的变化。Cao首次用SEnet在Ms-celeb-1M[59]数据集上进行训练,然后用VGGFace2进行微调,在IJB-A[87],IJB-B[174]上获得了最好的效果。
特殊结构:在FR中有许多特定的网络结构,Wu[179,180]提出了一个maxfeature-map(MFM)激活函数,通过在CNN的全连接层中引入maxout。该MFM获得了一个紧凑的表征并减少了计算代价。有感于[97],Chowdhury[34]在FR中应用双线性CNN(B-CNN),通过结合两个CNN的每个位置上的输出然后进行平均池化,获得了双线性特征表征的能力。Sun[150]提出基于权重选择标准,从先前学习的更密集模型迭代地稀疏深度网络。条件卷积神经网络(c-CNN)[186]依据样本的模态动态的激活内核集。虽然设计用来在手机端运行的如SqueezeNet[76],MobileNet[69],ShuffleNet[33]和Xception[217]等网络目前还未被广泛的用在FR上。
联合对齐-表征的网络:最近,一个端到端的系统[29,63,178,227]可以用来联合训练几个模块(人脸检测,对齐等等)。相较于那些每个模块根据不同的目标单独优化,这个端到端系统根据识别目标优化每个模块,从而为识别模型提供更充分和稳健的输入。例如,受spatial transformer[77]的感想,Hayat[63]提出一个基于CNN的数据驱动方法,同时进行注册器的学习和人脸表征的学习(图9)
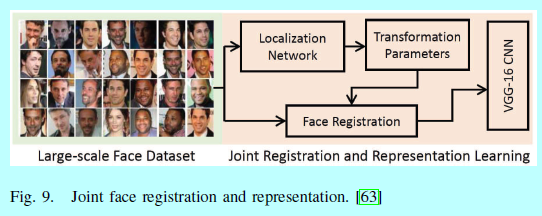
Wu[178]设计了一个新颖的递归空间变换(recursive spatial transformer, ReST)模块,让CNN能够同时进行人脸对齐和识别。
多重网络
多输入网络:对应"one-to-many增强"是通过生成图像的多个块或者姿态的形式,该结构也可以改成同时接受多个输入的多重网络。在[46,99,145,148,149,177,228]中,多重网络都是在生成不同人脸块之后进行构件的,然后一个网络去处理其中的一种数据类型。其他文献[82,108,167]使用多重网络去处理不同姿态的图片。例如,Masi[108]先调整姿态到正脸(\(0^o\)),半脸(half-profile)(\(40^o\)),全貌(full-profile view)(\(75^o\)),然后通过多角度网络去处理姿态变化。在[82]中的多角度深度网络(multi-view deep network, MvDN)包含特定角度的子网络和通用子网络,前者用来移除特定角度的变化,后者获取通常的表征。Wang[167]使用对SAE来应对交叉角度FR(cross-view)
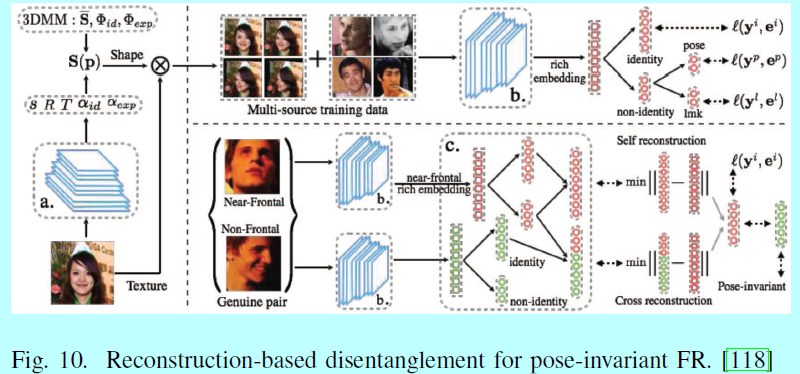
多任务学习网络:其他类型的多重网络是多任务学习,进行ID分类是其主要任务,其他副任务如姿态,光照,表情等等。在这些网络中,低层网络会基于所有任务进行共享,更高层就会分支到多个网络,以此生成具体任务的输出。在[124]中,任务依赖的子网络分叉出去学习人脸检测,人脸对齐,姿态估计,性别识别,笑容检测,年龄评估,人脸识别。Yin[203]提出了一个自动针对每个副任务赋予动态loss权重的方法。Peng[118]使用一个特征重构度量学习去分叉CNN网络到子网络中去,用于做人脸识别和姿态估计,如图10
3.3 用深度特征进行人脸匹配
在测试中,余弦距离和L2距离通常是用来对两个深度特征\(x_1\),\(x_2\)进行测量他们的相似度的。然后通过阈值对比或者最近邻分类器去做人脸验证和识别的任务。除了这两个常用的方法,还有一些其他方法。
人脸验证
度量学习,意在找到一个新的度量,能够让两个类更具有可分性,同样可以用在基于人脸匹配的深度特征上。如联合贝叶斯(JB)[25]模型是一个众所周知的度量学习方法[145,146,149,177,198]。Hu[70]证明了其能很大的提升性能。在JB模型中,人脸特征\(x\)以\(x=\mu+ \epsilon\)进行建模,这里\(\mu\)和\(\epsilon\)分别是ID和类内方差。相似性得分\(r(x_1,x_2)\)可以表示成:
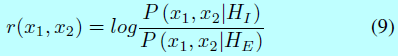
这里\(P(x_1,x_2|H_I)\)是两个人脸图片属于同一个人的概率,\(P(x_1,x_2|H_E)\)是两个人脸图片属于不同ID的概率。
人脸识别
在计算了余弦距离之后,Cheng[30]在多个CNN模型的鲁棒性多视图组合的相似性得分上提出了一个启发式投票策略在MS-celeb-1M 2017的challege2上获得了第一名。在[197],Yang在人脸图像的局部区域上提取局部自适应卷积特征,然后基于扩展的SRC在一个ID一个样本上完成FR。Guo[56]将深度特征和SVM分类器结合起来去识别所有的类。基于深度特征,Wang[160]首次使用乘积量化(product quantization,PQ)[79]去直接检索top-k个最相似的人脸,然后通过结合深度特征与COTS匹配器[54]进行人脸的重排序。另外,当训练集和测试集的ID有重复时,可以用softmax做人脸匹配。例如在MS-celeb-1M challenge2中,DIng[226]训练了一个21000类的softmax分类器,直接在通过条件GAN进行特征增强之后识别one-shot类和正常类的人脸图片。Guo[58]通过训练结合了underrepresented-classes promotion loss项的softmax来增强该性能。
当训练集的分布和测试集的分布是一样的,那么上述人脸匹配方法效果都很好。可是如果不一样,那么效果就会急转直下。迁移学习[113,166]也就被引入到深度FR中,其利用在一个相对的原领域(训练集)进行FR的训练,然后在目标领域(测试集)进行执行FR。当存在领域迁移时,有时候这有助于人脸匹配。[36,187]采用了模板自适应,这是一种模板的迁移学习,通过结合CNN特征与特定模板的线性SVM。但是大多数,只在人脸匹配上进行迁移学习还是不够的。迁移学习应该潜入到深度模型中去学习更具迁移性的表征。Kan[81]提出一个bi-shifting自动编码网络(bi-shifting autoencoder network,BAE)在跨视角,种族和图像成像传感器之间进行领域自适应;而Luo[233]针对同一个目的采用了多核最大均值差异(multi-kernels maximum mean discrepancy,MMD)。Sohn[143]使用对抗学习[158]去将静态图片FR进行知识迁移到视频FR上。先使用目标训练数据进行训练,在预训练好的模型上将CNN参数进行微调到新的数据集。在很多方法中都是这么用的[4,28,161]。
4 训练和识别中的人脸处理
当我们关注不同的人脸处理方法如图11,就会发现每年都会有很多不同的主流方法
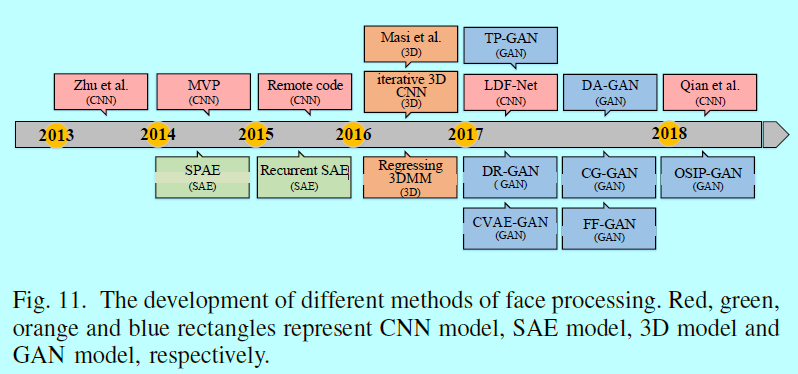
在2014年到2015年,大多数的方法还是SAE模型和CNN模型;在2016年3D模型占据了主流;在Goodfellow发明GAN[53]开始,GAN就被深度学习和机器视觉社区深入研究。它可以用在多个不同的领域,同样也有人脸处理。在2017年,GAN显示了其在FR的能力,他不但可以完成”one-to-many增强“,也能完成”many-to-one归一化“,同时它打破了人脸合成需要基于有监督的限制。虽然GAN还没广泛用在人脸处理和识别中,它还是很有潜力的。例如,Dual-Agent GANs(DA-GAN)[221]在NIST IJB-A 2017FR比赛上赢得了验证和识别的第一名。
4.1 one-to-many的增强
收集一个大的数据集的代价是很大的,而”one-to-many增强“可以模拟数据收集的过程,然后用来增强训练数据集和测试数据集,我们将他们归类为四类:
- 数据增强:
- 3D模型;
- CNN模型;
- GAN模型。
数据增强:常见的数据增强方法包括光度变换[88,142]]和几何变换,如过采样(通过不同尺度裁剪获得的多个块)[88],镜像[193],以及旋转[184]。近年来,数据增强已经在深度FR算法[46,99,145,146,150,160,177,228]中普遍应用了。例如Sun[145]通过crop了400个人脸块,其中涉及了位置,尺度,颜色通道和镜像等等。在[99]中,在人脸区域获取7个不同的关键点,以其作为中心得到7个重叠图像块,然后用7个相同结构的CNN去分别输入这7个图像块。
3D模型:3D人脸重构同样是一个丰富训练数据的方法,有许多论文在这方面有研究,但是我们只关注使用深度方法去进行3D人脸重构的部分。在[109]中,Masi用新的类内外观变化去生成人脸图片,包括姿态,形状和表情,然后用VGG-19去训练真实和增强的数据。[107]使用通用3D人脸和渲染的固定视角去减少计算代价。Richardson[129]使用了一个迭代3D CNN,通过使用辅助输入通道表示之前网络的输出作为用于重建3D人脸的图像,如图12
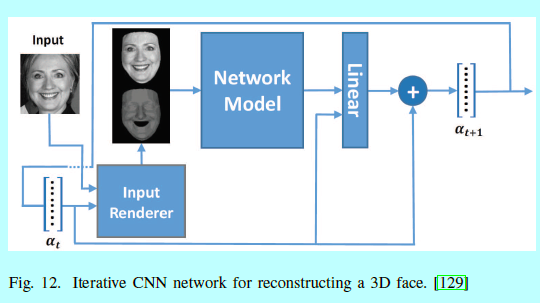
Dou[48]使用一个多任务CNN,将3D人脸重构任务划分成神经3D重构和表情3D重构。Tran[155]直接通过一个非常深的CNN结构去回归3D可变型人脸模型(3d morphable face model,3DMM)。An[208]采用3DMM去合成各种姿态和表情的人脸图片,然后通过MMD去减少合成数据与真实数据之间的鸿沟。
CNN模型:不采用先从2D图像进行3D重构然后将其映射回2D的各种不同的姿态的方法,CNN能直接生成2D的图片。在多角度感知中(multi-view perceptron,MVP)[231],判别性的隐藏层神经元可以学习ID特征,而随机隐藏神经元可以去抓取视角特征。通过采样不同的随机神经元,不同姿态的人脸图片都是合成的。类似[201],Qian[200]使用了7个Recon codes将人脸以7个不同的姿态进行旋转,然后提出了一个unpair-supervised方法去学习人脸变化的表征,而不是通过Recon code去做有监督
GAN模型:在使用一个3D模型生成侧面图像,DA-GAN[221]可以通过GAN提炼该图像,该GAN结合了数据分布和人脸知识(姿态和ID认知loss)的先验。CVAE-GAN[11]通过将GAN与一个变分自动编码器去增强数据,然后利用了统计和成对的特征匹配去完成训练过程,且手里更快更稳定。在从噪音中合成不同人脸之外,许多文献也会去探索如何将ID和人脸的变化进行解耦,从而通过交换不同的变化来合成新的人脸。在CG-GAN[170]中,生成器直接将输入图像的每个表征解析为变化编码和ID编码,并重新组合这些编码以进行交叉生成,而判别器确保生成的图像的真实性。Bao[12]提取一个输入图片的表征和任何其他人脸图片的属性表征,然后通过重组这些表征生产新的人脸。该工作在生产真实和ID表示的人脸图片上展现了超强的性能,甚至是训练集之外的数据。不同于之前的将分类器作为观测者,FaceID-GAN[206]提出一个三角色GAN,其中分类器同时与判别器合作,去和生成器在两个方面(人脸ID和图像质量)做竞争。
4.2 many-to-one的归一化
该方法是生成正脸,并减少测试数据的变化性,从而让人脸能够容易做对齐和验证。该方法可以简单归类为SAE,CNN和GAN三种。
SAE:提出的堆叠渐进式自动编码器(stacked progressive autoencoders,SPAE)[80]渐进的将非正脸通过几个自动编码器进行堆叠映射到正脸上。在[195]中,一个结合了共享ID单元(identity units)和递归姿态单元的一个递归卷积编码解码网络(recurrent convolutional encoder-decoder)在每个时间步上通过控制信号去渲染旋转的目标。ZHang[218]通过设置正脸和多个随机脸为目标值构建了一个many-to-one编码。
CNN:Zhu[230]在规范视角上,使用一个有特征提取模块和正脸重构模块组成的CNN去提取人脸身份保留特征从而重构人脸。Zhu[232]根据人脸图像的对策和外形选择规范视角的图片,然后通过一个CNN基于最小化重构loss去重构正脸。Yim[201]提出一个多任务网络,其能够通过使用用户远程编码(user's remote code),旋转一个任意姿态和光照的人脸到目标姿态人脸上。[73]根据它们之间的像素位移场将非正脸图像变换为正脸图像。
GAN:[75]提出一个两路径的生产对抗网络(two-pathway GAN, TP-GAN),其包含四个定点关键点人脸块网络和一个全局的编码解码网络。通过结合对抗loss,对称loss和ID保留loss,TP-GAN生成一个正脸角度的同时保留了全局结构和局部信息,如图13.
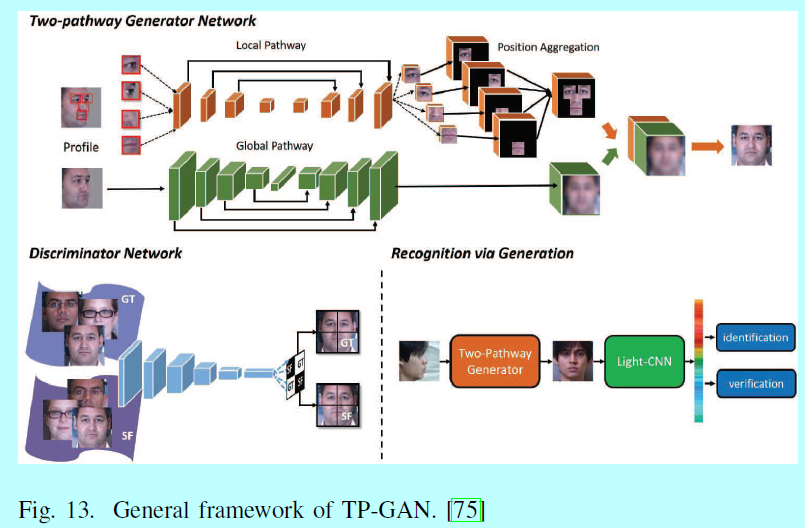
在解耦表征学习生成对抗网络(DR-GAN)[156]中,编码器生成身份表征,并且解码器使用该表征和姿态编码合成指定姿态的人脸。Yin[204]将3DMM引入到GAN结构中,以提供外形和外观先验,从而知道生成器生成正脸。
5 人脸数据集和评估方案
在过去三十多年中,人脸数据集从小型到大型从单源到多源,从约束场景到无约束的真实世界场景。如图14

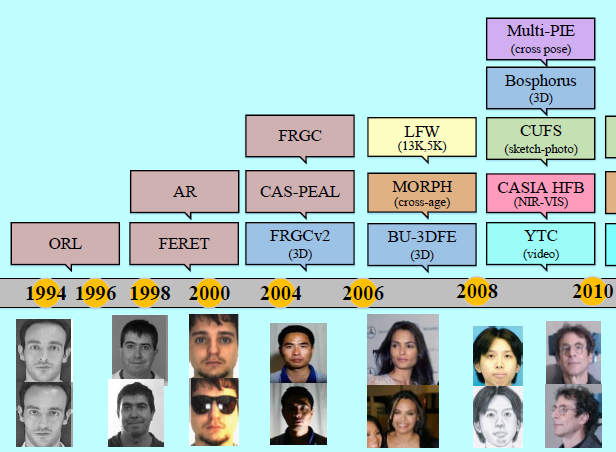
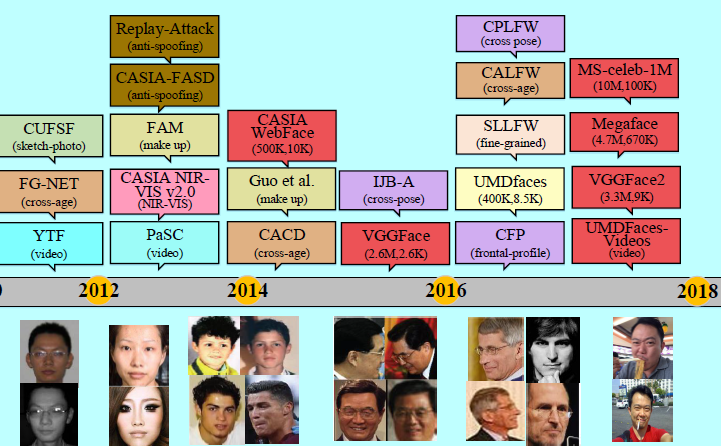
随着虚弱简单数据集变得饱和,越来越多复杂的数据集被不断的提出。可以说数据集本身的提出,也帮助FR的发展指明了方向。在本部分中,主要简单介绍下主流数据集。
5.1 大规模通用训练数据集
要想有很好的深度FR,必须要有足够大的训练集。Zhou[228]认为深度学习加大量的数据可以提升FR的性能。MegaFace挑战的结果揭示了之前的深度FR通常都是基于大于50十万张图片和2万个ID上训练的。深度FR早期的工作通常都是基于私有训练数据集的。Facebook的深度人脸模型[153]是在4千个ID,4百万张图片上训练的;Google的FaceNet[137]是在3百万个ID,2亿张图片上训练的;DeepID系列模型[145,146,149,177]是在1万个Id,20十万个图片上。虽然他们宣称打破了记录,可是却没法通过公开的数据集去复现他们的结果。
为了处理这个问题,CASIA-WebFace[198]首次提供了一个超大数据集,其中包含1w个名人,50十万张图片。基于其数据集的量和简单的使用方法,它变成了学术界的一个标准数据集。然而因为其数据量和ID不够多,还是无法推进更多更好的深度学习方法。当前已经有了不少公开的数据集,如MS-Celeb-1M[59], VGGface2[20], MegaFace[83,112].图15
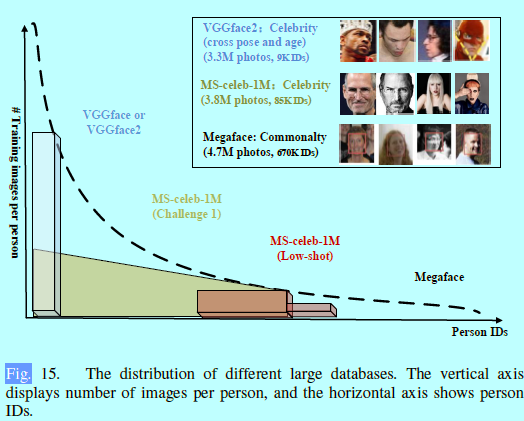
这些大型训练集都是从深度和广度上进行扩展。VGGFace2的是基于深度的大规模训练集,其限制了ID的个数扩展了每个ID的图片个数。数据集的深度增强了模型处理较大类内变化的能力,例如光照,姿态和年龄;而MS-Celeb-1M和Megeface(挑战2)提供了基于广度的大规模训练集,其中包含了很多iD,不过限制了每个ID的图片个数。数据集的广度增强了模型处理类间变化的能力。Cao[20]在VGGFace2和MS-celeb1-M上进行模型训练并做了系统性研究,并发现首先在MS-celeb-1M(广度)上训练然后在VGGFace2(深度)进行微调可以得到最优的结果。
当然不同数据集之间的对长尾分布的使用也是不同的,在MS-Celeb-1M挑战2中,该数据集特别用尾数据来研究low-shot学习;中心部分用来作为挑战1的任务且每个ID图像的个数都逼近100张;VGGFace和VGGFace2只用了其分布前面部分;MegaFace使用了整个分布,尽可能包含所有图片,其中每个ID最少3个图片,最多2469个图片。
在大多数数据集中会存在数据偏置问题,一个主要的原因就是每个数据集只覆盖了人脸数据的部分分布。另一个原因是大多数数据集(VGGface2,Ms-celeb-1M)中的名人是在空开场合:笑着,化妆了,年轻,且漂亮。所以它们就和从日常生活中采集的(Megaface)不同。因此,基于这些数据集训练的深度模型不能直接在一些特定场景使用,因为数据偏置。需要重新收集大量的标签数据去从头训练一个模型或者重新收集无标签塑化剂去进行领域自适应[166]或者使用其他方法。
几个主流的benchmark如LFW无约束方案,MegaFace挑战1,Ms-Celeb-1M挑战 1&2,都是显式的鼓励研究者去收集和清洗一个大型数据集,从而增强网络的能力。虽然数据工程对CV研究者是一个有价值的问题,可是工业界的人才往往熟知该门道。如lederboards上展示的,大多数都是由公司所占据,因为他们有着巨大计算力和数据。这个现象对于学术界开发新模型是不利的。
对于学术界,建立一个足够大和干净的数据集是十分有意义的。Deng[38]发现Ms-Celeb-1M里面有不少标签噪音,他减少了该噪音,然后公开了清洗后的数据集。Microsoft和Deepglint联合公开了从MS-Celeb-1M清洗后的最大干净标签数据集,其中包含4百万张图片和10万个亚洲名人。
5.2 训练方案
在训练方案(training protocol)中,FR模型可以通过目标依赖或者独立环境下进行评估,如图16
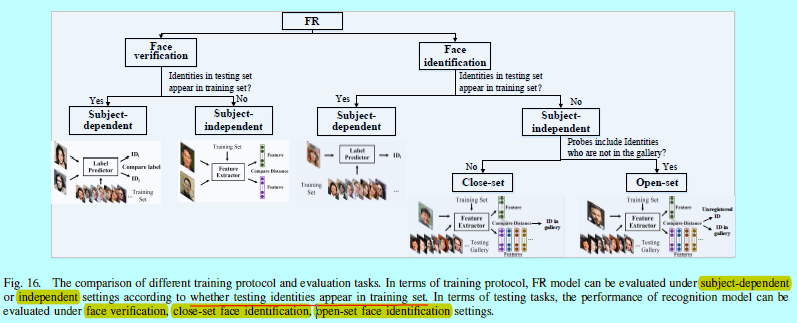


目标依赖(subject-dependent):所有的测试ID都出现在训练集中,所以该情况的问题可以看成是一个分类问题,其中特征都期望是可分的。该方案是FR发展的最早阶段(2000年之前),如FERET[120],AR[106],只适合在一些小范围的应用。MS-Celeb-1M是目前唯一的使用该方案的大型数据集。
目标独立(subject-independent):测试ID通常不出现在训练集中。因为无法将人脸分类给训练集,所以目标独立的表征是有必要的。因为人脸总是表现的相似的类内变化,深度模型可以在一个足够大的通用ID数据集上学到很好的泛化能力,其中的关键就是学到判别性的大边际深度特征。几乎所有主流的人脸识别benchmark如LFW,PaSC[14],IJB-A/B/C和MegaFace,都需要测试的模型先基于目标独立方案上进行训练。
5.3 评估任务和性能指标
为了评估一个深度模型是否解决了现实生活中遇到的不同FR问题,设计了许多基于不同任务的测试集和场景,如表9.

在测试任务中,人脸识别模型的性能会基于人脸验证,闭集人脸识别,开集人脸识别上评估,如图16。每个人物都有对应的性能指标。
人脸验证:人脸验证与访问控制系统,Re-ID和FR算法的应用程序独立评估相关。它通常使用(receiver operating characteristic,ROC)和平均(accuracy,ACC)进行评估。给定一个阈值(独立变量),ROC分析可以测量真接受率(true accept rate,tar),真正超过阈值的结果所占比例;假接受率(false accept rate,far)是不正确的超过阈值的结果所占比例。ACC是LFW采用的一个简化指标,表示正确分类的比例。随着深度FR的发展,测试数据集上的指标越来越严格地考虑安全程度,以便在大多数安全认证场景中当FAR保持在非常低的比例时,TAR能够符合客户的要求。PaSC在FAR等于\(10^{-2}\)时对TAR进行评估;IJB-A将其提高到\(TAR@10^{-3}FAR\);Megaface专注于\(TAR@10^{-6}FAR\); 而在MS-celeb-1M 挑战3上,指标是\(TAR@10^{-9}FAR\).
闭集人脸识别:就是基于用户的搜索,Rank-N和累积匹配特征(cumulative match characteristic, CMC)是该场景中常用的指标。Rank-N基于测试样本搜索在排序结果前K个中返回测试样本的正确结果百分比。CMC曲线表示在给定rank(独立变量)测试样本识别的比例。IJB-A/B/C主要使用rank-1和rank-5识别率。MegaFace挑战系统性评估rank-1识别率,其中最好的结果在表6。
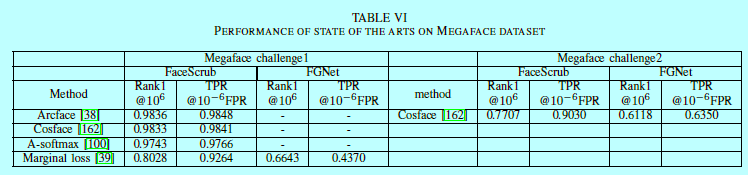
MS-Celeb-1M使用precision-coverage曲线去基于可变阈值\(t\)下测试识别性能。当得分低于阈值\(t\),则该测试样本会被拒绝。算法之间对比就是看测试样本到底测试正确了多少,如95%,99%,不同算法的评估在表7。

开集人脸识别:该场景是人脸搜索系统中较为常见的。这里识别系统应该拒绝那些未注册的用户。现在来说,很少有数据集是基于该任务考虑的。IJB-A引入了一个决策误差权衡(decision errr tradeoff, DET),以将FNIR表征为FPIR的函数。The false positive identification rate (FPIR) measures what fraction of comparisons between
probe templates and non-mate gallery templates result in a match score exceeding T。the false negative identification rate (FNIR) measures what fraction of probe
searches will fail to match a mated gallery template above a score of T。算法基于低FPIR基础(1%,10%)上,以FNIR来评估IJB-A数据集上算法的结果,如表8

5.4 评估场景和数据
有许多不同的数据集用于模拟现实生活中不同的场景,如表9。按照它们各自的特色,我们将这些场景划分成四个:
- 跨因素的人脸识别;
- 异质的人脸识别;
- 多(单)媒体的人脸识别;
- 工业界人脸识别

跨因素的人脸识别:因为复杂的非线性人脸外观,由许多是人类自身导致的变化,如跨姿态,跨年龄,化妆。例如CALFW[225],MORPH[128],CACD[24]和FG-NET[1]都是基于不同年龄段的;CTP[138]只关注正脸和侧脸,CPLFW[223]从LFW中提取的基于不同姿态的。
异质的人脸识别:主要是为了基于不同的视觉领域进行人脸匹配。领域鸿沟主要有传感器设备和照相机设置引起的,如可见光和近红外,照相和素描。例如,相片和素描的数据集,CUFSF[213]要难于CUFS[168]因为光照变化和变形。
多(单)媒体的人脸识别:理论上深度模型都是基于每个ID大量的图片上训练,然后基于每个ID一张图片上测试。可是现实是,训练集中每个ID的图片很少,被称为low-shot FR,例如MS-Celeb-1M 挑战2;或者测试机中每个ID人脸通常采集自图片和视频,被称为set-based FR,例如IJB-A和PaSC。
工业界人脸识别:虽然深度FR在一些标准benchmark上效果超过了人类,不过当深度FR在工业上应用的时候,我们需要关注更多的细节,如反欺骗(CASIA-FASD[219])和3D FR(Bosphorus[134],BU-3DFE[202]和FRGCv2[119]).对比公开的可用2D数据集,3D扫描很难获取,而且开源的3D人脸数据集也受限扫描的图片个数和ID个数,这也阻碍了3D深度FR的发展。
6 不同的识别场景
为了应对不同场景的数据集,需要很好的深度模型在大量数据集上训练。然而,因为隐私问题,公开的数据集大部分来自名人的照片,基本没法覆盖不同场景下日常生活的图像抓取。不同LFW中的高准确度,在megaface中,效果仍然没法达到现实应用的地步。对于工业界,就是基于不同的目标场景收集一个较大数据集然后以此来提升效果。然而,这只是一个方面。因此,需要考虑如何在受限数据集基础上采用更好的算法来明显的提升结果。本部分,我们介绍几个基于不同场景下的特殊算法。
6.1 跨因素的人脸识别
跨姿态人脸识别:如[138]中说明的,许多现存算法在正脸-正脸验证改成正脸-侧脸验证时准确度降低10%,交叉姿态FR仍然是一个极端挑战的场景。之前提到的方法包括"one-to-many增强",“many-to-one归一化”,多输入网络和多任务学习还有其他算法都是用来应对该场景的方法。考虑这些方法需要额外的代价,[19]首次尝试在深度特征空间中使用正脸化,而不是图像空间中。一个深度残差等效映射(deep residual equviariant mapping,DREAM)块动态的在输入表征上增加残差去将侧脸映射到正脸上。[27]提出结合特征提取与多角度子空间学习去同时让特征变得姿态鲁棒和判别性。
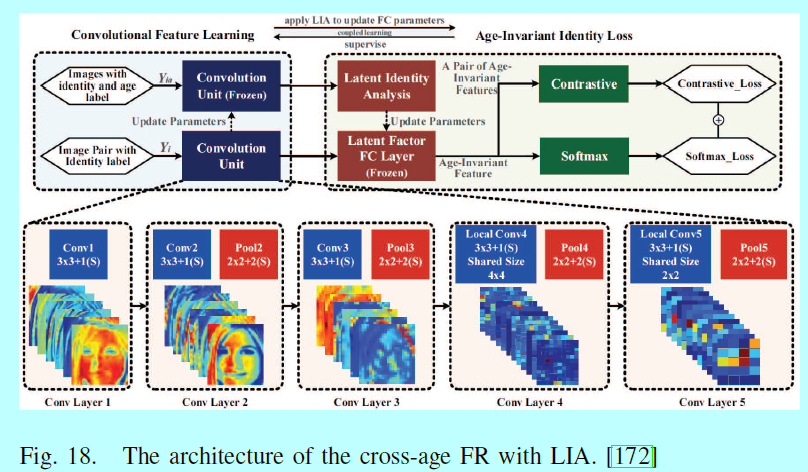
跨年龄人脸识别:跨年龄FR一直是一个极端的挑战,因为随着年龄的改变,人脸的外观也伴随巨大变化。一个直接的方法就是将输入图片以特定年龄进行合成。[49]提出的生成概率模型可以以短期阶段进行建模年龄变化。Antipov[7]提出通过GAN进行年龄人脸合成,但是合成的人脸不能直接用来做人脸验证,因为它是对ID的不完美表征。[6]使用局部流行自适应(local mainfold adaptation,LMA)方法去解决[7]中的问题。一个代替的方案是将年龄/ID组件进行解耦,然后提取年龄不变性表征。[172]提出了一个潜在ID分析(latent identity analysis,LIA)层去分别这两个组件,如图18.
在[224]中,年龄不变特征可以通过在年龄评估任务中基于表征减去年龄指定的因子。另外,还有其他方法用在跨年龄FR上,如,[15,60]微调CNN去做知识迁移。Wang[169]提出基于siamese深度网络的多任务学习去应对年龄评估。Li[95]通过深度CNN整合了特征提取和度量学习。Yang[192]涉及了人脸验证和年龄评估,利用一个复合训练评价,整合简单的像素级别的惩罚,基于年龄的GAN loss去达到年龄变换,其中的个人依赖评价可以保持ID信息的稳定。
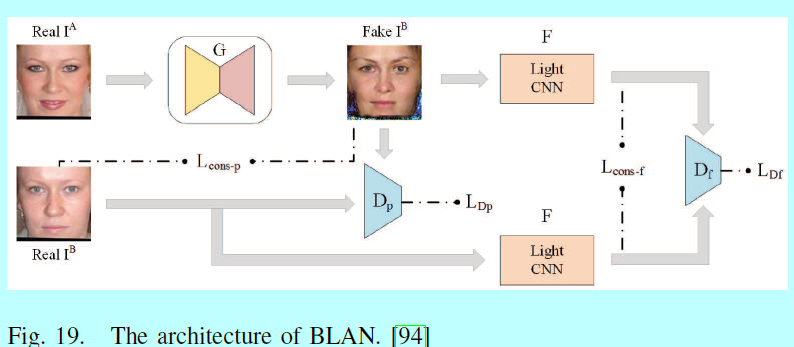
化妆人脸识别:在化妆如此平常的今天,也同时因为明显的人脸外观改变给FR带来巨大挑战,基于匹配化妆和不化妆的人脸图像研究一直受到持续性关注。[94]通过一个bi-level对抗网络(BLAN)上从化妆的图片上生成不化妆的图片,然后用该合成的不化妆图片进行验证,如图19.
[147]在开源的视频上训练了一个triplet网络,然后基于小的化妆和不化妆数据集进行微调。
6.2 异质的人脸识别
NIR-VIS人脸识别:由于在低光场景下近红外光谱(NIS)图像的优异性能,NIS图像被广泛应用于监视系统。NIS图像广泛用在监控系统中,因为大多数数据集有可见光(visible light,VIS)图谱图像,如何从VIS图像中识别出一个NIR人脸也成了热点。[103,135]通过微调迁移这个VIS深度网络到NIR领域中。[90]使用一个VIS CNN以交叉光谱幻视的方式变换NIR图像到VIS人脸,然后从低秩嵌入向量上恢复一个低秩结构。[127]训练了两个网络,一个VISNet(可见图像)和一个NIRNet(近红外线图像),通过创建一个siamese网络耦合他们输出的特征。[65,66]将该网络的高层划分到一个NIR层,一个VIS层和一个NIR-VIS共享层;然后,通过NIR-VIs共享层学习一个模态不变特征。[144]将交叉光谱人脸幻视和判别性特征学习嵌入到一个端到端的对抗网络中。在[181]中,低秩相关和交叉模态排序用来缓解该语义鸿沟。
低分辨率人脸识别:虽然深度网络对于低分辨率有一定的鲁棒性,仍他有一些文献研究如何提升低分辨率的FR。例如[207]提出一个有两个分叉结构的CNN(一个超分辨率网络和一个特征提取网络)去映射高和低分辨率图片到一个通用空间上,该空间中类内距离小于类间距离。
相片-素描人脸识别:照片-素描FR可以有助于法律人士快速进行嫌疑人认证。通常该领域的使用可以划分成两类:
- 一个是使用迁移学习去直接将照片匹配到素描上,这里深度网络受限使用一个照片人脸数据集去训练,然后使用小的素描数据集[51,110]去微调;
- 使用图像到图像的变换,将照片变换到素描上,或者将素描变换到照片上,然后在目标领域中进行FR。[211]将生成损失和判别性正则加到全卷积网络上实现相片到素描的变换。
[209]利用一个分支的全卷积神经网络(branched fully convolutional neural network, BFCN)去生成一个结构保留的素描和一个纹理保留的素描,然后将它们通过一个概率方法进行融合。近期,GAN在图片生成上获得了不小的轰动。[86,199,229]使用两个生成器\(G_A\)和\(G_B\),生成从相片到素描和素描到相片,图20

基于[229],[165]提出一个多对抗网络通过利用生成器网络中不同分辨率的特征图的隐式表征去避免伪造的图片。
6.3 多(单)媒体的人脸识别
low-shot人脸识别:
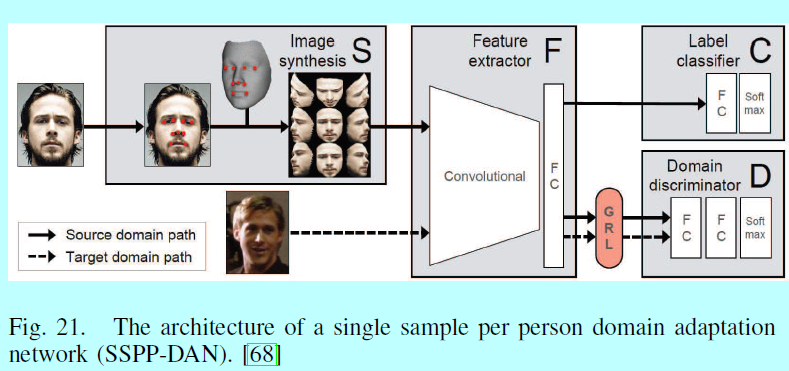
对于许多具体应用,如监控和安保,FR系统应该基于很少的训练样本或者一个ID一个样本进行训练。low-shot学习可以归类为增大训练数据和学习更强的特征。[68]使用3D模型去生成各个姿态的图像,然后适应深度领域去处理其他变化,例如模糊,遮挡和表情(图21).
[32]使用数据增强方法和GAN去做姿态变换和属性加速,以增大训练数据集的规模。[182]提出一个使用CNN和最近邻模型的混合分类器。[58]使用one-shot类和正常类的权重向量的范数对齐以解决数据不平衡问题。[30]提出一个增强softmax以包含最优dropout,选择性衰减,L2 归一化模型级别的优化。Yin[205]通过将主成分从常规类转移到low-shot类来增强low-shot类的特征空间,以鼓励low-shot类的方差来模拟常规类的方差。
set/template-based人脸识别:set/template-based FR问题假设测试样本和训练样本都是用媒体集来表示的如图像和视频,而不只是其中一个。在从每个媒体上独立的学习了表征集合,基于其应用两个不同的策略做FR:
- 使用这些表征做基于两个集合的相似性对比,然后将结果池化到一个,最终的得分,就和最大池化[108],平均池化[105]和它们的变种[220,17]。
- 通过平均或者最大池化将人脸表征融合起来,然后对每个集合生产一个单一表征,然后进行两个集合的对比,这里我们成为特征池化[28,108,132]。
另外,还有许多其他基于该方向的应用,如[62]提出一个深度异质特征融合网络来利用不同CNN生成的特征完备性信息。
视频人脸识别:视频人脸识别中有两个关键问题:
- 整合基于不同帧之间的信息去构建一个视频人脸的表征,
- 要处理视频自带的模糊,姿态变化和遮挡。
对于帧融合,[196]提出一个神经融合网络(neural aggregation network,nan ),在融合模块中,有基于一个memory驱动的两个注意力块,生成128维的特征向量,(图22).

Rao[125]直接基于度量学习和对抗学习进行组合,去融合原始视频帧。在处理坏帧时,[126]通过将该操作时为一个马尔可夫决策过程去丢弃该帧,然后通过一个深度强化学习框架去训练这个注意力模型。[47]人工去模糊清晰的图片,然后用来训练去学习模糊鲁棒性的人脸表征。Parchami[114]使用CNN用高质量人脸去重构一个低质量的视频。
6.4 工业界的人脸识别
3D人脸识别:3D FR继承了2D方法上的优势,但是3DFR没有太多深度网络的使用研究,主要是因为缺少大量的标签数据。为了增强3D训练数据集,大多数工作主要是使用"one-to-many增强"去合成3D人脸。然而,提取3D人脸的深度特征的高效方法依然需要探索。[84]基于少量的3D扫描去微调一个2DCNN。[235]使用一个3通道图像(对应正常向量的深度,方位和elevation 角度)作为输入然后最小化平均预测log-loss。[210]从candide-3人脸模型去选择30个特征点来属性化人脸,然后进行了无监督的人脸深度数据预训练和有监督微调。
人脸反欺骗:随着FR技术的成功,伴随的是各种欺骗攻击,比如打印欺骗,视频播放欺骗,3D面具欺骗等等。人脸反欺骗也成了识别人脸是否是活的一个重要部分。因为他同时需要识别人脸(真还是假ID),所以我们将它看成是一种FR场景。[8]提出一个新颖的两流CNN,其中局部特征独立于空间人脸区域的判别欺骗图像块,整体深度图确保输入的活体样本具有类似面部的深度。[190]提出一个LSTM-CNN结构,学习时序特征去联合预测一个视频中多个人脸。[91,117]在一个包含了真,假人脸数据集上微调一个预训练的模型。
移动端人脸识别:随着手机的出现,平板电脑和增强现实,FR已应用于移动设备。因为计算力的限制,在这些设备中的识别任务需要轻量级而且实时的运行。基于之前提到的[33,69,76,217]提出了轻量级的深度网络,这些网络可以用在这里的场景。[152]提出一个人多batch方法,首先生成k个人脸的batch,然后基于这个minibatch,通过依赖所有\(k_2-k\)对构建一个全梯度的无偏估计。
7 总结
[139,140]对如何减少人脸欺骗做了一些 工作
[166]关于深度领域适应值得关注。
参考文献:
- Wang M, Deng W. Deep Face Recognition: A Survey[J]. arXiv preprint arXiv:1804.06655, 2018.
- Li, Pei, et al. "Face Recognition in Low Quality Images: A Survey." arXiv preprint arXiv:1805.11519 (2018).
- Sneha, Sanjay Sharma. "Face Recognition Techniques: A Survey." (2018).
- Changxing Ding, Dacheng Tao. A Comprehensive Survey on Pose-Invariant Face Recognition[J]. arXiv preprint arXiv:1502.04383, 2015.
- Shuxin Ouyang, Timothy Hospedales, Yi-Zhe Song, Xueming Li. A Survey on Heterogeneous Face Recognition: Sketch, Infra-red, 3D and Low-resolution[J]. arXiv preprint arXiv:1409.5114, 2014.
- D. Johnvictor, G. Selvavinayagam. Survey on Sparse Coded Features for Content Based Face Image Retrieval[J]. arXiv preprint arXiv:1402.4888, 2014.
[1] Fg-net aging database. http://www.fgnet.rsunit.com.
[2] Ms-celeb-1m challenge 3. http://trillionpairs.deepglint.com.
[3] A. F. Abate, M. Nappi, D. Riccio, and G. Sabatino. 2d and 3d face recognition: A survey. Pattern recognition letters, 28(14):1885–1906, 2007.
[4] W. Abdalmageed, Y. Wu, S. Rawls, S. Harel, T. Hassner, I. Masi, J. Choi, J. Lekust, J. Kim, and P. Natarajan. Face recognition using deep multi-pose representations. In WACV, pages 1–9, 2016.
[5] T. Ahonen, A. Hadid, and M. Pietikainen. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Machine Intell., 28(12):2037–2041, 2006.
[6] G. Antipov, M. Baccouche, and J.-L. Dugelay. Boosting cross-age face verification via generative age normalization. In IJCB, 2017.
[7] G. Antipov, M. Baccouche, and J.-L. Dugelay. Face aging with conditional generative adversarial networks. arXiv preprint arXiv:1702.01983, 2017.
[8] Y. Atoum, Y. Liu, A. Jourabloo, and X. Liu. Face anti-spoofing using patch and depth-based cnns. In IJCB, pages 319–328. IEEE, 2017.
[9] A. Bansal, C. Castillo, R. Ranjan, and R. Chellappa. The dos and donts for cnn-based face verification. arXiv preprint arXiv:1705.07426, 5, 2017.
[10] A. Bansal, A. Nanduri, C. Castillo, R. Ranjan, and R. Chellappa. Umdfaces: An annotated face dataset for training deep networks. arXiv preprint arXiv:1611.01484, 2016.
[11] J. Bao, D. Chen, F. Wen, H. Li, and G. Hua. Cvae-gan: finegrained image generation through asymmetric training. arXiv preprint arXiv:1703.10155, 2017.
[12] J. Bao, D. Chen, F. Wen, H. Li, and G. Hua. Towards open-set identity preserving face synthesis. In CVPR, pages 6713–6722, 2018.
[13] P. N. Belhumeur, J. P. Hespanha, and D. J. Kriegman. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell., 19(7):711–720, 1997.
[14] J. R. Beveridge, P. J. Phillips, D. S. Bolme, B. A. Draper, G. H. Givens, Y. M. Lui, M. N. Teli, H. Zhang, W. T. Scruggs, K. W. Bowyer, et al. The challenge of face recognition from digital point-and-shoot cameras. In BTAS, pages 1–8. IEEE, 2013.
[15] S. Bianco. Large age-gap face verification by feature injection in deep networks. Pattern Recognition Letters, 90:36–42, 2017.
[16] V. Blanz and T. Vetter. Face recognition based on fitting a 3d morphable model. IEEE Transactions on pattern analysis and machine intelligence, 25(9):1063–1074, 2003.
[17] N. Bodla, J. Zheng, H. Xu, J.-C. Chen, C. Castillo, and R. Chellappa. Deep heterogeneous feature fusion for template-based face recognition. In WACV, pages 586–595. IEEE, 2017.
[18] K. W. Bowyer, K. Chang, and P. Flynn. A survey of approaches and challenges in 3d and multi-modal 3d+ 2d face recognition. Computer vision and image understanding, 101(1):1–15, 2006.
[19] K. Cao, Y. Rong, C. Li, X. Tang, and C. C. Loy. Pose-robust face recognition via deep residual equivariant mapping. arXiv preprint arXiv:1803.00839, 2018.
[20] Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman. Vggface2: A dataset for recognising faces across pose and age. arXiv preprint arXiv:1710.08092, 2017.
[21] Z. Cao, Q. Yin, X. Tang, and J. Sun. Face recognition with learningbased descriptor. In CVPR, pages 2707–2714. IEEE, 2010.
[22] T.-H. Chan, K. Jia, S. Gao, J. Lu, Z. Zeng, and Y. Ma. Pcanet: A simple deep learning baseline for image classification? IEEE Transactions on Image Processing, 24(12):5017–5032, 2015.
[23] B. Chen, W. Deng, and J. Du. Noisy softmax: improving the generalization ability of dcnn via postponing the early softmax saturation. arXiv preprint arXiv:1708.03769, 2017.
[24] B.-C. Chen, C.-S. Chen, and W. H. Hsu. Cross-age reference coding for age-invariant face recognition and retrieval. In ECCV, pages 768–783. Springer, 2014.
[25] D. Chen, X. Cao, L. Wang, F. Wen, and J. Sun. Bayesian face revisited: A joint formulation. In ECCV, pages 566–579. Springer, 2012.
[26] D. Chen, X. Cao, F. Wen, and J. Sun. Blessing of dimensionality: Highdimensional feature and its efficient compression for face verification. In CVPR, pages 3025–3032, 2013.
[27] G. Chen, Y. Shao, C. Tang, Z. Jin, and J. Zhang. Deep transformation learning for face recognition in the unconstrained scene. Machine Vision and Applications, pages 1–11, 2018.
[28] J.-C. Chen, V. M. Patel, and R. Chellappa. Unconstrained face verification using deep cnn features. In WACV, pages 1–9. IEEE, 2016.
[29] J.-C. Chen, R. Ranjan, A. Kumar, C.-H. Chen, V. M. Patel, and R. Chellappa. An end-to-end system for unconstrained face verification with deep convolutional neural networks. In ICCV Workshops, pages 118–126, 2015.
[30] Y. Cheng, J. Zhao, Z. Wang, Y. Xu, K. Jayashree, S. Shen, and J. Feng. Know you at one glance: A compact vector representation for low-shot learning. In CVPR, pages 1924–1932, 2017.
[31] I. Chingovska, A. Anjos, and S. Marcel. On the effectiveness of local binary patterns in face anti-spoofing. 2012.
[32] J. Choe, S. Park, K. Kim, J. H. Park, D. Kim, and H. Shim. Face generation for low-shot learning using generative adversarial networks. In ICCV Workshops, pages 1940–1948. IEEE, 2017.
[33] F. Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv preprint, 2016.
[34] A. R. Chowdhury, T.-Y. Lin, S. Maji, and E. Learned-Miller. One-tomany face recognition with bilinear cnns. In WACV, pages 1–9. IEEE, 2016.
[35] F. Cole, D. Belanger, D. Krishnan, A. Sarna, I. Mosseri, and W. T. Freeman. Synthesizing normalized faces from facial identity features. In CVPR, pages 3386–3395, 2017.
[36] N. Crosswhite, J. Byrne, C. Stauffer, O. Parkhi, Q. Cao, and A. Zisserman. Template adaptation for face verification and identification. In FG 2017, pages 1–8, 2017.
[37] J. Deng, S. Cheng, N. Xue, Y. Zhou, and S. Zafeiriou. Uv-gan: Adversarial facial uv map completion for pose-invariant face recognition. arXiv preprint arXiv:1712.04695, 2017.
[38] J. Deng, J. Guo, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. arXiv preprint arXiv:1801.07698, 2018.
[39] J. Deng, Y. Zhou, and S. Zafeiriou. Marginal loss for deep face recognition. In CVPR Workshops, volume 4, 2017.
[40] W. Deng, J. Hu, and J. Guo. Extended src: Undersampled face recognition via intraclass variant dictionary. IEEE Trans. Pattern Anal. Machine Intell., 34(9):1864–1870, 2012.
[41] W. Deng, J. Hu, and J. Guo. Compressive binary patterns: Designing a robust binary face descriptor with random-field eigenfilters. IEEE Trans. Pattern Anal. Mach. Intell., PP(99):1–1, 2018.
[42] W. Deng, J. Hu, and J. Guo. Face recognition via collaborative representation: Its discriminant nature and superposed representation. IEEE Trans. Pattern Anal. Mach. Intell., PP(99):1–1, 2018.
[43] W. Deng, J. Hu, J. Guo, H. Zhang, and C. Zhang. Comments on “globally maximizing, locally minimizing: Unsupervised discriminant projection with applications to face and palm biometrics”. IEEE Trans. Pattern Anal. Mach. Intell., 30(8):1503–1504, 2008.
[44] W. Deng, J. Hu, J. Lu, and J. Guo. Transform-invariant pca: A unified approach to fully automatic facealignment, representation, and recognition. IEEE Trans. Pattern Anal. Mach. Intell., 36(6):1275–1284, June 2014.
[45] W. Deng, J. Hu, N. Zhang, B. Chen, and J. Guo. Fine-grained face verification: Fglfw database, baselines, and human-dcmn partnership. Pattern Recognition, 66:63–73, 2017.
[46] C. Ding and D. Tao. Robust face recognition via multimodal deep face representation. IEEE Transactions on Multimedia, 17(11):2049–2058, 2015.
[47] C. Ding and D. Tao. Trunk-branch ensemble convolutional neural networks for video-based face recognition. IEEE transactions on pattern analysis and machine intelligence, 2017.
[48] P. Dou, S. K. Shah, and I. A. Kakadiaris. End-to-end 3d face reconstruction with deep neural networks. In CVPR, volume 5, 2017.
[49] C. N. Duong, K. G. Quach, K. Luu, M. Savvides, et al. Temporal nonvolume preserving approach to facial age-progression and age-invariant face recognition. arXiv preprint arXiv:1703.08617, 2017.
[50] H. El Khiyari and H. Wechsler. Age invariant face recognition using convolutional neural networks and set distances. Journal of Information Security, 8(03):174, 2017.
[51] C. Galea and R. A. Farrugia. Forensic face photo-sketch recognition using a deep learning-based architecture. IEEE Signal Processing Letters, 24(11):1586–1590, 2017.
[52] M. M. Ghazi and H. K. Ekenel. A comprehensive analysis of deep learning based representation for face recognition. In CVPR Workshops, volume 26, pages 34–41, 2016.
[53] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, pages 2672–2680, 2014.
[54] P. J. Grother and L. N. Mei. Face recognition vendor test (frvt) performance of face identification algorithms nist ir 8009. NIST Interagency/Internal Report (NISTIR) - 8009, 2014.
[55] G. Guo, L. Wen, and S. Yan. Face authentication with makeup changes. IEEE Transactions on Circuits and Systems for Video Technology, 24(5):814–825, 2014.
[56] S. Guo, S. Chen, and Y. Li. Face recognition based on convolutional neural network and support vector machine. In IEEE International Conference on Information and Automation, pages 1787–1792, 2017.
[57] Y. Guo, J. Zhang, J. Cai, B. Jiang, and J. Zheng. 3dfacenet: Real-time dense face reconstruction via synthesizing photo-realistic face images. 2017.
[58] Y. Guo and L. Zhang. One-shot face recognition by promoting underrepresented classes. arXiv preprint arXiv:1707.05574, 2017.
[59] Y. Guo, L. Zhang, Y. Hu, X. He, and J. Gao. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In ECCV, pages 87– 102. Springer, 2016.
[60] A. Hasnat, J. Bohn´e, J. Milgram, S. Gentric, and L. Chen. Deepvisage: Making face recognition simple yet with powerful generalization skills. arXiv preprint arXiv:1703.08388, 2017.
[61] M. Hasnat, J. Bohn´e, J. Milgram, S. Gentric, L. Chen, et al. von mises-fisher mixture model-based deep learning: Application to face verification. arXiv preprint arXiv:1706.04264, 2017.
[62] M. Hayat, M. Bennamoun, and S. An. Learning non-linear reconstruction models for image set classification. In CVPR, pages 1907–1914, 2014.
[63] M. Hayat, S. H. Khan, N. Werghi, and R. Goecke. Joint registration and representation learning for unconstrained face identification. In CVPR, pages 2767–2776, 2017.
[64] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
[65] R. He, X. Wu, Z. Sun, and T. Tan. Learning invariant deep representation for nir-vis face recognition. In AAAI, volume 4, page 7, 2017.
[66] R. He, X. Wu, Z. Sun, and T. Tan. Wasserstein cnn: Learning invariant features for nir-vis face recognition. arXiv preprint arXiv:1708.02412, 2017.
[67] X. He, S. Yan, Y. Hu, P. Niyogi, and H.-J. Zhang. Face recognition using laplacianfaces. IEEE Trans. Pattern Anal. Mach. Intell., 27(3):328–340, 2005.
[68] S. Hong, W. Im, J. Ryu, and H. S. Yang. Sspp-dan: Deep domain adaptation network for face recognition with single sample per person. arXiv preprint arXiv:1702.04069, 2017.
[69] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017.
[70] G. Hu, Y. Yang, D. Yi, J. Kittler, W. Christmas, S. Z. Li, and T. Hospedales. When face recognition meets with deep learning: an evaluation of convolutional neural networks for face recognition. In ICCV workshops, pages 142–150, 2015.
[71] J. Hu, Y. Ge, J. Lu, and X. Feng. Makeup-robust face verification. In ICASSP, pages 2342–2346. IEEE, 2013.
[72] J. Hu, L. Shen, and G. Sun. Squeeze-and-excitation networks. arXiv preprint arXiv:1709.01507, 2017.
[73] L. Hu, M. Kan, S. Shan, X. Song, and X. Chen. Ldf-net: Learning a displacement field network for face recognition across pose. In FG 2017, pages 9–16. IEEE, 2017.
[74] G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. Technical report, Technical Report 07-49, University of Massachusetts, Amherst, 2007.
[75] R. Huang, S. Zhang, T. Li, R. He, et al. Beyond face rotation: Global and local perception gan for photorealistic and identity preserving frontal view synthesis. arXiv preprint arXiv:1704.04086, 2017.
[76] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size. arXiv preprint arXiv:1602.07360, 2016.
[77] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In NIPS, pages 2017–2025, 2015.
[78] R. Jafri and H. R. Arabnia. A survey of face recognition techniques. Jips, 5(2):41–68, 2009.
[79] H. Jegou, M. Douze, and C. Schmid. Product quantization for nearest neighbor search. IEEE Transactions on Pattern Analysis & Machine Intelligence, 33(1):117, 2011.
[80] M. Kan, S. Shan, H. Chang, and X. Chen. Stacked progressive autoencoders (spae) for face recognition across poses. In CVPR, pages 1883–1890, 2014.
[81] M. Kan, S. Shan, and X. Chen. Bi-shifting auto-encoder for unsupervised domain adaptation. In ICCV, pages 3846–3854, 2015.
[82] M. Kan, S. Shan, and X. Chen. Multi-view deep network for cross-view classification. In CVPR, pages 4847–4855, 2016.
[83] I. Kemelmacher-Shlizerman, S. M. Seitz, D. Miller, and E. Brossard. The megaface benchmark: 1 million faces for recognition at scale. In CVPR, pages 4873–4882, 2016.
[84] D. Kim, M. Hernandez, J. Choi, and G. Medioni. Deep 3d face identification. arXiv preprint arXiv:1703.10714, 2017.
[85] M. Kim, S. Kumar, V. Pavlovic, and H. Rowley. Face tracking and recognition with visual constraints in real-world videos. In CVPR, pages 1–8. IEEE, 2008.
[86] T. Kim, M. Cha, H. Kim, J. Lee, and J. Kim. Learning to discover crossdomain relations with generative adversarial networks. arXiv preprint arXiv:1703.05192, 2017.
[87] B. F. Klare, B. Klein, E. Taborsky, A. Blanton, J. Cheney, K. Allen, P. Grother, A. Mah, and A. K. Jain. Pushing the frontiers of unconstrained face detection and recognition: Iarpa janus benchmark a. In CVPR, pages 1931–1939, 2015.
[88] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, pages 1097–1105, 2012.
[89] Z. Lei, M. Pietikainen, and S. Z. Li. Learning discriminant face descriptor. IEEE Trans. Pattern Anal. Machine Intell., 36(2):289–302, 2014.
[90] J. Lezama, Q. Qiu, and G. Sapiro. Not afraid of the dark: Nir-vis face recognition via cross-spectral hallucination and low-rank embedding. In CVPR, pages 6807–6816. IEEE, 2017.
[91] L. Li, X. Feng, Z. Boulkenafet, Z. Xia, M. Li, and A. Hadid. An original face anti-spoofing approach using partial convolutional neural network. In IPTA, pages 1–6. IEEE, 2016.
[92] S. Z. Li, D. Yi, Z. Lei, and S. Liao. The casia nir-vis 2.0 face database. In CVPR workshops, pages 348–353. IEEE, 2013.
[93] S. Z. Li, L. Zhen, and A. Meng. The hfb face database for heterogeneous face biometrics research. In CVPR Workshops, pages 1–8, 2009.
[94] Y. Li, L. Song, X. Wu, R. He, and T. Tan. Anti-makeup: Learning a bi-level adversarial network for makeup-invariant face verification. arXiv preprint arXiv:1709.03654, 2017.
[95] Y. Li, G. Wang, L. Nie, Q. Wang, and W. Tan. Distance metric optimization driven convolutional neural network for age invariant face recognition. Pattern Recognition, 75:51–62, 2018.
[96] L. Lin, G. Wang, W. Zuo, X. Feng, and L. Zhang. Cross-domain visual matching via generalized similarity measure and feature learning. IEEE Transactions on Pattern Analysis & Machine Intelligence, 39(6):1089– 1102, 2016.
[97] T.-Y. Lin, A. RoyChowdhury, and S. Maji. Bilinear cnn models for fine-grained visual recognition. In ICCV, pages 1449–1457, 2015.
[98] C. Liu and H. Wechsler. Gabor feature based classification using the enhanced fisher linear discriminant model for face recognition. Image processing, IEEE Transactions on, 11(4):467–476, 2002.
[99] J. Liu, Y. Deng, T. Bai, Z. Wei, and C. Huang. Targeting ultimate accuracy: Face recognition via deep embedding. arXiv preprint arXiv:1506.07310, 2015.
[100] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. Sphereface: Deep hypersphere embedding for face recognition. In CVPR, volume 1, 2017.
[101] W. Liu, Y. Wen, Z. Yu, and M. Yang. Large-margin softmax loss for convolutional neural networks. In ICML, pages 507–516, 2016.
[102] W. Liu, Y.-M. Zhang, X. Li, Z. Yu, B. Dai, T. Zhao, and L. Song. Deep hyperspherical learning. In NIPS, pages 3953–3963, 2017.
[103] X. Liu, L. Song, X. Wu, and T. Tan. Transferring deep representation for nir-vis heterogeneous face recognition. In ICB, pages 1–8. IEEE, 2016.
[104] Y. Liu, H. Li, and X. Wang. Rethinking feature discrimination and polymerization for large-scale recognition. arXiv preprint arXiv:1710.00870, 2017.
[105] J. Lu, G. Wang, W. Deng, P. Moulin, and J. Zhou. Multi-manifold deep metric learning for image set classification. In CVPR, pages 1137–1145, 2015.
[106] A. M. Martinez. The ar face database. CVC Technical Report24, 1998.
[107] I. Masi, T. Hassner, A. T. Tran, and G. Medioni. Rapid synthesis of massive face sets for improved face recognition. In FG 2017, pages 604–611. IEEE, 2017.
[108] I. Masi, S. Rawls, G. Medioni, and P. Natarajan. Pose-aware face recognition in the wild. In CVPR, pages 4838–4846, 2016.
[109] I. Masi, A. T. Tr?n, T. Hassner, J. T. Leksut, and G. Medioni. Do we really need to collect millions of faces for effective face recognition? In ECCV, pages 579–596. Springer, 2016.
[110] P. Mittal, M. Vatsa, and R. Singh. Composite sketch recognition via deep network-a transfer learning approach. In ICB, pages 251–256. IEEE, 2015.
[111] B. Moghaddam, W. Wahid, and A. Pentland. Beyond eigenfaces: probabilistic matching for face recognition. Automatic Face and Gesture Recognition, 1998. Proc. Third IEEE Int. Conf., pages 30–35, Apr 1998.
[112] A. Nech and I. Kemelmacher-Shlizerman. Level playing field for million scale face recognition. In CVPR, pages 3406–3415. IEEE, 2017.
[113] S. J. Pan and Q. Yang. A survey on transfer learning. IEEE Transactions on knowledge and data engineering, 22(10):1345–1359, 2010.
[114] M. Parchami, S. Bashbaghi, E. Granger, and S. Sayed. Using deep autoencoders to learn robust domain-invariant representations for stillto- video face recognition. In AVSS, pages 1–6. IEEE, 2017.
[115] C. J. Parde, C. Castillo, M. Q. Hill, Y. I. Colon, S. Sankaranarayanan, J.-C. Chen, and A. J. O’Toole. Deep convolutional neural network features and the original image. arXiv preprint arXiv:1611.01751, 2016.
[116] O. M. Parkhi, A. Vedaldi, A. Zisserman, et al. Deep face recognition. In BMVC, volume 1, page 6, 2015.
[117] K. Patel, H. Han, and A. K. Jain. Cross-database face antispoofing with robust feature representation. In Chinese Conference on Biometric Recognition, pages 611–619. Springer, 2016.
[118] X. Peng, X. Yu, K. Sohn, D. N. Metaxas, and M. Chandraker. Reconstruction-based disentanglement for pose-invariant face recognition. intervals, 20:12, 2017.
[119] P. J. Phillips, P. J. Flynn, T. Scruggs, K. W. Bowyer, J. Chang, K. Hoffman, J. Marques, J. Min, and W. Worek. Overview of the face recognition grand challenge. In CVPR, volume 1, pages 947–954. IEEE, 2005.
[120] P. J. Phillips, H. Wechsler, J. Huang, and P. J. Rauss. The feret database and evaluation procedure for face-recognition algorithms. Image & Vision Computing J, 16(5):295–306, 1998.
[121] X. Qi and L. Zhang. Face recognition via centralized coordinate learning. arXiv preprint arXiv:1801.05678, 2018.
[122] R. Ranjan, C. D. Castillo, and R. Chellappa. L2-constrained softmax loss for discriminative face verification. arXiv preprint arXiv:1703.09507, 2017.
[123] R. Ranjan, S. Sankaranarayanan, A. Bansal, N. Bodla, J. C. Chen, V. M. Patel, C. D. Castillo, and R. Chellappa. Deep learning for understanding faces: Machines may be just as good, or better, than humans. IEEE Signal Processing Magazine, 35(1):66–83, 2018.
[124] R. Ranjan, S. Sankaranarayanan, C. D. Castillo, and R. Chellappa. An all-in-one convolutional neural network for face analysis. In FG 2017, pages 17–24. IEEE, 2017.
[125] Y. Rao, J. Lin, J. Lu, and J. Zhou. Learning discriminative aggregation network for video-based face recognition. In CVPR, pages 3781–3790, 2017.
[126] Y. Rao, J. Lu, and J. Zhou. Attention-aware deep reinforcement learning for video face recognition. In CVPR, pages 3931–3940, 2017.
[127] C. Reale, N. M. Nasrabadi, H. Kwon, and R. Chellappa. Seeing the forest from the trees: A holistic approach to near-infrared heterogeneous face recognition. In CVPR Workshops, pages 320–328. IEEE, 2016.
[128] K. Ricanek and T. Tesafaye. Morph: A longitudinal image database of normal adult age-progression. In FGR, pages 341–345. IEEE, 2006.
[129] E. Richardson, M. Sela, and R. Kimmel. 3d face reconstruction by learning from synthetic data. In 3DV, pages 460–469. IEEE, 2016.
[130] E. Richardson, M. Sela, R. Or-El, and R. Kimmel. Learning detailed face reconstruction from a single image. In CVPR, pages 5553–5562. IEEE, 2017.
[131] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3):211–252, 2015.
[132] S. Sankaranarayanan, A. Alavi, C. D. Castillo, and R. Chellappa. Triplet probabilistic embedding for face verification and clustering. In BTAS, pages 1–8. IEEE, 2016.
[133] S. Sankaranarayanan, A. Alavi, and R. Chellappa. Triplet similarity embedding for face verification. arXiv preprint arXiv:1602.03418, 2016.
[134] A. Savran, N. Aly¨uz, H. Dibeklio˘glu, O. C¸ eliktutan, B. G¨okberk, B. Sankur, and L. Akarun. Bosphorus database for 3d face analysis. In European Workshop on Biometrics and Identity Management, pages 47–56. Springer, 2008.
[135] S. Saxena and J. Verbeek. Heterogeneous face recognition with cnns. In ECCV, pages 483–491. Springer, 2016.
[136] A. Scheenstra, A. Ruifrok, and R. C. Veltkamp. A survey of 3d face recognition methods. In International Conference on Audio-and Videobased Biometric Person Authentication, pages 891–899. Springer, 2005.
[137] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, pages 815– 823, 2015.
[138] S. Sengupta, J.-C. Chen, C. Castillo, V. M. Patel, R. Chellappa, and D. W. Jacobs. Frontal to profile face verification in the wild. In WACV, pages 1–9. IEEE, 2016.
[139] M. Sharif, S. Bhagavatula, L. Bauer, and M. K. Reiter. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pages 1528–1540. ACM, 2016.
[140] M. Sharif, S. Bhagavatula, L. Bauer, and M. K. Reiter. Adversarial generative nets: Neural network attacks on state-of-the-art face recognition. arXiv preprint arXiv:1801.00349, 2017.
[141] A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb. Learning from simulated and unsupervised images through adversarial training. In CVPR, volume 3, page 6, 2017.
[142] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
[143] K. Sohn, S. Liu, G. Zhong, X. Yu, M.-H. Yang, and M. Chandraker. Unsupervised domain adaptation for face recognition in unlabeled videos. arXiv preprint arXiv:1708.02191, 2017.
[144] L. Song, M. Zhang, X. Wu, and R. He. Adversarial discriminative heterogeneous face recognition. arXiv preprint arXiv:1709.03675, 2017.
[145] Y. Sun, Y. Chen, X. Wang, and X. Tang. Deep learning face representation by joint identification-verification. In NIPS, pages 1988– 1996, 2014.
[146] Y. Sun, D. Liang, X. Wang, and X. Tang. Deepid3: Face recognition with very deep neural networks. arXiv preprint arXiv:1502.00873, 2015.
[147] Y. Sun, L. Ren, Z. Wei, B. Liu, Y. Zhai, and S. Liu. A weakly supervised method for makeup-invariant face verification. Pattern Recognition, 66:153–159, 2017.
[148] Y. Sun, X. Wang, and X. Tang. Hybrid deep learning for face verification. In ICCV, pages 1489–1496. IEEE, 2013.
[149] Y. Sun, X. Wang, and X. Tang. Deep learning face representation from predicting 10,000 classes. In CVPR, pages 1891–1898, 2014.
[150] Y. Sun, X. Wang, and X. Tang. Sparsifying neural network connections for face recognition. In CVPR, pages 4856–4864, 2016.
[151] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, et al. Going deeper with convolutions. Cvpr, 2015.
[152] O. Tadmor, Y. Wexler, T. Rosenwein, S. Shalev-Shwartz, and A. Shashua. Learning a metric embedding for face recognition using the multibatch method. arXiv preprint arXiv:1605.07270, 2016.
[153] Y. Taigman, M. Yang, M. Ranzato, and L. Wolf. Deepface: Closing the gap to human-level performance in face verification. In CVPR, pages 1701–1708, 2014.
[154] A. Tewari, M. Zollh¨ofer, H. Kim, P. Garrido, F. Bernard, P. Perez, and C. Theobalt. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction. In ICCV, volume 2, 2017.
[155] A. T. Tran, T. Hassner, I. Masi, and G. Medioni. Regressing robust and discriminative 3d morphable models with a very deep neural network. In CVPR, pages 1493–1502. IEEE, 2017.
[156] L. Tran, X. Yin, and X. Liu. Disentangled representation learning gan for pose-invariant face recognition. In CVPR, volume 3, page 7, 2017.
[157] M. Turk and A. Pentland. Eigenfaces for recognition. Journal of cognitive neuroscience, 3(1):71–86, 1991.
[158] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In CVPR, volume 1, page 4, 2017.
[159] C. Wang, X. Lan, and X. Zhang. How to train triplet networks with 100k identities? In ICCV workshops, volume 00, pages 1907–1915, 2017.
[160] D. Wang, C. Otto, and A. K. Jain. Face search at scale: 80 million gallery. arXiv preprint arXiv:1507.07242, 2015.
[161] D. Wang, C. Otto, and A. K. Jain. Face search at scale. IEEE transactions on pattern analysis and machine intelligence, 39(6):1122– 1136, 2017.
[162] F. Wang, W. Liu, H. Liu, and J. Cheng. Additive margin softmax for face verification. arXiv preprint arXiv:1801.05599, 2018.
[163] F. Wang, X. Xiang, J. Cheng, and A. L. Yuille. Normface: l 2 hypersphere embedding for face verification. arXiv preprint arXiv:1704.06369, 2017.
[164] H. Wang, Y. Wang, Z. Zhou, X. Ji, Z. Li, D. Gong, J. Zhou, and W. Liu. Cosface: Large margin cosine loss for deep face recognition. arXiv preprint arXiv:1801.09414, 2018.
[165] L. Wang, V. A. Sindagi, and V. M. Patel. High-quality facial photosketch synthesis using multi-adversarial networks. arXiv preprint arXiv:1710.10182, 2017.
[166] M. Wang and W. Deng. Deep visual domain adaptation: A survey. arXiv preprint arXiv:1802.03601, 2018.
[167] W. Wang, Z. Cui, H. Chang, S. Shan, and X. Chen. Deeply coupled auto-encoder networks for cross-view classification. arXiv preprint arXiv:1402.2031, 2014.
[168] X. Wang and X. Tang. Face photo-sketch synthesis and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(11):1955–1967, 2009.
[169] X. Wang, Y. Zhou, D. Kong, J. Currey, D. Li, and J. Zhou. Unleash the black magic in age: a multi-task deep neural network approach for cross-age face verification. In FG 2017, pages 596–603. IEEE, 2017.
[170] W. D. Weilong Chai and H. Shen. Cross-generating gan for facial identity preserving. In FG, pages 130–134. IEEE, 2018.
[171] K. Q. Weinberger and L. K. Saul. Distance metric learning for large margin nearest neighbor classification. Journal of Machine Learning Research, 10(Feb):207–244, 2009.
[172] Y. Wen, Z. Li, and Y. Qiao. Latent factor guided convolutional neural networks for age-invariant face recognition. In CVPR, pages 4893– 4901, 2016.
[173] Y. Wen, K. Zhang, Z. Li, and Y. Qiao. A discriminative feature learning approach for deep face recognition. In ECCV, pages 499–515. Springer, 2016.
[174] C. Whitelam, K. Allen, J. Cheney, P. Grother, E. Taborsky, A. Blanton, B. Maze, J. Adams, T. Miller, and N. Kalka. Iarpa janus benchmark-b face dataset. In CVPR Workshops, pages 592–600, 2017.
[175] L. Wolf, T. Hassner, and I. Maoz. Face recognition in unconstrained videos with matched background similarity. In CVPR, pages 529–534. IEEE, 2011.
[176] J. Wright, A. Yang, A. Ganesh, S. Sastry, and Y. Ma. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Machine Intell., 31(2):210–227, 2009.
[177] W.-S. T. WST. Deeply learned face representations are sparse, selective, and robust. perception, 31:411–438, 2008.
[178] W. Wu, M. Kan, X. Liu, Y. Yang, S. Shan, and X. Chen. Recursive spatial transformer (rest) for alignment-free face recognition. In CVPR, pages 3772–3780, 2017.
[179] X. Wu, R. He, and Z. Sun. A lightened cnn for deep face representation. In CVPR, volume 4, 2015.
[180] X. Wu, R. He, Z. Sun, and T. Tan. A light cnn for deep face representation with noisy labels. arXiv preprint arXiv:1511.02683, 2015.
[181] X. Wu, L. Song, R. He, and T. Tan. Coupled deep learning for heterogeneous face recognition. arXiv preprint arXiv:1704.02450, 2017.
[182] Y. Wu, H. Liu, and Y. Fu. Low-shot face recognition with hybrid classifiers. In CVPR, pages 1933–1939, 2017.
[183] Y. Wu, H. Liu, J. Li, and Y. Fu. Deep face recognition with center invariant loss. In Proceedings of the on Thematic Workshops of ACM Multimedia 2017, pages 408–414. ACM, 2017.
[184] S. Xie and Z. Tu. Holistically-nested edge detection. In ICCV, pages 1395–1403, 2015.
[185] E. P. Xing, M. I. Jordan, S. J. Russell, and A. Y. Ng. Distance metric learning with application to clustering with side-information. In NIPS, pages 521–528, 2003.
[186] C. Xiong, X. Zhao, D. Tang, K. Jayashree, S. Yan, and T.-K. Kim. Conditional convolutional neural network for modality-aware face recognition. In ICCV, pages 3667–3675. IEEE, 2015.
[187] L. Xiong, J. Karlekar, J. Zhao, J. Feng, S. Pranata, and S. Shen. A good practice towards top performance of face recognition: Transferred deep feature fusion. arXiv preprint arXiv:1704.00438, 2017.
[188] Y. Xu, Y. Cheng, J. Zhao, Z. Wang, L. Xiong, K. Jayashree, H. Tamura, T. Kagaya, S. Pranata, S. Shen, J. Feng, and J. Xing. High performance large scale face recognition with multi-cognition softmax and feature retrieval. In ICCV workshops, volume 00, pages 1898–1906, 2017.
[189] Y. Xu, S. Shen, J. Feng, J. Xing, Y. Cheng, J. Zhao, Z. Wang, L. Xiong, K. Jayashree, and H. Tamura. High performance large scale face recognition with multi-cognition softmax and feature retrieval. In ICCV Workshop, pages 1898–1906, 2017.
[190] Z. Xu, S. Li, and W. Deng. Learning temporal features using lstm-cnn architecture for face anti-spoofing. In ACPR, pages 141–145. IEEE, 2015.
[191] S. Yan, D. Xu, B. Zhang, and H.-J. Zhang. Graph embedding: A general framework for dimensionality reduction. Computer Vision and Pattern Recognition, IEEE Computer Society Conference on, 2:830–837, 2005.
[192] H. Yang, D. Huang, Y. Wang, and A. K. Jain. Learning face age progression: A pyramid architecture of gans. arXiv preprint arXiv:1711.10352, 2017.
[193] H. Yang and I. Patras. Mirror, mirror on the wall, tell me, is the error small? In CVPR, pages 4685–4693, 2015.
[194] J. Yang, Z. Lei, and S. Z. Li. Learn convolutional neural network for face anti-spoofing. arXiv preprint arXiv:1408.5601, 2014.
[195] J. Yang, S. E. Reed, M.-H. Yang, and H. Lee. Weakly-supervised disentangling with recurrent transformations for 3d view synthesis. In NIPS, pages 1099–1107, 2015.
[196] J. Yang, P. Ren, D. Chen, F. Wen, H. Li, and G. Hua. Neural aggregation network for video face recognition. arXiv preprint arXiv:1603.05474, 2016.
[197] M. Yang, X. Wang, G. Zeng, and L. Shen. Joint and collaborative representation with local adaptive convolution feature for face recognition with single sample per person. Pattern Recognition, 66(C):117–128, 2016.
[198] D. Yi, Z. Lei, S. Liao, and S. Z. Li. Learning face representation from scratch. arXiv preprint arXiv:1411.7923, 2014.
[199] Z. Yi, H. Zhang, P. Tan, and M. Gong. Dualgan: Unsupervised dual learning for image-to-image translation. arXiv preprint, 2017.
[200] J. H. Yichen Qian, Weihong Deng. Task specific networks for identity and face variation. In FG, pages 271–277. IEEE, 2018.
[201] J. Yim, H. Jung, B. Yoo, C. Choi, D. Park, and J. Kim. Rotating your face using multi-task deep neural network. In CVPR, pages 676–684, 2015.
[202] L. Yin, X. Wei, Y. Sun, J. Wang, and M. J. Rosato. A 3d facial expression database for facial behavior research. In FGR, pages 211– 216. IEEE, 2006.
[203] X. Yin and X. Liu. Multi-task convolutional neural network for poseinvariant face recognition. TIP, 2017.
[204] X. Yin, X. Yu, K. Sohn, X. Liu, and M. Chandraker. Towards largepose face frontalization in the wild. arXiv preprint arXiv:1704.06244, 2017.
[205] X. Yin, X. Yu, K. Sohn, X. Liu, and M. Chandraker. Feature transfer learning for deep face recognition with long-tail data. arXiv preprint arXiv:1803.09014, 2018.
[206] J. Y. X. W. X. T. Yujun Shen, Ping Luo. Faceid-gan: Learning a symmetry three-player gan for identity-preserving face synthesis. In CVPR, pages 416–422. IEEE, 2018.
[207] E. Zangeneh, M. Rahmati, and Y. Mohsenzadeh. Low resolution face recognition using a two-branch deep convolutional neural network architecture. arXiv preprint arXiv:1706.06247, 2017.
[208] T. Y. J. H. Zhanfu An, Weihong Deng. Deep transfer network with 3d morphable models for face recognition. In FG, pages 416–422. IEEE, 2018.
[209] D. Zhang, L. Lin, T. Chen, X. Wu, W. Tan, and E. Izquierdo. Contentadaptive sketch portrait generation by decompositional representation learning. IEEE Transactions on Image Processing, 26(1):328–339, 2017.
[210] J. Zhang, Z. Hou, Z. Wu, Y. Chen, and W. Li. Research of 3d face recognition algorithm based on deep learning stacked denoising autoencoder theory. In ICCSN, pages 663–667. IEEE, 2016.
[211] L. Zhang, L. Lin, X. Wu, S. Ding, and L. Zhang. End-to-end photosketch generation via fully convolutional representation learning. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, pages 627–634. ACM, 2015.
[212] L. Zhang, M. Yang, and X. Feng. Sparse representation or collaborative representation: Which helps face recognition? In ICCV, 2011.
[213] W. Zhang, S. Shan,W. Gao, X. Chen, and H. Zhang. Local gabor binary pattern histogram sequence (lgbphs): A novel non-statistical model for face representation and recognition. In ICCV, volume 1, pages 786– 791. IEEE, 2005.
[214] W. Zhang, X. Wang, and X. Tang. Coupled information-theoretic encoding for face photo-sketch recognition. In CVPR, pages 513–520. IEEE, 2011.
[215] X. Zhang, Z. Fang, Y. Wen, Z. Li, and Y. Qiao. Range loss for deep face recognition with long-tail. arXiv preprint arXiv:1611.08976, 2016.
[216] X. Zhang and Y. Gao. Face recognition across pose: A review. Pattern Recognition, 42(11):2876–2896, 2009.
[217] X. Zhang, X. Zhou, M. Lin, and J. Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. arXiv preprint arXiv:1707.01083, 2017.
[218] Y. Zhang, M. Shao, E. K. Wong, and Y. Fu. Random faces guided sparse many-to-one encoder for pose-invariant face recognition. In ICCV, pages 2416–2423. IEEE, 2013.
[219] Z. Zhang, J. Yan, S. Liu, Z. Lei, D. Yi, and S. Z. Li. A face antispoofing database with diverse attacks. In ICB, pages 26–31, 2012.
[220] J. Zhao, J. Han, and L. Shao. Unconstrained face recognition using a set-to-set distance measure on deep learned features. IEEE Transactions on Circuits and Systems for Video Technology, 2017.
[221] J. Zhao, L. Xiong, P. K. Jayashree, J. Li, F. Zhao, Z. Wang, P. S. Pranata, P. S. Shen, S. Yan, and J. Feng. Dual-agent gans for photorealistic and identity preserving profile face synthesis. In NIPS, pages 65–75, 2017.
[222] W. Zhao, R. Chellappa, P. J. Phillips, and A. Rosenfeld. Face recognition: A literature survey. ACM computing surveys (CSUR), 35(4):399–458, 2003.
[223] T. Zheng and W. Deng. Cross-pose lfw: A database for studying crosspose face recognition in unconstrained environments. Technical Report 18-01, Beijing University of Posts and Telecommunications, February 2018.
[224] T. Zheng, W. Deng, and J. Hu. Age estimation guided convolutional neural network for age-invariant face recognition. In CVPR Workshops, pages 1–9, 2017.
[225] T. Zheng, W. Deng, and J. Hu. Cross-age lfw: A database for studying cross-age face recognition in unconstrained environments. arXiv preprint arXiv:1708.08197, 2017.
[226] L. Z. Zhengming Ding, Yandong Guo and Y. Fu. One-shot face recognition via generative learning. In FG, pages 1–7. IEEE, 2018.
[227] Y. Zhong, J. Chen, and B. Huang. Toward end-to-end face recognition through alignment learning. IEEE signal processing letters, 24(8):1213–1217, 2017.
[228] E. Zhou, Z. Cao, and Q. Yin. Naive-deep face recognition: Touching the limit of lfw benchmark or not? arXiv preprint arXiv:1501.04690, 2015.
[229] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv preprint arXiv:1703.10593, 2017.
[230] Z. Zhu, P. Luo, X. Wang, and X. Tang. Deep learning identitypreserving face space. In ICCV, pages 113–120. IEEE, 2013.
[231] Z. Zhu, P. Luo, X. Wang, and X. Tang. Multi-view perceptron: a deep model for learning face identity and view representations. In NIPS, pages 217–225, 2014.
[232] Z. Zhu, P. Luo, X. Wang, and X. Tang. Recover canonical-view faces in the wild with deep neural networks. arXiv preprint arXiv:1404.3543, 2014.
[233] W. D. H. S. Zimeng Luo, Jiani Hu. Deep unsupervised domain adaptation for face recognition. In FG, pages 453–457. IEEE, 2018.
[234] X. Zou, J. Kittler, and K. Messer. Illumination invariant face recognition: A survey. In BTAS, pages 1–8. IEEE, 2007.
[235] S. Zulqarnain Gilani and A. Mian. Learning from millions of 3d scans for large-scale 3d face recognition. arXiv preprint arXiv:1711.05942, 2017.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号