

Generative Adversarial Nets[EBGAN]
0. 背景
Junbo Zhao等人提出的“基于能量的GAN”网络,其将判别器视为一个能量函数而不需要明显的概率解释,该函数可以是一个可训练的损失函数。能量函数是将靠近真实数据流形的区域视为低能量区域,而远离的视为高能量区域。和“概率GAN”相似,训练中,生成器会尽可能生成最小能量时候的伪造样本,而此时判别器会被赋值为高能量(因为是伪造的)。通过将判别器看成一个能量函数,就可以使用更多更广泛的网络结构和损失函数,而不只是logistic输出的二值分类器。其中Junbo Zhao等人基于此原理,提出了其中一个实现案例,即自动编码器结构,能量就是重构时候的误差,以此来代替分类器。而且此时训练相对常规的GAN也更稳定。并提出了一个单尺度结构,其可以被训练用来生成高分辨率图片。
早在2006年LeCun就认为基于能量模型的本质就是建立一个函数,用来将多维输入空间中的每个点映射成一个标量,而该标量就被称之为“能量”(参考高尔夫球场)。学习的过程就是一个数据驱动的过程,用来修改能量的表面,使得合适的参数集合下,所需要的区域为低能量,而不需要的区域呈现高能量。有监督学习就是这么个例子:对于训练集中每个样本X,(X,Y)的能量会在Y是正确标签的时候呈现低值,而Y是错误的时候呈现高值。同样的,当对X进行无监督建模的时候,低能量也就是当其在数据流形的时候。这里的对比样本(contrastive sample)表示那些通常会引起能量升高的那些数据点,也就是如有监督中的错误标签和无监督中低密度数据区域中的点。
GAN可以以两种方式去解释:
- 主要的部分是生成器:判别器扮演着可训练的目标函数的角色。我们假设数据位于一个流形上,当生成器生成的样本被识别为处在这个流形上,它就会得到一个梯度用来指示它如何修改它的输出从而更接近这个流形。在这样的场景下,判别器会当生成的样本处在流形之外的时候对生成器进行惩罚。这可以理解成一种用于训练生成器的方法,就为了让其生成合理的输出;
- 主要的部分是判别器:生成器被训练用来生成对比样本。通过迭代和逐步的输入对比样本,生成器增强了判别器的半监督学习性能。
1. EBGAN
1.1 一个基于能量的GAN网络结构
判别器通过一个目标函数用来表示输出,其意在建立对应的能量函数,即对真实数据样本赋予低能量,而伪造的样本赋予高能量。这里使用了一个边际损失来做能量函数的选择。且对于生成器和判别器的目标函数各有不同,如概率GAN一样。给定一个正的边际值\(m\),一个数据样本\(x\),一个生成的样本\(G(z)\),判别器的损失和生成器的损失分别为\(L_D,L_G\):
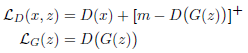
其中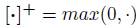
关于G的参数去最小化\(L_G\)等效于最大化\(L_D\)的第二项,当\(D(G(z))\geq m\)时它有相同的最小值(因为此时第二项值为0),且非0的梯度
假定生成器以G标识,\(p_G\)为\(G(z)\)的密度分布,其中\(z\sim p_z\)。换句话说,\(p_G\)是由G生成的样本的密度分布。定义\(V(G,D)=\int_{x,z}L_D(x,z)p_{data}(x)p_z(z)dxdz\)和\(U(G,D)=\int_zL_G(z)p_z(z)dz\)。我们训练判别器D用于最小化值\(V\),训练G用于最小化值\(U\)。此时的纳什平衡就是有一对最优解\((G^*,D^*)\),他们满足:
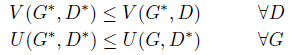
从上述论述中,可以得到两个结论:
- 如果\((G^*,D^*)\)是系统的纳什平衡,那么在几乎任何地方都有\(p_G=p_{data}\),并且此时\(V(D^*,G^*)=m\)(简单来说就是\(D(x)=D(G(z))=0.5\))
- 该系统存在一个纳什平衡,且有:
- 几乎任何地方有\(p_{G^*}=p_{data}\)
- 存在一个常量\(\gamma\in[0,m]\),例如\(D_*(x)=\gamma\)(这是假设不存在\(p_{data}(x)=0\)的区域,如果真的存在这种区域,那么\(D^*(x)会有介于[0,m]的其他值赋予该区域\))
证明在论文的2.2部分和附录A,E
1.2 基于1.1的一个实现(添加正则的AE作为判别器)
在文中,作者提出了一个基于能量GAN结构的实现,其中判别器是一个自动编码器:
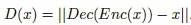
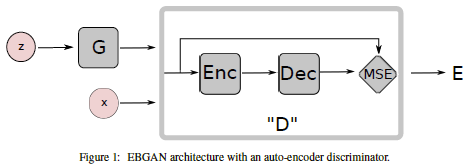
图1.2.1 以AE作为判别器的EBGAN实现
采用AE而不是传统的二分类函数的意义有:
- 不同于一个bit的二分类结果,基于重构的输出可以为判别器提供不同的目标。因为在二分类的logistic loss中,只有2个目标的选项,所以在一个minibatch中,对应不同样本的梯度基本上都不可能互相正交。这使得训练十分低效。另一方面,重构loss可以在一个minibatch中产生许多不同方向的梯度,从而允许更大的minibatch size基础上,基本没有loss效率的损失。
- 对于传统角度上看,ae也是用来作为基于能量的模型,所以用它也是自然选择,而且当加上正则项时,ae可以在没有监督或者负类样本的基础上学习一个能量流形。这意味着即使当一个EBGAN是基于AE实现时,可以只用真实样本来进行训练,判别器可以自己去找到数据流形。而这对于二分类的logistic loss时不可能的。
训练AE的一个通常问题是模型只是学到了恒等函数的结果,这意味着对于整个空间来说,都是0能量。所以为了避免这种问题,模型需要对数据流形之外的点赋予更高的能量值。这可以通过对中间的隐藏层加正则来做到。这样的正则需要能够限制AE的表达能力,从而它只赋予输入点中更小的区域上才有低能量。
在EBGAN结构中能量函数(判别器)通常被认为是由生成器生成的对比样本给正则了,为了让判别器有着更高的重构能量。而EBGAN结构从这个角度上看,相对更灵活,因为:
- 正则化器(生成器)可以完全训练所得,而不需要手工设计;
- 对抗训练的策略可以让生成对比样本的过程和学习能量函数的过程直接相互接触。
基于上面所述,提出了repelling regularizer,意在让模型不要生成那些聚类在一点的样本或者基本没拟合到\(p_{data}\)的分布。另一个技术叫"minibatch discrimination"(Improved techniques for training gans) 也是遵循相同的原则。
这里提出的正则项叫做Pulling-away项,假设\(S\in R^{s\times N}\)表示AE的编码层输出的项。其中\(N\)表示batch中样本个数;\(s\)为AE的隐藏层输出向量。
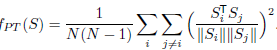
PT是在一个minibatch上操作的,意在正交逐对样本表征。采用cos相似度而不是欧式距离是为了保证此项的下限值和尺度不变性。
2. 实验分析
2.1 基于mnist的参数配置搜索
作者对比了下EBGAN和GAN的不同参数下的结果。

上表中只包含了一部分参数配置,如EBGAN只展现了编码器的层结构,其中还有
- m值设定为10,且训练中无变化:
- 在每一层权重层后都有BN层,除了生曾去的输出层和判别器的输入层;
- 训练图像都缩放到[-1,1],用来适应生成器输出层使用的tanh激活函数;
- 使用ReLU作为非线性激活函数;
- 初始化:判别器中初始化是N(0,0.002);而生成器的是N(0,0.02)。偏置都初始化为0
模型的好坏采用“inception score”(Improved techniques for training gans)进行判别

可以看出加了PT正则项的结果最好,其中参数为:
- (a): \(nLayerG=5, nLayerD=2, sizeG=1600, sizeD=1024, dropoutD=0,optimD=SGD, optimG=SGD, lr=0.01.\)
- (b): \(nLayerG=5, nLayerD=2, sizeG=800, sizeD=1024, dropoutD=0,optimD=ADAM, optimG=ADAM, lr=0.001, margin=10.\)
- (c): 和(b)一样,且\(\lambda_{PT} = 0.1\)
2.2 基于mnist的半监督学习
附录d

 浙公网安备 33010602011771号
浙公网安备 33010602011771号