

Feature Extractor[DenseNet]
0.背景
随着CNN变得越来越深,人们发现会有梯度消失的现象。这个问题主要是单路径的信息和梯度的传播,其中的激活函数都是非线性的,从而特别是乘法就可以使得随着层数越深,假设将传统的神经网络的每一层看成是自动机中的一个状态。那么对于整个神经网络来说,输入到输出就是一个输入态不断的转移到输出态的一个过程。假设其中每一层都是有个变率,即缩放因子。那么:
- 变率大于1,层数越多,越呈现倍数放大趋势,比如爆炸;
- 变率小于1,层数越多,越呈现倍数缩小趋势,比如消失;
而传统以往的卷积神经网络都是单路径的,即从输入到输出只能走一条路,所以人们发现了可以通过扩展信息的传输路径和形式,如:
- inception系列从模块入手,基于每个模块建立多个不同的通道,然后将模块进行连接,不过从模型整体角度上看也是一本道;
- ResNet系列通过快捷连接的方式将不同层的输出直接连接到后面层的输入,算是让信息的传播通道有了分支,不完全直接走非线性的卷积和池化等权重层,让信息的传播路径有了选择。
正是发现可以从网络结构入手,让信息的传输路径不再单一。假如我们认为传统的神经网络的输入到输出是单路径形式,那么通过添加分支路径使得某些层能够比传统模型有更多更短的路径可以选择,这样较好的解决了唯一路径的"瓶颈问题"(信息只有一条路可走),从而通过网络训练,信息能够自适应的走网络的多个路径。不过近期很多的论文,如ResNet和Highway Network等都是通过恒等连接将某层的输出信息传递到后面其他层,且而《Deep networks with stochastic depth》在Resnet网络结构上发现其实很多层的信息是冗余的,通过在训练过程中随机丢弃某些层可以得到更好的信息和梯度流。
DenseNet由此出发,建立了更复杂的多通道模型,如图0.1所示,输入层可以快捷连接到输出层:
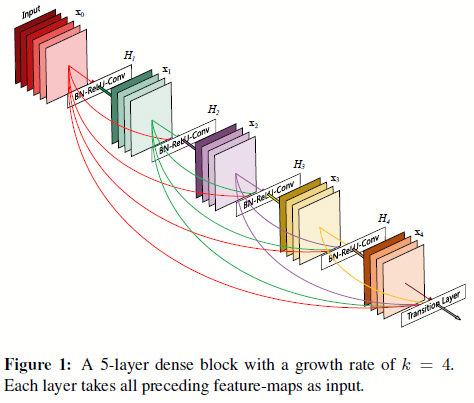
图0.1 Densenet的模块结构
如图0.1,这就是Densenet的模块结构。作者认为好处有:
- 缓和了梯度消失的问题(多路径带来的好处);
- 增强了特征传播(多路径带来的好处);
- 特征能够多次重用,从而减少冗余特征的学习;
- 模型参数量能够很大程度上的减少;
- 模型具有正则效果(在很小的数据集上减少过拟合)
如图0.1所示,Densenet在将特征连入后面的层之前,不对其做任何操作,只是将其以通道的维度进行合并(如第\(l\)层有\(l\)个通道输入,那么结合之前所有的卷积层,这时候的通道数变成了\(l(l+1)/2\)).
值得注意的是,通过实验发现,这样一个相对更密集的网络结构,所需要的参数量反而更少,这归功于densenet不需要去保留那些冗余的feature map。
1. DenseNet
基于上述自动机的角度,传统的前向网络结构可以认为是:当前层从前一层获取状态,然后加以处理,并将新的状态输出到下一层。这其中就会发现有些信息其实是需要保留到当前层的,结果也传递到后面去了,造成了冗余。接着从自动机角度出发,Resnet也可以看成是一个“相似的铺展开的RNN网络结构”(通过恒等连接实现循环),不过不同于RNN的就是resnet的参数量因为每一层都是有各自的参数,所以相比RNN的参数量要大很多。
为了防止参数量过大,且主要是基于特征重用。densenet设计的时候是让每一层的通道数量很小(一层12个通道),且如0.1图所示,后续每一层都能直接获取前面所有层的特征,最后的分类器可以基于所有的feature map进行做决策,这样让特定层的特征能够一直重用,从而减少网络的冗余特征学习。
用数学形式来说明ResNet与Densenet的差别如下:
- ResNet: \(x_l = H_l(x_{l-1})+x_{l-1}\)
- DenseNet: \(x_l = H_l([x_0,x_1,...,x_{l-1}])\)
其中\([x_0,x_1,...,x_{l-1}]\)就是将之前的feature map以通道的维度进行合并,且受到ResNet v2的影响,其中的\(H_l(\dot)\)也是三层网络:BN、ReLU、卷积。
如上面所述,在进行feature map合并的时候,是没法处理feature map的size不同的情况的,可是CNN是必须要有map的size的减小的,也就是池化还是需要的,不然输出层会参数量过多了。所以作者通过图1.1形式来解决这个问题。
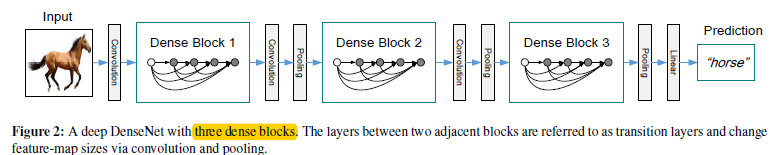
图1.1 将图0.1结构作为densenet的块来构建整个网络
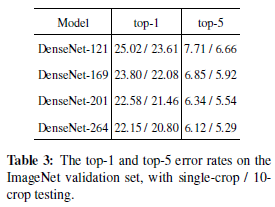
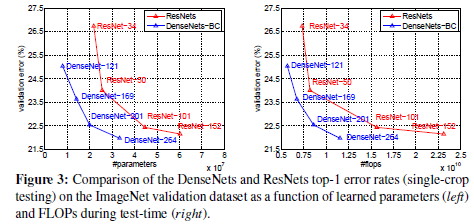
图1.2 基于imagenet上的实验结果
如图1.1。通过将图0.1的结构作为一个构建块,从而在不同的构建块之间建立转换层,从而解决feature map需要变化的问题(其中连接层由:BN层,\(1*1\)卷积层,\(2*2\)池化层构成,其中BN未画出来)(那么,这样是不是说在池化部分,就有瓶颈存在了呢?)
1.1 增长参数k
对于图0.1来说,假定每一层的feature maps的个数为k,则第\(l\)层的输入map个数为\(k_0+k*(l-1)\),即收集之前每层输出的feature maps,然后基于通道维度进行合并,以此作为当前层的输入feature maps。那么k值的大小就能控制网络的复杂度了,作者将该变量称为网络的"growth rate"
1.2 DenseNet-B
对于DenseNet-B来说,就是将之前densenet的构建块中的BN-ReLU-(\(3*3\)卷积)变成BN-ReLU-(\(1*1\)卷积),并且对于其中的(\(1*1\)卷积),输出的feature maps的通道数为4k个
1.3 DenseNet-C
对于Densenet-C来说,就是在转换层下功夫了,如图1.1中的两个Dense block中间的部分,如果上一个Dense block输出了m个feature maps(即将之前所有的feature map都连接到这个转换层),那么设定一个缩放因子\(\theta\),如果\(0<\theta<1\),那么就达到了网络通道上的降维,使得模型更紧凑,实验中该值设为0.5。
2 实现过程
- 1 - 作者在imagenet数据集上用个4个dense block,结构如下图
图2.1 k等于32基础上,不同层数densenet网络的结构

- 2 - 在其他数据集上是用了三个dense block(每个block中层数相同),转换层是\(1*1\)的卷积加上\(2*2\)的平均池化,在最后一个dense block后面跟上一个全局平均池化,然后是一个softmax。
其中三个dense block中feature map的大小分别是\(32*32\),\(16*16\),\(8*8\),且有三个不同的参数组合:
- 对于简单的densenet来说有(L=40,k=12)、(L=100,k=12)、(L=100,k=24);
- 对于densenet-BC来说有(L=100,k=12)、(L=250,k=24)、(L=190,k=40)

图2.2 其他数据集下的实验对比

 浙公网安备 33010602011771号
浙公网安备 33010602011771号