

python复现jedis中客户端分片访问
1 引言
在很多公司中是spark处理大量数据,然后塞入redis(如一堆特征数据),但是下游可能存在需要python读取该redis然后获取其中的数据(利用tf进行建模),但是jedis中的客户端分片机制在其他python的客户端sdk中都好像未复现,
2 python客户端调研
如python连接redis sentinel集群中体现的,python在通过master_for等api访问时,第一个参数需要提供分片名称,这本无可厚非,可是如引言所述,我们有一堆分片,没法挨个塞进去,当然有人说,我可以写个python简单封装,假定有200个分片:
- 先写个for循环获取这200个分片对应的master
- 再写个多线程子代码,来一个key就同时分发,通过master.exists来判断,找到那个对应的redis实例
- 再对该redis实例发起get和set
上述方法我试过,在第二步耗时30ms,第三步耗时0.3ms。所以如果一旦特征过多,该方法还是禁不起考验
3 jedis调研
如 Jedis - SharedJedisPool 初始化与应用 & hash 算法详解 中的流程可以简单知道jedis的流程,
我们通过下述代码截图来进一步知道其过程
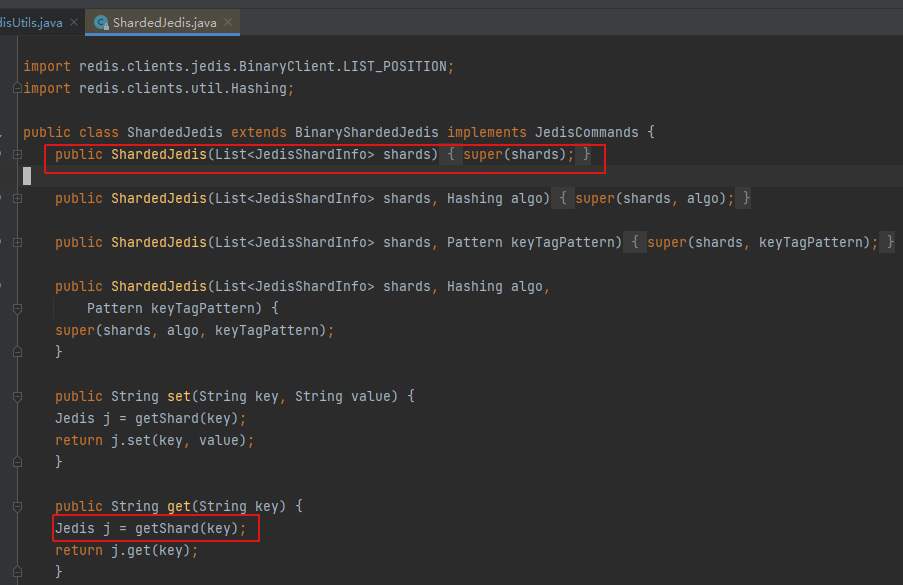
通过定位,首先就是该类,可以通过初始化部分知道,传递的就是一个分片列表,而在后续的get中,是先获取对应的分片,然后基于该分片再去get。
继续定位:
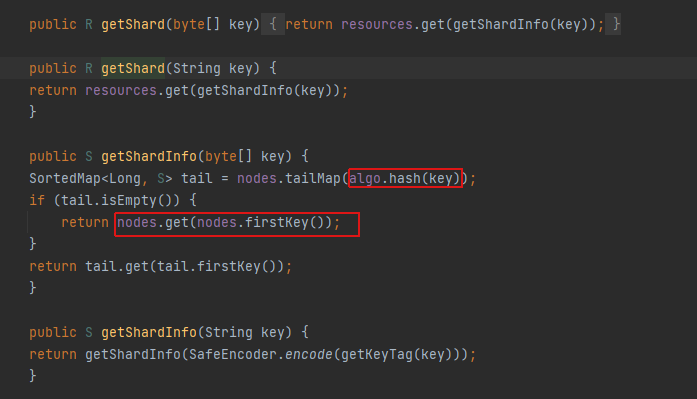
key传进来后,先getShardInfo(key),通过代码执行
getKeyTag(key:String) // 结果还是key(意思是进去这个字符串,出来还是这个)
SafeEncoder.encode(getKeyTag(key:String)) // 结果还是key(意思是进去这个字符串,出来还是这个)
algo.hash(key)//的结果是 一个好大的整数,可能是"-3348278837805118665"这种
SortedMap<Long, S> tail = nodes.tailMap(algo.hash(key)) //是基于用户的key的hash值,将nodes表示的treemap中大于等于该值的取出来
tail.get(tail.firstKey()) // 是将tail中第一个取出来然后获取其对应的value
那么nodes是什么呢
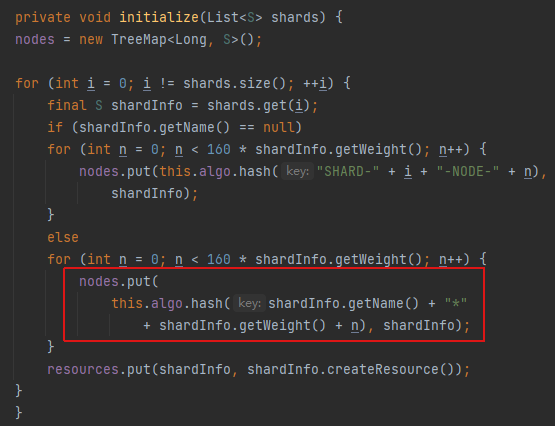
如上图,nodes是一个treemap,其中shardInfo.getWeight()如果用户不特定初始化,其就是1,可以直接带入;
nodes的key就是分片名称(用户传的)+"*"+"1"+{n};其中n就是0到160;假定用户有200个分片,如"shard-{1-200}",那么这里就一共200*160个key;
其中的value就是shardinfo实例,通过shardinfo.getName()就能获取到实际的分片名称了。
4 代码实现
我们通过上述分析以及实际的值打印,进行了如下的复现,其中最重要的hash部分是参考了基于Python3.6实现Java版murmurhash算法,拿来即用。
这样我们
- 先模仿jedis基于分片构建完整的nodes
- 等用户输入key,再找到对应的那个分片的redis实例,
- 再针对该实例发起get
下面代码的最下面有使用例子
#-*- coding: utf-8 -*-
import ctypes
import time
from pytreemap import TreeMap
import redis
from redis.sentinel import Sentinel
class RedisShared(object):
def __init__(self,SentineAddress,shards,socket_timeout = 2000):
self.socket_timeout = socket_timeout
self.SentineAddress = SentineAddress
self.SharedNames = shards
self.MySentinel = Sentinel(self.SentineAddress,socket_timeout = self.socket_timeout)
self._filter()
self.resources = self._slaves()
self.nodes = self._initialize()
def _slaves(self):
'''构建一个分片-》redis实例的映射 '''
resources={}
for i in self.shards:
try:
ans = self.MySentinel.slave_for(i,socket_timeout = self.socket_timeout)
resources[i] = ans
except Exception as e:
print("=========",i,str(e))
continue
return resources
def _filter(self):
'''用来过滤不能访问的分片 '''
self.shards = []
for i in self.SharedNames:
try:
ans = self.MySentinel.discover_master(i)
self.shards.append(i)
except Exception as e:
continue
def _initialize(self):
'''仿造jedis中进行nodes的初始化 '''
nodes = TreeMap()
for i,shard in enumerate(self.shards):
for n in range(160):
key = '{}*{}{}'.format(shard,1,n)
nodes.put(ByteBuffer.mmh(key), shard)
return nodes
def get(self,key):
'''具体的复现过程 '''
hashkey = ByteBuffer.mmh(key)
total = self.nodes.tail_map(hashkey)
shard = self.nodes.get( total.first_key())
redisobj = self.resources[shard]
res = redisobj.get(key)
return res
'''
# @File : ByteBuffer.py
# @Author: Vam
# @Date : 2020-09-08
# @Desc : 实现java'的ByteBuffer对象有关mmh相关的算法
'''
class ByteBuffer(object):
def __init__(self, buff:bytearray = None, position:int = 0, mark:int = -1, capacity:int = 0, limit:int = 0, order = "BIG_ENDIAN"):
"""
:param buff: buff即内部用于缓存的数组
:param position: 当前读取的位置。
:param mark: 为某一读过的位置做标记,便于某些时候回退到该位置。
:param capacity: 初始化时候的容量。
:param limit: 当写数据到buffer中时,limit一般和capacity相等,当读数据时,limit代表buffer中有效数据的长度。
"""
self.buff = buff or bytearray()
self.position = position
self.capacity = capacity or len(buff)
self.mark = 0
self._limit(limit)
self._position(position)
self._order = order
if mark >= 0:
if mark > position:
raise Exception("IllegalArgumentException:mark:%s, pos:%s" % (mark, position))
self.mark = mark
@classmethod
def long_overflow(cls, val):
maxint = 0x7fffffffffffffff
if not -maxint - 1 <= val <= maxint:
val = (val + (maxint + 1)) % (2 * (maxint + 1)) - maxint - 1
return val
@classmethod
def unsigned_right_shitf(cls, n, i):
# 对应Java >>>
# 数字小于0,则转为64位无符号uint
if n < 0:
n = ctypes.c_uint64(n).value
# 正常位移位数是为正数,但是为了兼容js之类的,负数就右移变成左移好了
if i < 0:
return -cls.long_overflow(n << abs(i))
# print(n)
return cls.long_overflow(n >> i)
def _position(self, newPosition):
if newPosition > self.limit or newPosition < 0:
raise Exception("IllegalArgumentException")
self.position = newPosition
if self.mark > self.position:
self.mark = -1
return self
def _limit(self, newLimit):
if newLimit > self.capacity or newLimit < 0:
raise Exception("IllegalArgumentException")
self.limit = newLimit or self.capacity
if self.position > self.limit:
self.position = self.limit
if self.mark > self.limit:
self.mark = -1
return self
@classmethod
def get_java_long(cls, num, unsignal=False):
return cls.get_java_int(num, base=64, unsignal=unsignal)
@classmethod
def get_java_int(cls, num, base=32, unsignal=False):
def trans(num_array):
ret = ''
for i in num_array:
if i == '0':
ret += '1'
else:
ret += '0'
return ret
if isinstance(num, bytes):
num = ord(num)
if unsignal:
if num >= 2 ** base -1:
transe_array = bin(num)[-base:]
return int(transe_array, base=2)
else:
if abs(num) >= 2 ** (base - 1) - 1:
bin_num = bin(num)
transe_array = bin_num[-base:]
signal = int(num / abs(num)) * ((-1) ** int(transe_array[0]))
if int(transe_array[0]) == 1: # 符号位为1时取反码+1
transe_array = trans(transe_array)
return signal * (int(transe_array, base=2) + 1 )
return signal * (int(transe_array, base=2))
return num
@classmethod
def allocate(cls, capacity=8):
return ByteBuffer(capacity=capacity)
@classmethod
def wrap(cls, buff:bytearray, offset=0, length=None):
if not offset and not length:
return cls(buff=buff)
else:
return cls(buff=buff[offset:length])
def remaining(self):
return self.limit - self.position
def get(self, index:int):
return self.buff[index]
def put(self, b):
n = b.remaining()
if n > self.remaining():
raise Exception("BufferOverflowException")
for i in range(b.position, b.position + n):
self.buff.append(b.buff[i])
return self
def order(self, ByteOrder:str):
self._order = ByteOrder
return self
def rewind(self):
self._limit(self.capacity or len(self.buff))
self._position(0)
def nextGetIndex(self, nb):
if self.limit - self.position < nb:
raise Exception("BufferUnderflowException")
p = self.position
self.position += nb
return p
def getLong(self):
if self._order == "BIG_ENDIAN":
return self.getLongB(self.nextGetIndex(8))
else:
return self.getLongL(self.nextGetIndex(8))
def _get(self, index):
if index >= len(self.buff):
return 0
else:
return self.buff[index]
def getLongB(self, a):
return self.makeLong(self._get(a),
self._get(a + 1),
self._get(a + 2),
self._get(a + 3),
self._get(a + 4),
self._get(a + 5),
self._get(a + 6),
self._get(a + 7))
def getLongL(self, a):
return self.makeLong(self._get(a + 7),
self._get(a + 6),
self._get(a + 5),
self._get(a + 4),
self._get(a + 3),
self._get(a + 2),
self._get(a + 1),
self._get(a))
def makeLong(self, b7=0, b6=0, b5=0, b4=0, b3=0, b2=0, b1=0, b0=0):
return ((ByteBuffer.get_java_long(b7) << 56) |
((ByteBuffer.get_java_long(b6) & 0xff) << 48) |
((ByteBuffer.get_java_long(b5) & 0xff) << 40) |
((ByteBuffer.get_java_long(b4) & 0xff) << 32) |
((ByteBuffer.get_java_long(b3) & 0xff) << 24) |
((ByteBuffer.get_java_long(b2) & 0xff) << 16) |
((ByteBuffer.get_java_long(b1) & 0xff) << 8) |
((ByteBuffer.get_java_long(b0) & 0xff)))
@classmethod
def mmh(cls, key):
buf = cls.wrap(bytearray(key, encoding="utf-8"))
seed = cls.get_java_int(0x1234ABCD)
# print("seed:", seed)
buf.rewind()
order = buf._order
buf.order("LITTLE_ENDIAN")
m = cls.get_java_long(0xc6a4a7935bd1e995)
# print("m:",m)
r = 47
# print(buf.__dict__)
# print("remaining * m:", cls.get_java_long(buf.remaining() * m))
h = cls.get_java_long(seed ^ (buf.remaining() * m))
# print("h:", h)
while buf.remaining() >= 8:
k = cls.get_java_long(buf.getLong())
k = cls.get_java_long(k * m)
# print("k:", k)
# print("k >>> r:", cls.unsigned_right_shitf(k, r))
k = cls.get_java_long(k ^ (cls.unsigned_right_shitf(k, r)))
k = cls.get_java_long( k * m)
# print("k2:", k)
h = cls.get_java_long(h ^ k)
# print("h1:", h)
# print("h * m", h * m)
h = cls.get_java_long(h * m)
# print("h", h)
# print(buf.__dict__)
# print(buf.remaining())
if buf.remaining() > 0:
finish = cls.allocate(8).order("LITTLE_ENDIAN")
finish.put(buf).rewind()
# print("finish:", finish.__dict__)
finish.rewind()
h = cls.get_java_long(h ^ finish.getLong())
h = cls.get_java_long(h * m)
h = cls.get_java_long(h ^ cls.unsigned_right_shitf(h, r))
h = cls.get_java_long(h * m)
h = cls.get_java_long(h ^ cls.unsigned_right_shitf(h, r))
buf.order(order)
return h
if __name__ == '__main__':
SentineAddress = [('ip1', port1), ('ip2', port2), ('ip3', port3)]
shards = [f'shard_{i}' for i in range(1,200) ]
obj = RedisShared(SentineAddress,shards)
k = "good-file-feature:123455" # 假设该key在分片shard_100上
for i in range(10):
st = time.time()
ans = obj.get(k)
print(ans,'====ind========',time.time()-st) # 基本稳定在0.4ms

 浙公网安备 33010602011771号
浙公网安备 33010602011771号