


4-8(十四) jmeter 性能分析从哪几个方面
一、设计场景,添加监听器
1、设计场景
阶梯型、波浪形
2、监视器
- 用于收集用于性能分析的数据
- TPS图表、聚合报告\汇总报告、查看结果树、响应时间、吞吐量
- 服务器资源监控: cpu,内存、磁盘io
二、第一步先分析是否存在影响结果的事物
分析前的我们查看几种情况是否会影响性能测试的结果,如果以下的方面有不同,那么最后的性能分析只能作参考
1、前提条件:
- 1、独立的服务器
- 如果与其他人环境公用呢?其他人也会占用其中的资源
- 2、独立单独的网络
- 网络是直连的,没有VPN 或其他的;
2、服务器操作系统瓶颈判定(参数配置、数据库、web服务器)
我们在做性能的时候需要考虑参数配置,数据库,服务器,尽可能与生产相同;如果不同只能作参考,没有任何意义
- 比如说生产用的16核的CPU的服务器,测试性能的时候只有8核的CPU
- 性能测试的时候内存有8G,生产有32G内存
3、应用瓶颈判定方向(sql语句、数据库设计、业务逻辑、算法)
- sql 写的不行,查看sql慢查询的脚本来分析,
- 如果是数据库表结构设计的不合理,表没有键索引,,,,,,那就键索引
- 如果是表的字段太多,存储的数据量太大
- 解决:要么读写分离,要么分表分库
- 如果是业务逻辑,本来一个简单的业务逻辑,给做成非常复杂的判断,写法算法不合理,非得计算太多的没必要的计算
- 考虑:那就需要调整设计
- 我不需要实时返回的数据,我本来可以异步获取数据,导致性能很低下
- 那就需要调整设计
- 自己去数据库跑脚本,可以去查看慢查询的日志去分析
- 自己拿着一个sql的脚本,在客户端工具里面,自己跑脚本,并且同时去跑性能,在跑了几次脚本后发现数据连接时间在秒级,那么脚本就可能是慢查询,数据库也有慢查询的日志,这种结果只能让专业人士去分析或者自己去研究慢查询
总结:分析思路我们可以从四个方面结合:
- 服务器硬件瓶颈 -> 网络瓶颈 -> 服务器操作系统瓶颈(参数配置、数据库、web服务器) -> 应用瓶颈(sql语句、数据库设计、业务逻辑、算法)
- 由外而内、由表及里、层层深入
三、第二步,执行完脚本分析性能测试的结果
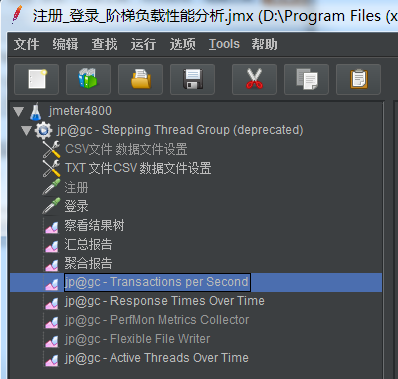
1、查看结果树报告
查看结果树,日志报告数据有没有错误,如下:
第一种
- 错误提示:Error: Failed to connect to server“148.70.10.80:8080******
>>> 可能是:1.应用奔溃; 2.应用连接数过高: 3.数据库连接数过高
1.链接不上服务器,服务器奔溃;
- 查看服务器资源消耗的情况
- 查看服务是否停了
2.服务器连接数过高:
- 每个服务都有最大的链接数限定
- 使用Linux查看 8080端口,当前的链接的数量,是否超过了 Tomcat配置的最大链接数量
3.数据库连接数过高
- 调应用程序只调一次请求,但是数据库调用了三次
- 应用链接数假设为200,那么数据库连接数就要达到600,这样情况下会出现数据库连接数不够用的情况
第二种
- 错误提示:Error: Page download timeout (120 seconds) has expire**** ====下载某一个页面超时
>>> 可能是:1.应用参数设置太大; 2下载图片太多: 3返回数据太多
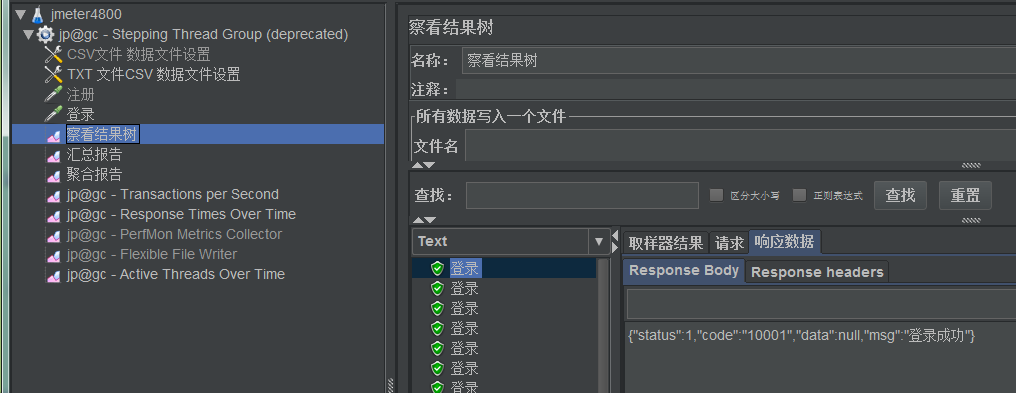
2、查看聚合报告、汇总报告
两个报告中查看:
- 最大值、最小值、平均值:如果页面反应时间是3秒,那么页面肯定超过了3秒了
- 标准方差
- 标准方差差异很大:说明有问题,不能达到预期指标
- 标准方差差异很小,均衡:说明正常

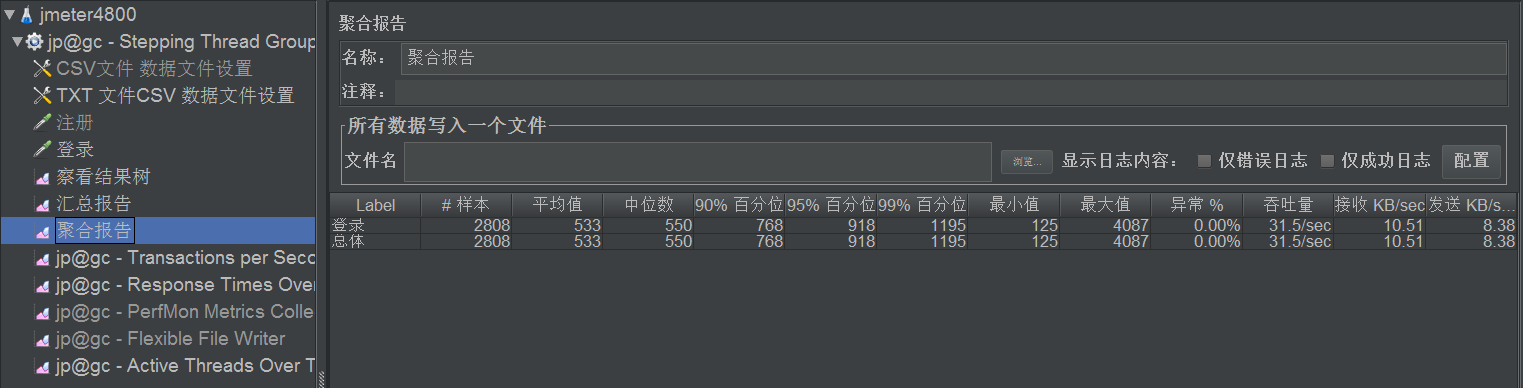
聚合报告参数详解
1. Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
2. #Samples:请求数——表示这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
3. Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,以Transaction 为单位显示平均响应时间
4. Median:中位数,也就是 50% 用户的响应时间
5. 90% Line:90% 用户的响应时间
6. Min:最小响应时间
7. Max:最大响应时间
8. Error%:错误率——错误请求数/请求总数
9. Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
10. KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
性能测试报告中关注点
- #Samples 请求数
- Average 平均响应时间
- Min 最小响应时间
- Max 最大响应时间
- Error% 错误率
- Throughput 吞吐量
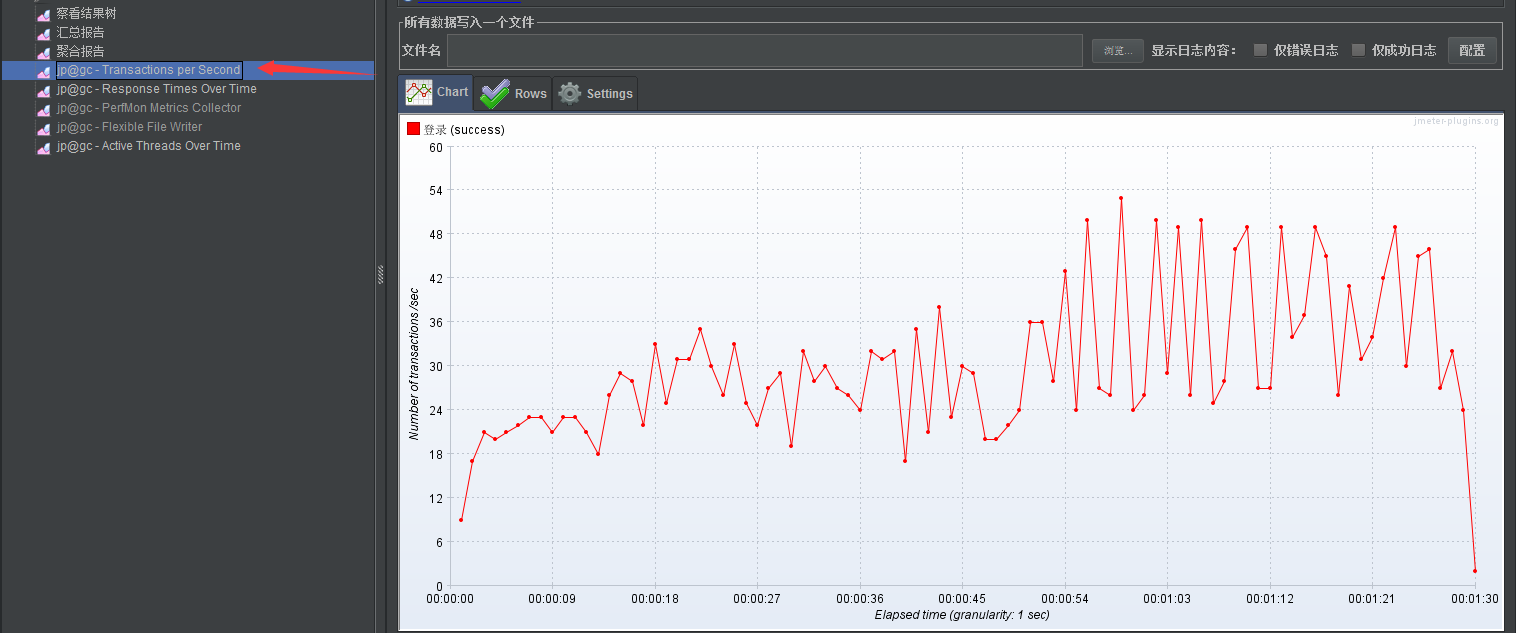
3、查看tps(趋势):衡量服务器指标,服务器每秒处理的事物数
随着数据量的增多,这张图票会非常的密集;在这种情况下我们就需要去看它的中位线趋势图,查看其中的走势,不是去看某一个点的值(一点用没有)
直接下降:
- 不建议使用一秒内登陆100个虚拟用户
先上升后下降:
- 配合其他的图标来看大概的值是多少
- 比如:设置了阶梯型的场景,十个一阶梯(5秒内登录10个虚拟用户,在持续执行1分钟),在跑到80个并发数之前 tps 还是持续增长的情况,说明80并发虚拟用户的情况下服务器还是OK没有问题的,没有出现性能瓶颈当在80之后,接口返回出现报错,tps明显波动开始向下,需要在配合其他图标来查看,那就说明在80以上的某个点,很有可能就出现了系统瓶颈拐点的值
先下降后上升: ? ? ?
- 不会出现这种情况,出现了那就是脚本可能出现问题了
4、查看响应时间趋势
从发送到服务器,服务器处理完,做后收到响应数据的这个时间
直接下降:
先上升后下降 ?? ? ?
- 并发数少的时候,是逐渐上升,并发用户数越多,服务器处理时间应该是时间越来越长,不会下降,所以不会出现这种情况
先下降后上升:只会出现这种
- 并发数越多,处理时间越长,响应时间逐渐向上
- 如果出现陡然上升,那么可能到了瓶颈
- 有可能服务器宕机,连接数出现异常导致无法连接,网络已经堵塞了,那么响应时间会超长
- 瓶颈的值有可能在 陡然点的旁边,通过时间和线程数,就可以大概的知道当时运行的是多少的并发数,瓶颈大概就在这个范围

5.查看吞吐量\吞吐率趋势
网络传输数据的指标,分析网络的瓶颈重要依据;
直接下降:
先上升后下降:
- 随着并发用户数逐步的增加,我们的网络传输速度吞吐量也会逐步的上升,
- 如果我们的服务器出现了瓶颈,那么我们的吞吐量就会逐步开始的下降
- 如果服务器还没有达到瓶颈,但是我们的网络带宽不够(VPN,外网到内网),有可能是网络不稳定,网络传输不过来,也会导致吞吐量的下降
先下降后上升????
- 这种情况只可能在起步刚开始,短时间出现这种情况,系统是不会长时间出现这种趋势的
- 如果出现那就要分析是脚本,网络或者场景设计不对
6.服务器资源监控
直接下降:????
先上升后下降:
- 先上升,如果达到某个点突然下降,那么我们的服务器可能已经停机了,正常情况下应该是慢慢上升下降
先下降后上升:???
指标80%:
- 比如调用登录接口,并发用户数达到 80,服务器资源逐步上升到80%或超过80%的时候,我的响应时间会逐渐的拉长,还在可受的范围内,那么对不起它在 80 并发用户数的时候,就已经达到了最大承受范围为80并发数;在80并发这个时候我们的并发用户数就不能往上在加了,在加我们的服务器资源逐渐的占用,其他的服务就可能宕机,最终会导致服务器处理不过来
- 在某种情况下达到 80% 那么我们就会停下来,已经达到了瓶颈
- CPU、内存、io只要不超过 80 就可以
- 如果超过80 那么服务器的响应时间就会逐步的拉长,那么瓶颈就为当前的并发用户数,
- CPU 和内核有关系,当前一台大概为16核
*******请大家尊重原创,如要转载,请注明出处:转载自:https://www.cnblogs.com/shouhu/,谢谢!!*******

 浙公网安备 33010602011771号
浙公网安备 33010602011771号