

MR 01 - MapReduce 计算框架入门
1 - 什么是 MapReduce
维基百科中,MapReduce 是 Google 提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。
MapReduce 是 Hadoop 框架的一个模块,其核心就是“先分再合,分而治之”,它把整个并行计算过程抽象成2个阶段:
- Map(映射),负责“分”,就是把复杂的任务分解成若干个“简单的任务”来并行处理。可以拆分的前提是,这些小任务可以并行计算,彼此间几乎没有依赖关系。
- Reduce(化简/归纳),负责“合”,就是把 Map 阶段的子结果合并成最终的结果。
一个简单的 MapReduce 程序只需要指定 map()、reduce()、input 和 output,剩下的事由 Hadoop MapReduce 框架帮你完成。
还难以理解?再来一个比喻:
我们要统计图书馆中的1000个书架上的书,一个人统计,耗时会很久;
我们找到1000个同学帮忙,每个人统计1个书架,记录好统计的结果 —— Map 过程;
1000个同学都统计结束后,把所有结果再汇总到一起,就得到了最终的结果 —— Reduce 过程。
2 - MapReduce 的设计思想
MapReduce 是一个分布式计算的编程框架,核心功能是将用户编写的业务代码和自带的默认组件整合成一个完整的分布式程序,并发运行在 Hadoop 集群上。
2.1 如何海量数据:分而治之
MapReduce 对 相互间不具有计算依赖关系的数据,采取分而治之的策略。
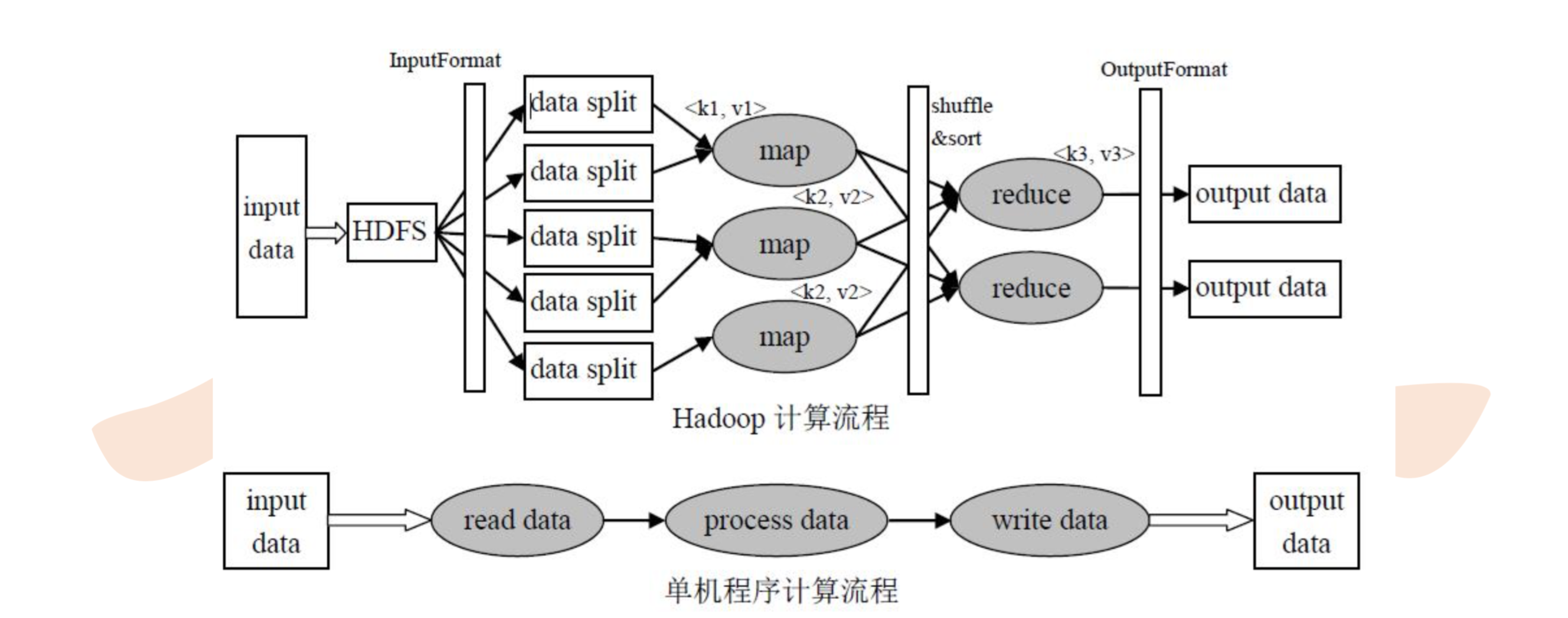
从上图可以看到,MapReduce 的执行过程涉及到:输入(input)、按照定义好的计算模型对 input 进行计算,最终得到输出(output)。
2.2 方便开发使用:隐藏系统层细节
如果要从头开发一套 MapReduce 作业,开发人员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节。
为了减少开发人员的工作,MapReduce 设计并提供了统一的计算框架,隐藏了系统层面的处理细节,开发人员只需要编写少量的处理应用本身计算问题的代码,MapReduce 框架负责完成并行计算任务相关的系统层细节,比如:分布式任务的调度和监控,重新执行已经失败的任务等等。
就是说,开发人员只需知道具体怎么做(how to do),不用关注需要做什么(what need to do)。
2.3 构建抽象模型:Map 和 Reduce
MapReduce 借鉴了函数式编程语言的思想,它提供了 Map 和 Reduce 两个抽象的编程接口。
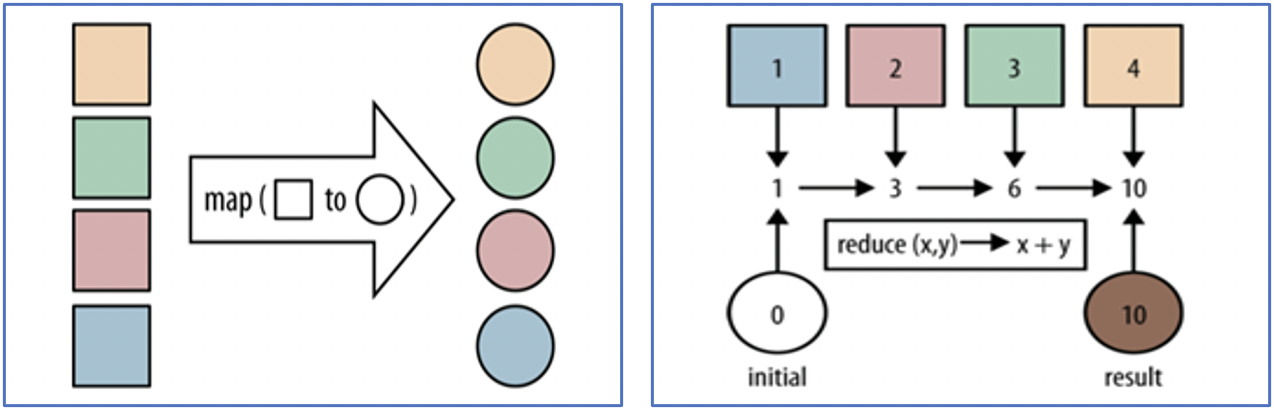
MapReduce 处理的数据类型是 <key, value> 键值对:
Map 阶段是把数据从一种形式转化成另一种形式,如:
(k1; v1) → [(k2; v2)]Reduce 阶段是对 Map 的结果进行进一步的整理,如:
(k2; [v2]) → [(k3; v3)]
| 函数 | 输入 | 输出 | 说明 |
|---|---|---|---|
| map | <k1, v1> 如:<第一行, "abb"> |
List(<k2, v2>) 如:<"a", 1> <"b", 2> |
1、把数据集解析成 <key, value>,输入到 map 中; 2、输入的 <k1, v1> 可能会输出一批中间结果 <k2, v2> |
| reduce | <k2, List(v2)> 如:<"b", <1, 1> |
<k3, v3> 如:<"b", 4> |
<k2, List(v2)> 中的 List(v2) 表示一批 v2 属于同一个 k2 |
3 - MapReduce 的优劣
3.1 MapReduce 的优势
1)易于编程
开发人员只需要实现一些接口,就可以完成一个分布式程序,这个程序可以分布到大量廉价的 PC 机器上运行。
2)良好的扩展性
当计算资源不够的时候,通过增加机器就能扩展 MapReduce 的计算能力。
3)高容错性
MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,这就要求它具有很高的容错性。
如果某些机器发生了故障,MapReduce 可以把故障节点的计算任务转移到健康的节点上继续运行。
这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。
4)优秀的数据处理能力
MapReduce 将作业划分为多个节点,每个节点同时处理作业的一部分。
通过并行处理的方式,可以实现上千台服务器集群并发工作,完成 PB 级以上海量数据的离线处理,提高数据处理能力。
5)计算向数据靠拢
海量的数据分布在多个节点中,MapReduce 会在各个数据节点处理数据,而不是将数据移动到其他节点去计算。这有如下好处:
- 将处理单元移动到数据所在位置可以降低网络成本;
- 由于所有节点并行处理其部分数据,因此处理时间缩短;
- 每个节点都会获取要处理的数据的一部分,因此节点不会出现负担过重的可能性。
3.2 MapReduce 的限制
1)不能进行流式计算和实时计算,只能计算离线数据;
2)不擅长 DAG(有向无环图)计算,多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。为了解决这个问题,MapReduce 作业的中间结果都会写到磁盘,加大了磁盘的 I/O 负载,导致性能低下;
3)开发工作量大,例如简单的单词统计(wordcount),MapReduce 需要很多的设置和代码,而 Spark 实现起来会很简单。
参考资料
版权声明
出处:博客园-瘦风的南墙(https://www.cnblogs.com/shoufeng)
感谢阅读,公众号 「瘦风的南墙」 ,手机端阅读更佳,还有其他福利和心得输出,欢迎扫码关注🤝
本文版权归博主所有,欢迎转载,但 [必须在页面明显位置标明原文链接],否则博主保留追究相关人士法律责任的权利。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号