

HDFS 10 - HDFS 的联邦机制(Federation 机制)
1 - 为什么需要联邦
单 NameNode 的架构存在的问题:当集群中数据增长到一定规模后,NameNode 进程占用的内存可能会达到成百上千 GB(调大 NameNode 的 JVM 堆内存已无可能),此时,NameNode 成了集群的性能瓶颈。
为了提高 HDFS 的水平扩展能力,提出了 Federation(联邦,联盟)机制。
Federation 是 NameNode 的 Federation,也就是会有多个 NameNode,而多个 NameNode 也就意味着有多个 namespace(命名空间),不同于 HA 模式下 Active 和 Standby 有各自的命名空间,联邦环境下的多 NameNode 共享同一个 namespace。
来看一下命名空间在 HDFS 架构中的位置:
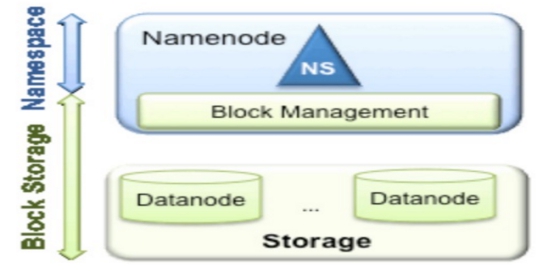
现有的 HDFS 可以简单分为 数据管理 和 数据存储 2层:
所有关于存储数据的信息和管理,都是由 NameNode 负责;
而真实数据的存储则是在各个 DataNode 下完成。
这些被同一个 NameNode 所管理的数据都在同一个 namespace 下,一个 namespace 对应一个Block Pool(所有数据块的集合)。
2 - Federation 架构设计
再强调一遍:HDFS Federation 是用来解决 NameNode 内存瓶颈问题的横向扩展方案。
Federation 意味着在集群中将会有多个 NameNode,这些 NameNode 相互独立且不需要协调,它们只需要管理自己所属的数据块即可。
分布式的 DataNode 作为公共的数据块存储设备,被所有的 NameNode 共用:每个 DataNode 都要向集群中所有的 NameNode 注册,且周期性地向所有 NameNode 发送心跳和块报告,并执行所有 NameNode 下发的命令。

Federation 架构中,DataNode上 会有多个 Block Pool 下,在 DataNode 的 datadir 目录下能看到以 BP-xx.xx.xx.xx 开头的目录。
从上图可以看出来:
多个 NameNode 共用一个集群里的所有存储资源,每个 NameNode 都可以单独对外提供服务;
每个 NameNode 都会定义一个 Block Pool,有单独的 id,每个 DataNode 都为所有 Block Pool 提供存储。
DataNode 会按照存储池 id 向其对应的 NameNode 汇报块信息,同时,DataNode 会向所有 NameNode 汇报本地存储可用资源情况。
3 HDFS Federation 的不足
HDFS Federation 并没有完全解决单点故障问题。
虽然集群中有多个 NameNode(namespace),但是从单个 NameNode(namespace)看,仍然存在单点故障:
如果某个 NameNode 服务发生故障,其管理的文件便不能被访问。
Federation 架构中每个NameNode 同样配有一个 Secondary NameNode,用于协助 NameNode 管理元数据信息(FSImage 和 EditLog)。
所以超大规模的集群,一般都会采用 HA + Federation 的部署方案,也就是每个联合的 NameNode 都是 HA 的,这样就解决了 NameNode 的单点故障问题 和 横向扩容问题。
版权声明
出处:博客园-瘦风的南墙(https://www.cnblogs.com/shoufeng)
感谢阅读,公众号 「瘦风的南墙」 ,手机端阅读更佳,还有其他福利和心得输出,欢迎扫码关注🤝
本文版权归博主所有,欢迎转载,但 [必须在页面明显位置标明原文链接],否则博主保留追究相关人士法律责任的权利。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号