论文阅读 | COMPRESSING BERT: STUDYING THE EFFECTS OF WEIGHT PRUNING ON TRANSFER LEARNING
模型压缩相关
本文研究对BERT的剪枝。结论:BERT可以在预训练时进行一次修剪,而不是在不影响性能的情况下对每个任务进行单独修剪。
针对不同水平的修剪:
低水平的修剪(30-40%)根本不会增加训练前的损失或影响下游任务的转移。中等水平的修剪会增加训练前的损失,并阻止有用的训练前信息传递给下游任务。这些信息对每个任务不是同等级别地有用; 任务随训练前损失线性下降,但速度不同。根据下游数据集的大小,高水平的修剪可能会通过阻止模型拟合下游数据集而进一步降低性能。最后,我们观察到,在特定任务上微调BERT并不能提高它的修剪能力,也不能显著地改变修剪的顺序。
几个词解释剪枝:Compression, Regularization, Sparse Architecture Search, 压缩,正则化,稀疏结构搜索。
权重修剪:
过程:
1. 选择一个目标的权重比例裁剪, 如50%。
2. 计算一个阈值,使50%的权重大小低于该阈值。
3. 删除这些权重。
4. 继续训练网络恢复精确度的损失。
5. 可选地,返回到步骤1并增加修剪的权重的百分比。
可以对所有网络参数整体计算阈值并进行剪枝(全局剪枝),也可以对每个权值矩阵分别进行剪枝(矩阵-局部剪枝)。这两种方法将修剪到相同的稀疏性,但在全局修剪中,稀疏性可能不均匀地分布在权重矩阵中。
实验
BERT-Base由12层编码器组成,每一个都包含6 个可剪枝矩阵:4个多头self-attention和2层的前馈网络的输出。
self-attention第一层输入为key query value。虽然每个注意头都有一个单独的键、查询和值矩阵,但实现通常会将每个注意头的矩阵堆叠起来,结果只有3个参数矩阵: 一个用于键,一个用于值,一个用于查询。我们分别对这些矩阵进行修剪,计算每个矩阵的阈值。我们还修剪了线性输出的matrix,它将每个注意力头的输出合并为一个单独的embedding。
修剪Word embedding 的方式和修剪FFN(feed-foward networks) 和self-attention的参数的方式相同。如果一个词的嵌入值接近于0,我们可以假设它是0,并将其存储在一个稀疏矩阵中。这是很有效的,因为token/subword embeddings往往占自然语言模型内存的很大一部分。在BERT BASE中,embedding的占模型内存的21%。
在预训练时剪枝
在预先训练的BERT BASE模型上进行了权值剪枝。选择以10%的增量从0%到90%的稀疏度,并在训练的前10k步逐步修剪BERT到这种稀疏度。继续在英语维基百科和图书语料库上进行预训练,再走90k步以恢复丢失的准确性。由此造成的预训练损失见表1。
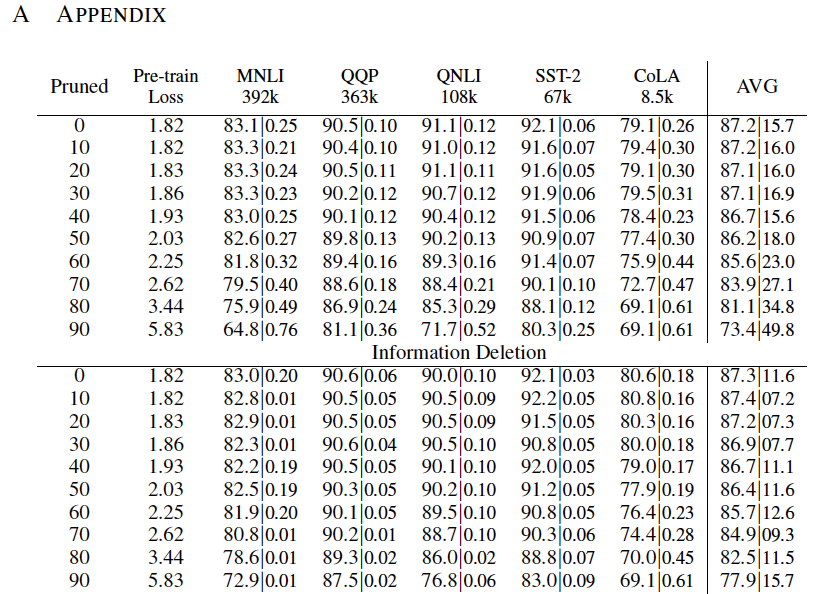
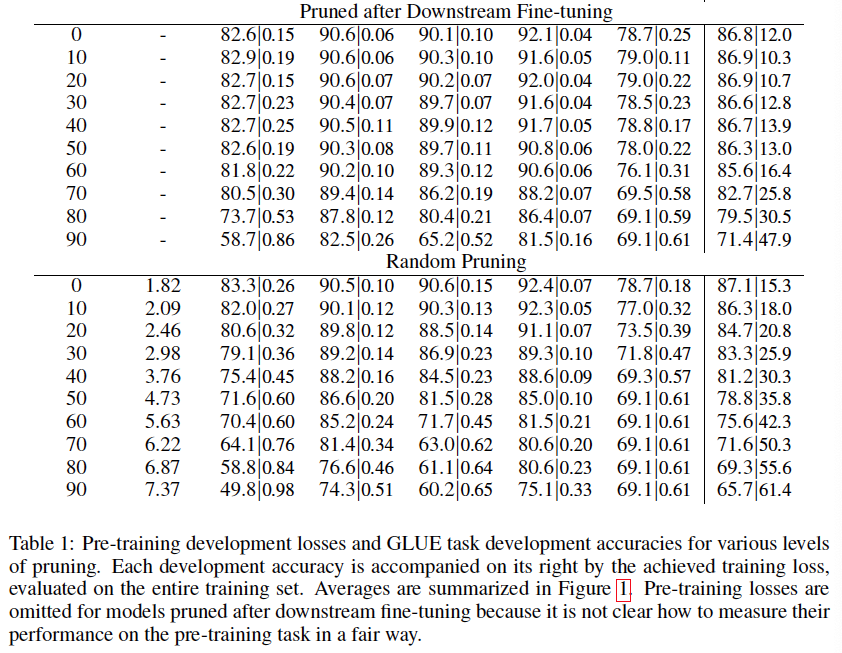
通过GLUE基准对修剪过的模型进行微调。其中,避免使用WNLI(公认有问题的)。避免使用5k以下的训练集==>noisy (RTE, MRPC, STS-B). fine-tune剩下的5个GLUE任务=> 3个epoch,尝试以下学习率:[2,3,4,5] * 10 -5
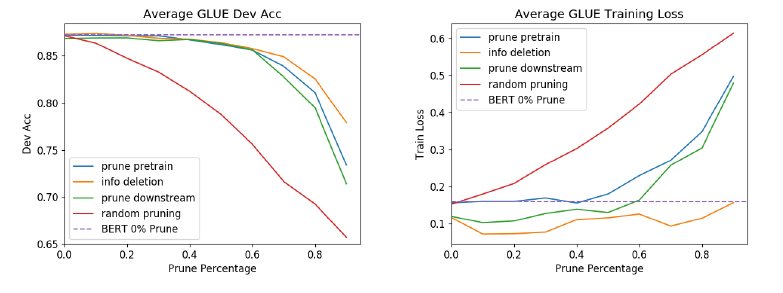
不同的剪枝模式
30 - 40%的weights影响不大
图1显示了30 - 40%的权重不影响训练的损失或下游任务的推理。这些权重可以在微调之前或之后进行修剪。可以在不影响网络输出的情况下削减这些权重 ==> 可以理解为去寻找一个足以解决问题的bert base的子网。
中等修剪水平不利于信息传递
超过40%的修剪,性能开始下降。预训练损失增加,因为我们削减了拟合预训练数据所需的权重(表1)。
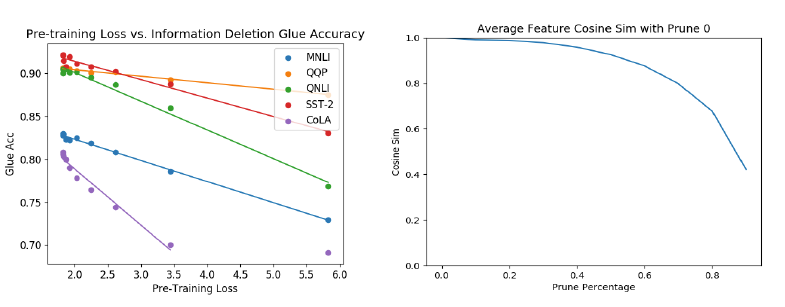
为什么影响了下游任务性能?
1. 修剪使得权重为0,删除了有用的信息;
2. 权重为0也阻止了下游数据拟合。
信息缺失是导致性能下降40% - 60%的主要原因,因为修剪和信息缺失对模型的影响是相同的。
压缩预训练模型的主要障碍是保持在预训练期间学习的模型的归纳偏置。与拟合下游数据集相比,对这种偏置进行编码需要更多的权重,而且由于预训练数据集与下游数据集之间存在基本信息差距,因此无法对其进行恢复。
一个模型可以修剪的数量受到模型所训练的最大数据集的限制:在这种情况下,是预训练的数据集。修剪可能会在不影响训练损失的情况下对下游的泛化产生潜移默化的伤害。
高修剪水平也会影响下游数据集的拟合
大数据集需要大的model去fit,如果复杂度受到限制会更容易出问题。剪枝对不同任务的影响程度不同,不确定是不是有预训练数据集和某些任务数据集相关性差异的问题,也不确定是不是因为某些任务有较大的数据集可以去学习特征(包含更多信息内容)。
下游的微调并不能改善修剪能力
由于在过度剪枝时,预训练的信息删除在性能下降中起着中心作用,我们预期下游的微调将通过使重要的权重更加突出(增加它们的大小)来提高剪枝能力。但实际上没有。
如果之后有机会再继续补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号