论文阅读及复现 | Effective Neural Solution for Multi-Criteria Word Segmentation
主要思想
这篇文章主要是利用多个标准进行中文分词,和之前复旦的那篇文章比,它的方法更简洁,不需要复杂的结构,但比之前的方法更有效。
方法
堆叠的LSTM,最上层是CRF。
最底层是字符集的Bi-LSTM。输入:字符集embedding,输出:每个字符的上下文特征表示。
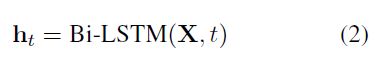
得到ht之后, CRF作为推理层。
打分:
local score:
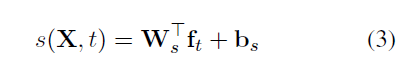
其中 ,![]() ,这一项是Bi-LSTM隐层ht和bigram 特征embedding的拼接。
,这一项是Bi-LSTM隐层ht和bigram 特征embedding的拼接。
global score:
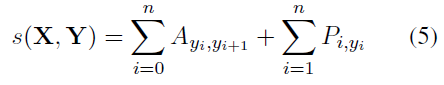
A是转移矩阵tag yi to tag yj.
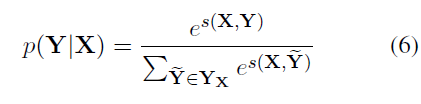

多标准CWS
在句子开头和结尾加token表明它使用哪一个标准。计算分数的时候再去掉。
训练
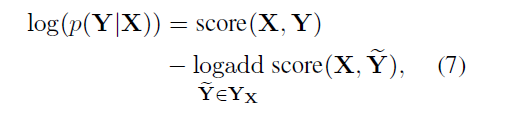
YX 表示句子X所有可能的 tag sequence。
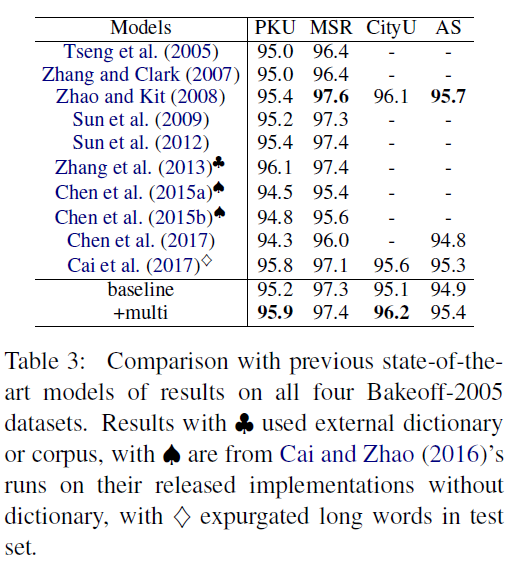
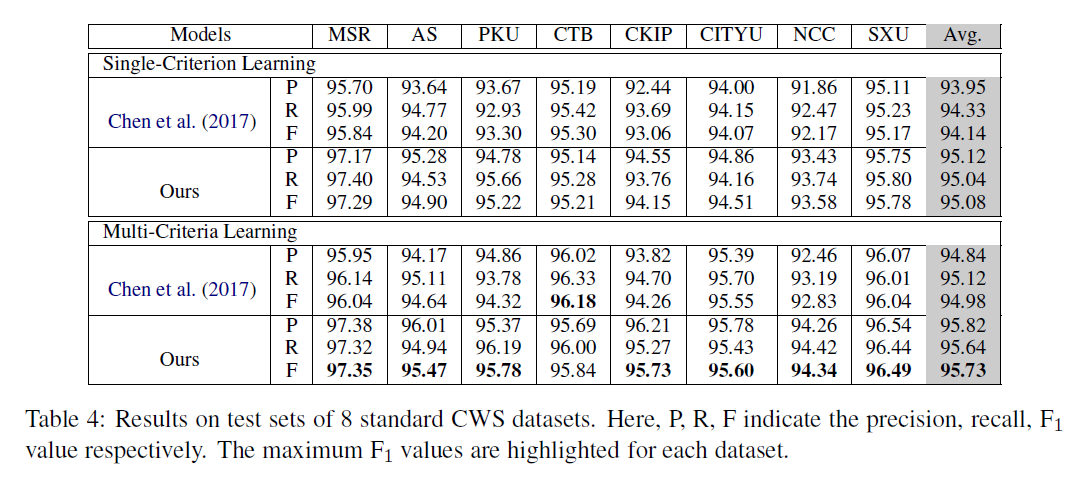
实验
1. 我们的多标准解决方案是否能够学习异构数据集?
2. 我们的解决方案能否应用于由微小和非正式文本组成的大规模语料库组?
3. 更多的数据,更好的性能?
based on Dynet (Neubig et al., 2017)
动态神经网络框架
数据集
Q1: SIGHAN2005
Q2 3: SIGHAN2008
所有数据集都是通过使用唯一的令牌替换连续的英文字符和数字进行预处理的。对于训练和开发集,行通过标点被分成更短的句子或子句,以便更快地进行批处理。
特别是传统的汉语语料库CityU、AS及CKIP均转换为简体版本,使用流行的中文NLP工具HanLP2。
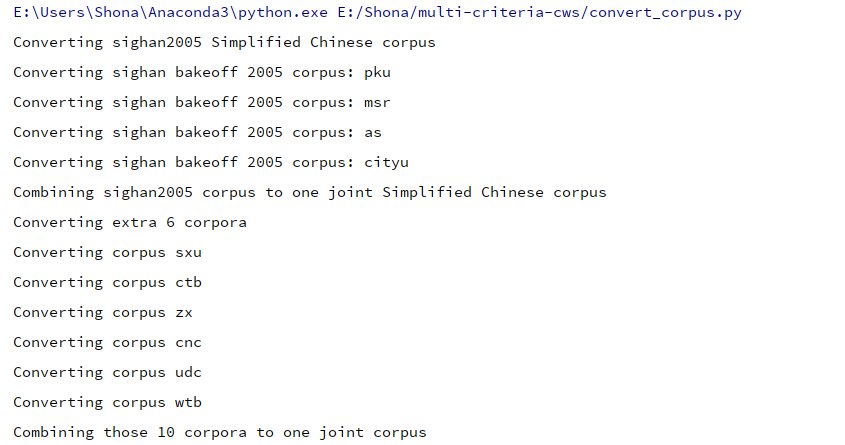
复现
1.
Run following command to prepare corpora, split them into train/dev/test sets etc.:
python3 convert_corpus.py
2. 生成pkl文件 pku的

3. make & train

 浙公网安备 33010602011771号
浙公网安备 33010602011771号