
[NLP] 相对位置编码(二) Relative Positional Encodings - Transformer-XL
1. Motivation
在Transformer-XL中,由于设计了segments,如果仍采用transformer模型中的绝对位置编码的话,将不能区分处不同segments内同样相对位置的词的先后顺序。
比如对于$segment_i$的第k个token,和$segment_j$的第k个token的绝对位置编码是完全相同的。
鉴于这样的问题,transformer-XL中采用了相对位置编码。
2. Relative Positional Encodings
paper中,由对绝对位置编码变换推导出新的相对位置编码方式。
vanilla Transformer中的绝对位置编码
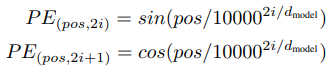
它对每个index的token都通过sin/cos变换,为其唯一指定了一个位置编码。该位置编码将与input的embedding求sum之后作为transformer的input。

那么如果将该位置编码应用在transformer-xl会怎样呢?

其中$\tau$表示第$\tau$个segment, ![]() 是当前segment的序列$s_{\tau}$的word embedding sequence, $L$是序列长,$d$是每个word embedding的维度。$U_{1:L}$表示该segment中每个token的绝对位置编码组成的序列。
是当前segment的序列$s_{\tau}$的word embedding sequence, $L$是序列长,$d$是每个word embedding的维度。$U_{1:L}$表示该segment中每个token的绝对位置编码组成的序列。
可以看到对于$h_{\tau + 1}$和$h_{\tau}$,其在位置编码表示是完全相同的,都是$U_{1:L}$,这样就会造成motivation中所述的无法区分在不同segments中相对位置相同的tokens.
3. Transformer-XL中的相对位置编码
transformer-xl中没有采用vanilla transformer中的将位置编码静态地与embedding结合的方式;而是沿用了shaw et al.2018的相对位置编码中通过将位置信息注入到求Attention score的过程中,即将相对位置信息编码入hidden state中。
为什么要这么做呢?paper中给出的解释是:
1) 位置编码在概念上讲,是为模型提供了时间线索或者说是关于如何收集信息的"bias"。出于同样的目的,除了可以在初始的embedding中加入这样的统计上的bias, 也可以在计算每层的Attention score时加入同样的信息。
2) 以相对而非绝对的方式定义时间偏差更为直观和通用。比如对于一个query vector $q_{\tau,i}$ 与 key vectors $k_{\tau, \leq i}$做attention时,这个query 并不需要知道每一个key vector在序列中的绝对的位置来决定segment的时序。它只需要知道每一对$k_{\tau,j}$ 和其本身$q_{\tau,i}$的相对距离(比如,i - j)就足够。
因此,在实际中可以创建一个相对位置编码的encodings矩阵 $R \in \mathbb{R} ^ {L_{max} \times d}$,其中第i行 $R_i$表示两个pos(比如位置pos_q, pos_k)之间的相对距离为i. (可以参考我在参考链接3中的介绍,以下图示便是一个简单的说明例子.
但是图示中的i表示query的位置pos, 与$R_i$ 中的i不同。如果以该图示为例,当pos_q = i, pos_k = i - 4时, 相对位置为 0, 二者的相对位置编码是 $R_0$。

--------------------------------------------------------------------------------------------------
Transformer-XL的相对位置编码方式是对Shaw et al.,2018 和 Huang et al.2018提出模型的改进。它由采用绝对编码计算Attention score的表达式出发,进行了改进3项改变。
若采用绝对位置编码,hidden state的表达式为:
,
那么对应的query,key的attention score表达式为:
(应用乘法分配率, query的embedding 分别与 key的embedding, positional encoding相乘相加;之后 query的positional encoding分别与 key的embedding, positional encoding相乘相加)
(其中i是query的位置index,j是key的位置index) (WE, WU是对embedding进行linear projection的表示,细节内容可以参看attention is all you need 中对multi-head attention的介绍)
 ,
,
Transformer-XL 对上式进行了改进:

改进1) $Uj \rightarrow R_{i - j}$.
首先将 $A_{i, j} ^ {abs}$ 中的key vector的绝对位置编码 $U_j$ 替换为了相对位置编码 $R_{i - j}$ 其中 $R$是一个没有需要学习的参数的sinusoid encoding matrix,如同Vaswani et al., 2017提出的一样。
该改进既可以避免不同segments之间由于tokens在各自segment的index相同而产生的时序冲突的问题。
改进2) $(c) : U_i^{T} W_q ^ {T} \rightarrow {\color{red} u} \in \mathbb{R}^d$;$(d) : U_i^{T} W_q ^ {T} \rightarrow {\color{red} v} \in \mathbb{R}^d$
在改进1中将key的绝对位置编码转换为相对位置编码,在改进2中则对query的绝对位置编码进行了替换。因为无论query在序列中的绝对位置如何,其相对于自身的相对位置都是一样的。这说明attention bias的计算与query在序列中的绝对位置无关,应当保持不变. 所以这里将$A_{i, j} ^ {abs}$ 中的c,d项中的$U_i^{T} W_q ^ {T}$分别用一个可学习参数$u \in \mathbb{R}^d$,$v \in \mathbb{R}^d$替换。
改进3) $W_{k} \rightarrow W_{k, E}$, $W_{k, R}$
在vanilla transformer模型中,对query, key分别进行线性映射时,query 对应$W_q$矩阵,key对应$W_k$矩阵,由于input 是 embedding 与 positional encoding的相加,也就相当于
$query_{embedding} W_q + query_{pos encoding} W_q$得到query的线性映射后的表征;
$key_{embedding} W_q + key_{pos encoding} W_q$ 得到key的线性映射后的表征。
可以看出,在vanilla transformer中对于embedding和positional encoding都是采用的同样的线性变换。
在改进3中,则将key的embedding和positional encoding 分别采用了不同的线性变换。其中$W_{k,E}$对应于key的embedding线性映射矩阵,$W_{k,R}$对应与key的positional encoding的线性映射矩阵。
在这样的参数化定义后,每一项都有了一个直观上的表征含义,(a)表示基于内容content的表征,(b)表示基于content的位置偏置,(c)表示全局的content的偏置,(d)表示全局的位置偏置。
与shaw的RPR的对比
shaw的RPR可以参考我在参考链接3中的介绍。这里给出论文中的表达式:其中$a_{i,j}$是query i, key j的相对位置编码矩阵$A$中的对应编码。
attention score: (在key的表征中加入相对位置信息)

softmax计算权值系数:

attention score * (value + 的output:(在value的表征中加入相对位置信息)

1) 对于$e_{ij}$可以用乘法分配率拆解来看,那么其相当于transforerm-xl中的(a)(b)两项。也就是在shaw的模型中未考虑加入(c)(d)项的全局内容偏置和全局位置偏置。
2) 还是拆解$e_{ij}$来看,涉及到一项为$x_iW^Q(a_{ij}^K)^T$,是直接用 query的线性映射后的表征 与 相对位置编码相乘;而在transformer-xl中,则是与query的线性映射后的表征 与 相对位置编码也进行线性映射后的表征 相乘。
优势:
paper中指出,shaw et al用单一的相对位置编码矩阵 与 transformer-xl中的$W_kR$相比,丢失掉了在原始的 sinusoid positional encoding (Vaswani et al., 2017)中的归纳偏置。而XL中的这种表征方式则可以更好地利用sinusoid 的inductive bias。
----------------------------为什么XL中的这种表征方式则可以更好地利用sinusoid 的inductive bias?--------------------------------------------------------------------
有几个问题:原始的 sinusoid positional encoding (Vaswani et al., 2017)中的归纳偏置是什么呢?为什么shaw et al 把它丢失了呢?为什么transformer-xl可以适用呢?
这里需要搞清楚:
1. 为什么在vanilla transformer中使用sinusoid?
2. shaw et al.2018中的相对位置编码Tensor是什么?
3. transformer-xl的相对位置编码矩阵是什么?
对于1,sinusoid函数具有并不受限于序列长度仍可以较好表示位置信息的特点。
We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training. ~Attention is all you need.
为什么不用学得参数而采用sinusoid函数呢?sinusoidal函数并不受限于序列长度,其可以在遇到训练集中未出现过的序列长度时仍能很好的“extrapolate.” (外推),这体现了其具有一些inductive bias。
对于2,shaw et al.2018中的相对位置编码Tensor是两个需要参数学习的tensor.
相对位置编码矩阵是设定长度为 2K + 1的(K是窗口大小) ,维度为$d_a$的2个tensor(分别对应与key的RPR和value的RPR),其第i行表示相对距离为i的query,key(或是query, value)的相对位置编码。这两个tensor的参数都是需要训练学习的。那么显然其是受限于最大长度的。在RPR中规定了截断的窗口大小,在遇到超出窗口大小的情况时,由于直接被截断而可能丢失信息。
对于3,transformer-xl的相对位置编码矩阵是一个sinusoid矩阵,不需要参数学习。
在transformer-xl中虽然也是引入了相对位置编码矩阵,但是这个矩阵不同于shaw et al.2018。该矩阵$R_{i,j}$是一个sinusoid encoding 的矩阵(sinusoid 是借鉴的vanilla transformer中的),不涉及参数的学习。
具体实现可以参看代码,这里展示了pytorch版本的位置编码的代码:
1 class PositionalEmbedding(nn.Module): 2 def __init__(self, demb): 3 super(PositionalEmbedding, self).__init__() 4 5 self.demb = demb 6 7 inv_freq = 1 / (10000 ** (torch.arange(0.0, demb, 2.0) / demb)) 8 self.register_buffer('inv_freq', inv_freq) 9 10 def forward(self, pos_seq, bsz=None): 11 sinusoid_inp = torch.ger(pos_seq, self.inv_freq) 12 pos_emb = torch.cat([sinusoid_inp.sin(), sinusoid_inp.cos()], dim=-1) 13 14 if bsz is not None: 15 return pos_emb[:,None,:].expand(-1, bsz, -1) 16 else: 17 return pos_emb[:,None,:]
其中$demb$是embedding的维度。
sinusoid的shape:[batch_size, seq_length × (d_emb / 2)]
sin,cos concat之后,pos_emb的shape:[batch_size, seq_length × d_emb]
pos_emb[:,None,:]之后的shape:[batch_size, 1, seq_length × d_emb]
那么综合起来看,transformer-xl的模型的hidden states表达式为:

4. 高效计算方法
在该表达式中,在计算$W_{k,R}R_{i-j}$时,需要对每一对(i,j)进行计算,时间复杂度是$O(n^2)$。paper中提出了高效的计算方法,使其降为$O(n).$
核心算法:发现(b)项组成的矩阵的行列之间的关系,构建一个矩阵,将其按行左移,恰好是(b)项矩阵$B$,而所构建的矩阵只需要$O(n)$时间。
由于相对距离(i-j)的变化范围是[0, M + L - 1] (其中M是memory的长度,L是当前segment的长度)
那么令:
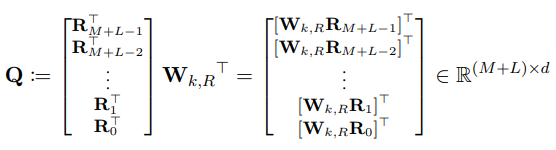
那么将(b)项应用与所有的(i,j)可得一个$L \times (M + L)$的矩阵 $B$: (其中q是对E经过$W_q$映射变换后的表示)
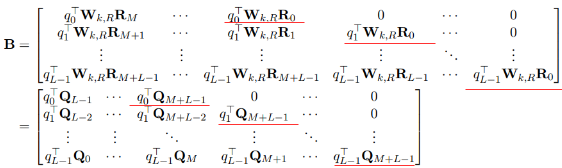
看这些带红线的部分,是不是只有q的下标不一样!
如果我们定义$\widetilde{B}$:

对比$B$与$\widetilde{B}$发现,将$\widetilde{B}$的第i行左移 $L - 1 - i$个单位即为$B$。而$\widetilde{B}$的计算仅涉及到两个矩阵的相乘,因此$B$的计算也仅需要求$qQ^T$之后按行左移即可得到,时间复杂度降为$O(n)$!
同理,可以求(d)项的矩阵D。


这样将B,D原本需要$O(n^2)$的复杂度,降为了$O(n)$.


5. 总结
Transformer-XL针对其需要对segment中相对位置的token加入位置信息的特点,将vanilla transformer中的绝对位置编码方式,改进为相对位置编码。改进中涉及到位置编码矩阵的替换、query全局向量替换、以及为key的相对位置编码和embedding分别采用了不同的线性映射矩阵W。
transformer-xl与shaw et al.2018的相对编码方式亦有区别。1. shaw et al.2018的相对编码矩阵是一个需要学习参数的tensor,受限于相对距离的窗口长度设置;而transformer-xl的相对编码矩阵是一个无需参数学习的使用sinusoid表示的矩阵,可以更好的generalize到训练集中未出现长度的长序列中;2. 相比与shaw et al.2018,transformer-xl的attention score中引入了基于content的bias,和基于位置的bias。
另外在计算优化上,transformer-xl提出了一种高效计算(b)(d)矩阵运算的方法。通过构造可以在$O(n)$时间内计算的新矩阵,并将其项左移构建出目标矩阵B,D的计算方式,将时间复杂度由$O(n^2)$降为$O(n)$。
参考:
1. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context: https://arxiv.org/pdf/1901.02860.pdf
2. Self-Attention with Relative Position Representations (shaw et al.2018): https://arxiv.org/pdf/1803.02155.pdf
3. [NLP] 相对位置编码(一) Relative Position Representatitons (RPR) - Transformer https://www.cnblogs.com/shiyublog/p/11185625.html
 [支付宝] 感谢您的捐赠!
[支付宝] 感谢您的捐赠!
That's been one of my mantras - focus and simplicity. Simple can be harder than complex: you have to work hard to get your thinking clean to make it simple. But it's worth it in the end beacuse once you get there, you can move mountains. ~ Steve Jobs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号