
python网络爬虫边看边学(selenium模块二无头浏览器)
selenium模块
一、无头浏览器
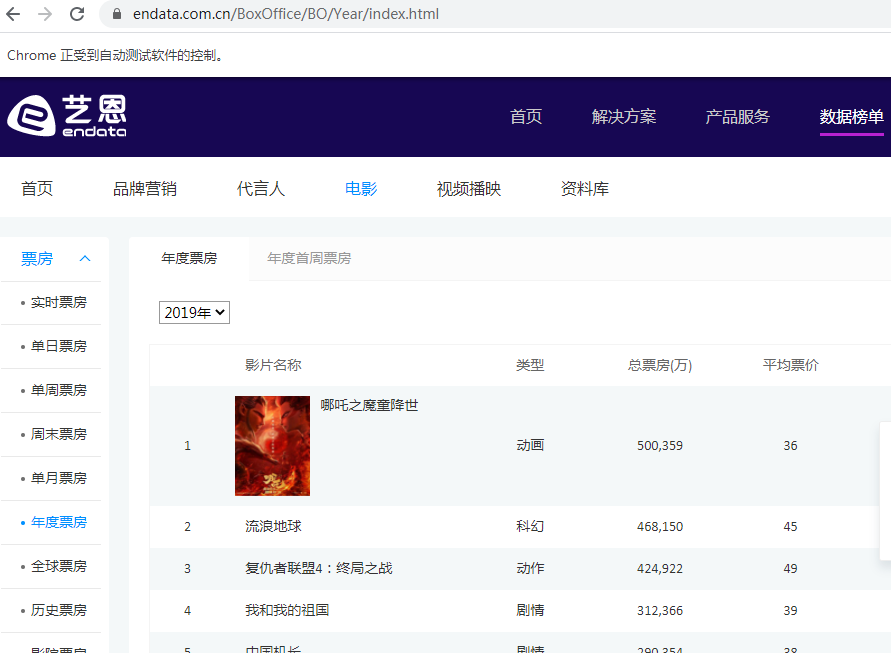
# 艺恩 https://www.endata.com.cn/BoxOffice/BO/Year/index.html 年度票房数据
# 带下拉列表
from selenium.webdriver import Chrome
from selenium.webdriver.support.select import Select
from selenium.webdriver.chrome.options import Options
import time
# 准备好参数设置
opt=Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
web = Chrome(options=opt) #把参数设置到浏览器中
web.get('https://www.endata.com.cn/BoxOffice/BO/Year/index.html')
#定位到下拉列表
sel_el= web.find_element_by_xpath('//*[@id="OptionDate"]')
# 对元素进行包装,包装成下拉菜单
sel=Select(sel_el)
#让浏览器进行调整选项
for i in range(len(sel.options)): #i就是每一个下拉框的索引位置
sel.select_by_index(i) # 按照索引
time.sleep(2)
table = web.find_element_by_xpath('//*[@id="TableList"]/table')
print(table.text) # 打印文本信息
print('*'*100)
web.close()
# web.page_source 页面代码elements(经过数据加载以及js执行后的代码)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号