
python爬虫边看边学(requests模块)
requests模块
在网页抓取中,有一个强大的requests库能够让你轻易地发送HTTP请求,这个库功能完善,而且操作非常简单。requests是第三方模块,我们相爱使用前必须安装该模块,安装方法:
pip install requests
安装源服务器在国外,速度较慢,如果安装失败或提高安装速度,可以换源:
pip install -i http://pypi.douban.com/simple/ requests,直至安装成功。
案例一:get请求
# 抓取搜狗搜索内容
kw = input("请输入你要搜索的内容:")
headers = {'User-Agent': 'Mozilla/5.0 (Windows;U;Windows NT 6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
response =requests.get(f"https://www.sogou.com/web?query={kw}",headers=headers) # 发送get请求
# print(response.text) # 直接拿结果(文本)
with open("sogou.html", mode="w", encoding="utf-8") as f:
f.write(response.text)
response.close()
打开搜狗网站,右击页面选择“检查”,如下图:
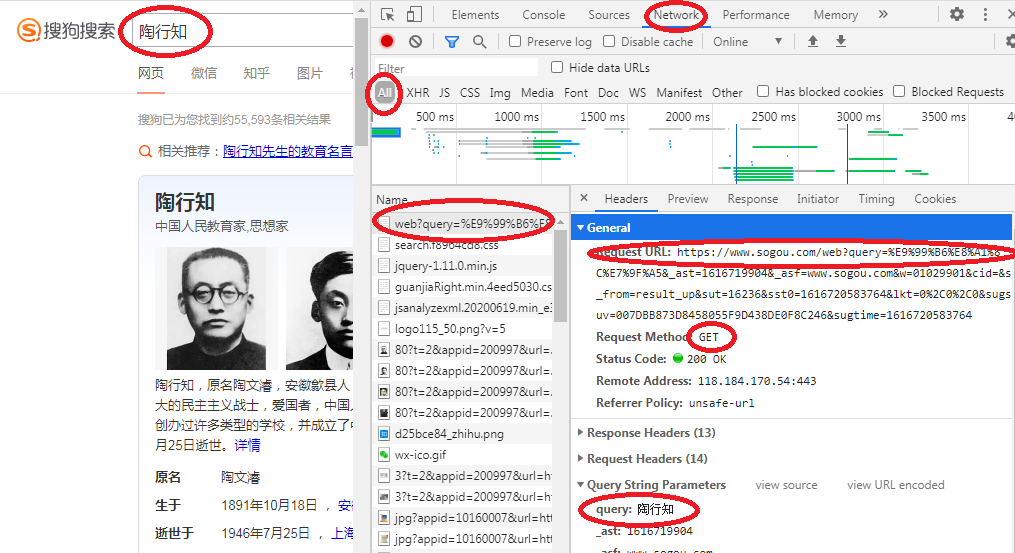
案例二:post请求
import requests
url = 'https://fanyi.baidu.com/sug'
s = input('请输入你要翻译的英文单词:')
dat = {
'kw': s # 这里要和抓包工具里的参数一致
}
#百度翻译的sug这个url,它是通过post方式进行提交的,所以要模拟post请求
resp = requests.post(url, data=dat)
# 返回值是json,可以直接解析成json
resp_json=resp.json()
# {'errno': 0, 'data': [{'k': 'dog', 'v': 'n. 狗; 蹩脚货; 丑女人; 卑鄙小人 v. 困扰; 跟踪'}, {'k': 'DOG', 'v': 'abbr. Data...
print(resp_json['data'][0]['v'])
# 请输入你要翻译的英文单词:friend
# n. 朋友,友人; 资助者; 助手; 近亲 v. <诗>与…为友
resp.close()
打开百度翻译,右击页面选择“检查”,如下图: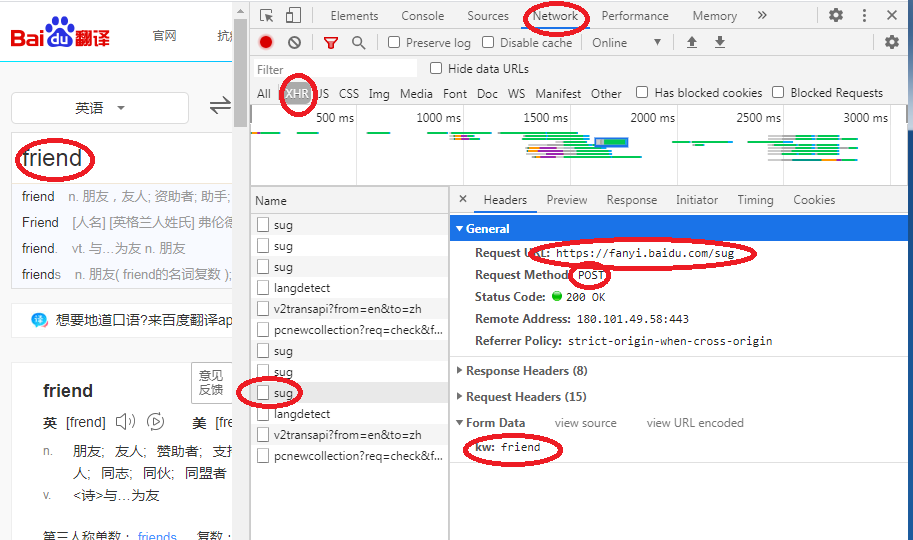
案例三:跟进版
import requests
url = 'https://movie.douban.com/j/chart/top_list'
headers = {'User-Agent': 'Mozilla/5.0 (Windows;U;Windows NT 6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
param = {
'type': '24',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20',
}
resp = requests.get(url, params=param, headers=headers) # get请求,参数是params
# resp.json返回列表
for movie in resp.json():
print(f'电影名:{movie["title"]},主演:{movie["actors"]}')
# 电影名:憨豆先生精选辑,主演:['罗温·艾金森', '保罗·布朗', '理查德·布赖尔斯', '安格斯·迪顿', '罗宾·德里斯科尔', '卡罗琳·昆汀', '鲁道夫·沃克尔', '理查德·威尔逊']
# 电影名:美丽人生,主演:['罗伯托·贝尼尼', '尼可莱塔·布拉斯基', '乔治·坎塔里尼', '朱斯蒂诺·杜拉诺', '赛尔乔·比尼·布斯特里克', '玛丽萨·帕雷德斯', '霍斯特·布赫霍尔茨', '利迪娅·阿方西', '朱利亚娜·洛约迪切', '亚美利哥·丰塔尼', '彼得·德·席尔瓦', '弗朗西斯·古佐', '拉法埃拉·莱博罗尼', '克劳迪奥·阿方西', '吉尔·巴罗尼', '马西莫·比安奇', '恩尼奥·孔萨尔维', '吉安卡尔洛·科森蒂诺', '阿伦·克雷格', '汉尼斯·赫尔曼', '弗兰科·梅斯科利尼', '安东尼奥·普雷斯特', '吉娜·诺维勒', '理查德·塞梅尔', '安德烈提多娜', '迪尔克·范登贝格', '奥梅罗·安东努蒂', '沈晓谦', '张欣']
# 电影名:福尔摩斯二世,主演:['巴斯特·基顿', '凯瑟琳·麦奎尔', '乔·基顿', 'Ward Crane', 'Jane Connelly', 'George Davis', 'Doris Deane', 'Betsy Ann Hisle', '丘比·摩根', 'John Patrick', 'Ford West']
# 电影名:黄子华栋笃笑之金盆𠺘口,主演:['黄子华']...
resp.close()
打开豆瓣电影,右击页面选择“检查”,如下图: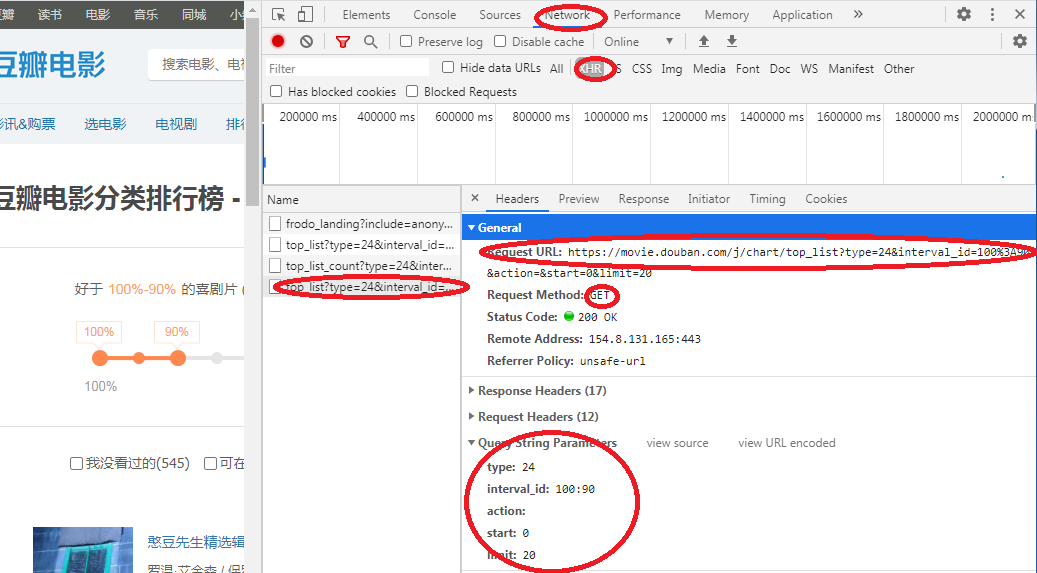
案例四:爬取视频
# ajax 异步加载:实现页面的局部刷新,刷新的数据都是动态数据<在网页的源代码中找不到的数据>
import requests
import re
def change_title(title):
pattern=re.compile(r'[\\\/\:\*\?\"\<\>\|]')
new_title=re.sub(pattern,'_',title)
return new_title
# 准备数据
url='https://api-tinyvideo-web.yy.com/home/tinyvideosv2'
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36'
}
params={
'data': '{"uid":0,"page":1,"pageSize":10}'
}
# 发送请求
resp=requests.get(url,headers=headers,params=params)
result=resp.json()
# 数据解析
data_list=result['data']['data'] #列表数据
for data in data_list:
video_title=data['username']+'.mp4' # 视频文件名
video_url=data['resurl'] # 视频的url
#请求视频数据
video_data=requests.get(video_url,headers=headers).content
#调用替换函数
new_video_title=change_title(video_title)
#保存数据
with open('video\\'+new_video_title,mode='wb') as f:
f.write(video_data)
print(f'保存完成:{video_title}')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号