
python爬虫边看边学(基础)
网络爬虫(Web Spider)
一、什么是网络爬虫
百度百科是这么说的:网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫最重要的应用就是搜索引擎。搜索引擎使用网络爬虫抓取Web网页、文档甚至图片、音频、视频等资源,通过相应的索引技术组织这些信息,提供给搜索用户进行查询。网络爬虫也为中小站点的推广提供了有效的途径。
用python写网络爬虫语法优美、代码简洁、开发效率高、支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富。还有Scrapy和Scrapy-redis框架让我们开发爬虫变得异常简单。
二、python网络爬虫的流程
网络爬虫的流程其实非常简单,主要可以分为三部分:(1)获取网页;(2)解析网页(提取数据);(3)存储数据。

(1)获取网页就是给一个网络发送请求,该网址会返回整个网页的数据。类似于在浏览器中键入网址并按回车键,然后可以看到网站的整个页面。
(2)解析网页就是从整个网页的数据中提取想要的数据。类似于在浏览器中看到网站的整个页面,如果你想找的是产品的价格,价格就是你想要的数据。
(3)存储数据也很容易理解,就是把数据存储下来,我们可以存储在csv中,也可以存储在数据库中。
三、技术实现
1、获取网页
获取网页的基础技术:request、urllib和selenium(模拟浏览器)。
获取网页的进阶技术:多进程多线程抓取、登录抓取、突破IP封禁和服务器抓取。
2、解析网页
解析网页的基础技术:re正则表达式、BeautifulSoup和lxml。
解析网页的进阶技术:解决中文乱码。
3、存储数据
存储数据的基础技术:存入txt文件和存入csv文件。
存储数据的进阶技术:存入MySQL数据库和存入MongoDB数据库。
四、编写第一个简单的爬虫
1、第一步:获取页面
import requests
link = r'https://www.cnblogs.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows;U;Windows NT 6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers=headers)
print(r.text)
上述代码获取了博客园首页的HTML代码。首先import requests,使用requests.get(link,headers=headers)获取网页。
(1)用requests的headers伪装成浏览器访问。
(2)r是requests的Response回复对象,我们从中可以获取想要的信息。R.text是获取的网页内容代码。
2、第二步:提取需要的数据
import requests
from bs4 import BeautifulSoup
link = r'https://www.cnblogs.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows;U;Windows NT 6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
title = soup.find("a", class_='post-item-title').text.strip()
print(title)
在获取整个页面的HTML代码后,需要从整个网页中提取第一篇文章的标题。
这里用到BeautifulSoup库对爬下来的页面进行解析。首先需要导入这个库,然后把HTML代码转化为soup对象,接下来用soup.find(“a”,class_=’post-item-title’).text.strip()得到第一篇文章的标题,并且打印下来。
那么,我们怎么从那么长的代码中准确找到标题的位置呢?使用Chrome浏览器的“检查(审查元素)”功能就能找到元素的位置。
(1)使用chrome浏览器打开博客网首页www.cnblogs.com。右击网页页面,在弹出的快捷菜单中单击“检查”命令,或按F12。
(2)出现下图审查元素页面。单击上方的鼠标键按钮,然后在页面上单击想要的数据,下面的Elements会出现相应的code所在的地方,就定位到想要的元素了。
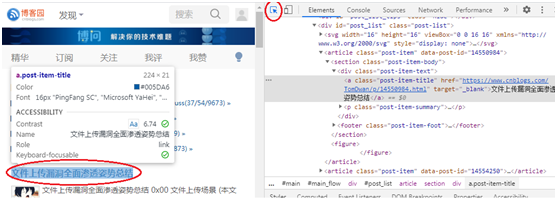
(3)在代码中找到深色的地方,为<a class=”post-item-title” href=https://www.cnblogs.com/TomDwan/p/14550984.html target=’_blank’>文件上传漏洞全面渗透姿势总结</a>。可以用soup.find("a", class_='post-item-title').text.strip()提取标题。
3、第三步:存储数据
import requests
from bs4 import BeautifulSoup
link = r'https://www.cnblogs.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows;U;Windows NT 6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
title = soup.find("a", class_='post-item-title').text.strip()
print(title)
with open('title.txt', 'a',encoding='utf-8') as f:
f.write(title)
存储到本地的txt文件非常简单,在第二步的基础上加2行代码就可以实现。txt文件地址应该和python文件放在同一个文件夹。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号