
python正则表达式1
正则表达式
许多程序设计语言都支持利用正则表达式进行字符串操作。在python中需要通过正则表达式对字符串进行匹配的时候,可以使用re模块。re模块使python语言拥有全部的正则表达式功能。
特点:
- 灵活性、逻辑性和功能性非常强;
- 可以迅速地用极其简单的方式达到字符串的复杂控制。
一、python中的正则表达式
print(re.match('\\\\','\hello')) #需要使用4个反斜杠来匹配一个 \
python里的原生字符串很好地解决了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。在python字符串前面添加 r 即可将字符串转换为原生字符串。(r:raw string)
print(re.match(r'\\','\hello')) #使用两个反斜杠即可匹配一个 \
一个例子:
import re
x='hello\\nworld' #hello\nworld
#在正则表达式里,如果想要匹配一个 \ ,需要使用\\\\
#第一个参数就是正则匹配规则
#第二个参数表示需要匹配的字符串
#m=re.search('\\\\',x) match和search
#还可以在字符串前面加r,\\就表示\
m=re.search(r'\\',x)
#search和match方法的执行结果是一个Match类型的对象
print(m) #<re.Match object; span=(5, 6), match='\\'>
二、查找方法的使用
- match方法(只匹配字符串开头)
-
search方法(扫描整个字符串,找到第一个匹配)
- findall方法(扫描整个字符串,找到所有的匹配)
-
finditer方法(扫描整个字符串,找到所有的匹配,并返回要给可迭代对象)
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None。
re.match(pattern,string,flags=0)
|
参数
|
描述
|
|
pattern
|
匹配的正则表达式
|
|
string
|
要匹配的字符串
|
|
flags
|
标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等。
|
使用group(num)函数来获取匹配表达式
import re result1=re.match(r'He','Hello') result2=re.match(r'e','Hello') print(result1.group(0)) # 'He' 匹配到的元素 print(result1.span()) # (0, 2) 匹配元素的位置,从0位到1位,2不包括内 print(result2) # None 没匹配到
2、search方法的使用
re.search(pattern,string,flags=0)
应用:
import re result1=re.search(r'he','hello') result2=re.search(r'lo','hello') print(result1.group(0)) #he print(result1.span()) #(0,2) print(result2.group(0)) #lo print(result2.span()) #(3,5) 不包括第5位
re.match与re.search的区别
import re result1=re.search(r'天气','今天天气真好!') result2=re.match(r'天气','今天天气真好!') print(result1) # <re.Match object; span=(2, 4), match='天气'> print(result2) # None
3、findall方法的使用
re.findall(pattern,string,flags=0)
应用:
ret=re.findall(r'\d+','h12ab34') print(ret) #['12', '34'] ret=re.match(r'\d+','h12ab34') print(ret) #None match只匹配开头,所以没匹配到 ret=re.search(r'\d+','h12ab34') print(ret) #<re.Match object; span=(0, 2), match='12'> 只匹配一次
4、finditer方法的使用
from collections.abc import Iterable
mm=re.finditer(r'c','agcegcklclexce9')
print(isinstance(mm, Iterable)) #True
for m in mm:
print(m)
#<re.Match object; span=(2, 3), match='c'>
#<re.Match object; span=(5, 6), match='c'>
#<re.Match object; span=(8, 9), match='c'>
#<re.Match object; span=(12, 13), match='c'>
for m in mm:
print(m.group(),m.span()) #匹配对象里的group保存了匹配的结果
#c (2, 3)
#c (5, 6)
#c (8, 9)
#c (12, 13)
5、fullmatch方法的使用
m4=re.fullmatch(r'he','hello') #None m4=re.fullmatch(r'hello','hello') #<re.Match object; span=(0, 5), match='hello'>
当我们调用re.match方法、re.search方法,或者对re.finditer方法的结果进行迭代时,结果是re.Match对象。
x=re.match(r'h','hello')
#<re.Match object; span=(0, 1), match='h'>
y=re.search(r'e','hello')
z=re.finditer(r'l','hello')
print(type(x)) #<class 're.Match'>
print(type(y)) #<class 're.Match'>
for a in z:
print(type(a)) #<class 're.Match'>
|
属性和方法
|
说明
|
|
pos
|
搜索的开始位置
|
|
endpos
|
搜索额结束位置
|
|
string
|
搜索的字符串
|
|
re
|
当前使用的正则表达式的对象
|
|
lastindex
|
最后匹配的组索引
|
|
lastgroup
|
最后匹配的组名
|
|
group(index=0)
|
某个分组的匹配结果,如index=0,便是匹配整个正则表达式
|
|
group()
|
所有分组的匹配结果,每个分组的结果组成一个列表返回
|
|
groupdict()
|
返回组名作为key,每个分组的匹配结果作为value的字典
|
|
start([group])
|
获取组的开始位置
|
|
end([group])
|
获取组的结束位置
|
|
span([group])
|
获取组的开始和结束位置
|
|
expand(template)
|
使用组的匹配接过来替换模板template中的内容,并把替换后的字符串返回
|
import re
ret=re.search(r'm.*a','odabdmjadasdef')
print(ret.pos,ret.endpos) #搜索开始和结束的位置,默认是0和字符串长度
print(ret.group()) #mjada 贪婪模式
print(ret.group(0)) #mjada
print(ret.group(1)) #报错,no such group
#1、在正则表达式里使用()表示一个分组
#2、如果没有分组,默认只有一组
#3、分组的下标从0开始
mm=re.search(r'(9.*)(0.*)(5.*7)','fd9dfeca0egfdl5juipxn7xbzi')
print(mm.group(0)) #第0组就是把整个正则表达式当做一个整体 9dfeca0egfdl5juipxn7
print(mm.group()) #默认就是第0组
print(mm.group(1) #第一个()里对应的 9dfeca
print(mm.groups()) #('9dfeca', '0egfdl', '5juipxn7')
#?P<name>表达式 可以给分组起名
mmm=re.search(r'(9.*)(?<middle>0.*)(5.*7)','fd9dfeca0egfdl5juipxn7xbzi')
print(mmm.groupdict()) #{'middle': '0egfdl'}
print(mmm.group('middle')) #0egfdl 通过分组名获取到分组里匹配的字符串
print(mmm.span(1)) #(2, 8) 获取第一个分组的起始位置和结束位置,包前不包后
四、re.compile方法的使用
import re
ret=re.search(r'm.*a','odabdmjadasdef')
print(ret) #<re.Match object; span=(5, 10), match='mjada'>
r=re.compile(r'm.*a')
s=r.search('odabdmjadasdef')
print(s) #<re.Match object; span=(5, 10), match='mjada'>
在python里面,在大多数情况下真的不需要使用re.compile!

在re里的compile方法里,同样返回_compile()
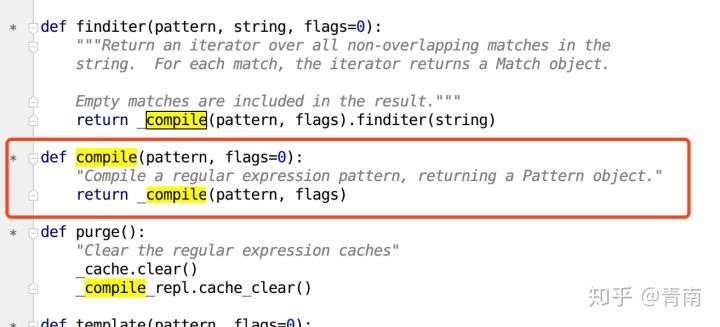
我们常用的正则表达式方法,都已经自带compile了!根本没有必要多此一举re.compile再调用正则表达式方法。
而_compile()方法的源代码里自带缓存。它会自动储存最多512条由type(pattern), pattern, flags)组成的Key,只要是同一个正则表达式,同一个flag,那么调用两次_compile时,第二次会直接读取缓存。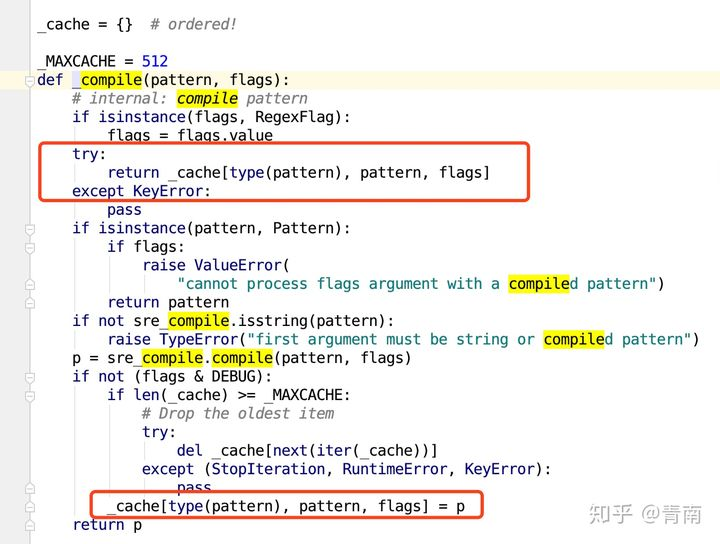
所以,再大多数情况下不需要手动调用re.compile,除非你的项目涉及到几百万以上的正则表达式查询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号