
第17课 - ++和--操作符分析
第17课 - ++和--操作符分析
1. ++和--操作符对应的两条汇编指令
(1)前置++/--对应的两条汇编指令:变量自增(减)1;然后取变量值
(2)后置++/--对应的两条汇编指令:先取变量值;然后变量自增(减)1
上面两条规则很简单,那 ++ 和 -- 操作符是不是就不需要研究了呢?我们使用VS2010和gcc编译执行下面的代码,观察输出结果是否与我们预期的一致。
1 #include <stdio.h> 2 3 int main() 4 { 5 int i = 0; 6 int r = 0; 7 8 r = (i++) + (i++) + (i++); 9 10 printf("i = %d\n", i); 11 printf("r = %d\n", r); 12 13 r = (++i) + (++i) + (++i); 14 15 printf("i = %d\n", i); 16 printf("r = %d\n", r); 17 return 0; 18 }
我们的预期是:
r = (i++) + (i++) + (i++); // r = 0 + 1 + 2 = 3 i自增三次后 i = 3
r = (++i) + (++i) + (++i); // r = 4 + 5 + 6 = 15 i又自增三次后 i = 6
使用gcc编译器编译,程序执行结果如下:

使用VS2010编译器编译,程序执行结果如下:
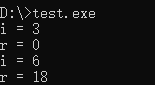
可见两款编译器对于 r 的输出结果与我们的预期都不同,那为何会这样呢?我们从汇编代码中寻找原因。
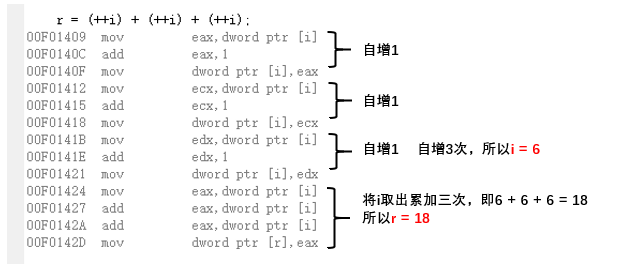
VS2010汇编代码
分析 r = (i++) + (i++) + (i++); 在VS2010中对应的汇编代码

再分析接下来的 r = (++1) + (++i) + (++i); 在VS2010中对应的汇编代码如下
gcc对应的汇编代码
使用 objdump -d -S 对代码进行反汇编 暂时分析不好下面的汇编指令。。。。。等掌握了再把结果补上。。。。。。
1 r = (i++) + (i++) + (i++); 2 400543: 8b 55 f8 mov -0x8(%rbp),%edx 3 400546: 8d 42 01 lea 0x1(%rdx),%eax 4 400549: 89 45 f8 mov %eax,-0x8(%rbp) 5 40054c: 8b 45 f8 mov -0x8(%rbp),%eax 6 40054f: 8d 48 01 lea 0x1(%rax),%ecx 7 400552: 89 4d f8 mov %ecx,-0x8(%rbp) 8 400555: 8d 0c 02 lea (%rdx,%rax,1),%ecx 9 400558: 8b 45 f8 mov -0x8(%rbp),%eax 10 40055b: 8d 50 01 lea 0x1(%rax),%edx 11 40055e: 89 55 f8 mov %edx,-0x8(%rbp) 12 400561: 01 c8 add %ecx,%eax 13 400563: 89 45 fc mov %eax,-0x4(%rbp) 14 15 16 r = (++i) + (++i) + (++i); 17 40058e: 83 45 f8 01 addl $0x1,-0x8(%rbp) 18 400592: 83 45 f8 01 addl $0x1,-0x8(%rbp) 19 400596: 8b 45 f8 mov -0x8(%rbp),%eax 20 400599: 8d 14 00 lea (%rax,%rax,1),%edx 21 40059c: 83 45 f8 01 addl $0x1,-0x8(%rbp) 22 4005a0: 8b 45 f8 mov -0x8(%rbp),%eax 23 4005a3: 01 d0 add %edx,%eax 24 4005a5: 89 45 fc mov %eax,-0x4(%rbp)
从上面的分析结果来看,两款编译器对于 ++ 和 -- 操作符的混合运算的处理并不相同,
2. C标准对++和--运算符的规定
(1)C语言只规定了 ++ 和 -- 对应指令的相对执行次序,并没有要求两条汇编指令的执行是连续的,所以两条汇编指令中间可能会被其它指令打断!
(2)在混合运算中,++ 和 -- 的汇编指令可能被打断执行,因此 ++ 和 -- 参与混合运算结果是不确定的,就出现了前面两款编译器的差别。
※ 这也告诉我们,在实际工程开发中不要将 ++ 和 -- 参与到混合运算中!!!
这里额外看下Java中对++ 和 -- 混合运算的操作
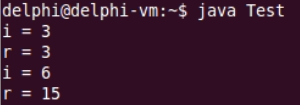
1 class Test { 2 public static void main(String[] args) { 3 int i = 0; 4 int r = 0; 5 6 r = (i++) + (i++) + (i++); 7 8 System.out.println("i = " + i); 9 System.out.println("i = " + i); 10 11 r = (++i) + (++i) + (++i); 12 13 System.out.println("i = " + i); 14 System.out.println("i = " + i); 15 } 16 }
编译执行,可见在Java中的结果和我们之前预期的是相同的。
3. 笔试面试中的奇葩题
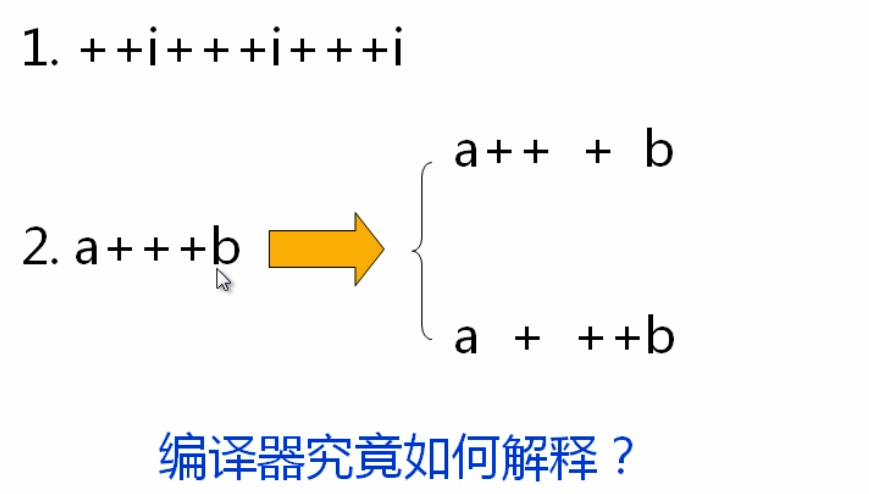
要想知道编译器如何解释上面表达式中的++/--,首先要了解一下C编译器的贪心法。
贪心法:++/-- 表达式的阅读技巧
(1)编译器处理的每个符号应该尽可能多的包含字符
(2)编译器以从左向右的顺序一个一个尽可能多的读入字符
(3)当读入的字符不可能和已读入的字符组成合法符号为止
根据贪心法分析前面的问题:
1 // 读入第1个字符+,因为它可以与其它符号组合,于是继续读入第2个字符+, 2 // 编译器发现两个+形成一个自增运算符,会继续读入后面的变量i,得到++i。 3 // 但根据贪心法,还会再读入一个字符,即++i+,表示++i后面会加上一个数,这也是有意义的。 4 // 所以会再读入第5个字符,发现读入的字符不能变成一个有意义符号,所以停止读入字符 5 // 然后去计算 ++i++ 这个表达式,得到1++,显然语法上是错误的 6 ++i+++i+++i; 7 8 a+++b; // 读到a++是有意义的,会再读入一个字符+,仍有意义,会再次读入b,即(a++) + b;
再想到之前我们讲解C注释时的一个例子:
y= x/*p;
根据贪心算法,编译器读取到 / 之后还会再读取 *,然后就把 /* 组合在一起,就是多行注释了,当时的解决办法是再 / 前后加上空格,即 y = x / *p; 为什么这样就可以了呢?
空格可以作为C语言中一个完整符号的休止符,编译器读入空格后立即对之前读入的符号进行处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号