

XML学习笔记
XML学习笔记
起因:学习设计模式的工厂模式的时候想要自己设置xml配置来实现工厂获取对象
基础使用
基础启动
这里我先主要讲文档对象(Document)和节点(Node)对象怎么获得
下一节讲操作节点对象--如果只想了解操作的可以直接到下面去看
public static void main(String[] args) {
//1.创建DocumentBuilderFactory对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//2.创建DocumentBuilder对象
try {
DocumentBuilder builder = factory.newDocumentBuilder();
Document d = builder.parse(Test.class.getClassLoader().getResourceAsStream("demo.xml"));
NodeList sList = d.getElementsByTagName("student");
System.out.println(sList.getClass());
// element(sList);
// System.out.println("===============");
node(sList);
} catch (Exception e) {
e.printStackTrace();
}
}
//下面这个方法是遍历NodeList节点-我放到下面讲--这里的东西太多了-,-
public static void node(NodeList list){
for (int i = 0; i <list.getLength() ; i++) {
Node node = list.item(i);
System.out.println("_____________________"+"".trim());
NamedNodeMap attributes = node.getAttributes();
Node rollno = attributes.getNamedItem("rollno");
System.out.println(rollno);
System.out.println("_____________________");
NodeList childNodes = node.getChildNodes();
for (int j = 0; j <childNodes.getLength() ; j++) {
if (childNodes.item(j).getNodeType()==Node.ELEMENT_NODE) {
System.out.print(childNodes.item(j).getNodeName() + ":");
System.out.println(childNodes.item(j).getFirstChild().getNodeValue());
}
}
System.out.println("==========!!!!!!!!!!!!!");
}
}
-
第一行
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();这个是DocumentBuilder的获取方法 -
DocumentBuilder builder = factory.newDocumentBuilder();通过DocumentBuilder工厂获得DocumentBuilder对象 -
Document d = builder.parse(Test.class.getClassLoader().getResourceAsStream("demo.xml"));
Test.class.getClassLoader().getResourceAsStream("demo.xml");
//这里通过类加载器获取项目文件目录下的demo.xml文件
//注意的是普通项目是放在src下,而maven项目是放在resource目录下,我在下面问题那里有写
//注意的是如果使用的是下面的public Document parse(String uri)方法
//必须要填写绝对路径才能获取,不然会出问题--在idea里(是项目下的模块,而这个方法定位的是项目,所以会出问题,可以自己去试试)
通过工厂的parse(解析)方法解析文件地址获得xml文件的对应Document文档对象
-
该方法有多个重载
-
![image-20210314071934214]()
//这里我讲最后一种,因为其他的都是他的变式,可以去自行翻阅源码 /** * public Document parse(InputStream is)这个是通过输入流构建InputSource * InputSource in = new InputSource(is);然后调用最后一个方法 * public Document parse(InputStream is, String systemId)这个是通过输入流和id构造InputSource * InputSource in = new InputSource(is); * in.setSystemId(systemId);然后调用最后一个方法 * public Document parse(String uri)通过uri构建InputSource * InputSource in = new InputSource(uri);然后调用最后一个方法 * public Document parse(File f) throws SAXException, IOException根据File对象构建InputSource * InputSource in = new InputSource(f.toURI().toASCIIString());然后调用最后一个方法 */ //DocumentBuilder是抽象类--其中这个方法是抽象方法 public abstract Document parse(InputSource is) throws SAXException, IOException; //我们到他的实现子类(DocumentBuilderImpl,需要注意的是在javaSE中只有这一个直接实现子类)中看 public Document parse(InputSource is) throws SAXException, IOException { if (is == null) {//如果xml输入流为空,则抛出异常 throw new IllegalArgumentException( DOMMessageFormatter.formatMessage(DOMMessageFormatter.DOM_DOMAIN, "jaxp-null-input-source", null)); } if (fSchemaValidator != null) { /** * 这个对象是在DocumentBuilderImpl的构造方法中new其子类生成的,这里这样做是为了防止有人继承了DocumentBuilder抽象类 * 但是在使用的时候没有给fSchemaValidator(XMLComponent对象)赋值,还有就是其他情况发生也为空,这里具体去看 * DocumentBuilderImpl的构造方法 * 源码:(DocumentBuilderImpl类中的源码) * //属性定义中 * private final XMLComponent fSchemaValidator; * //构造方法中 * validatorComponent = new XMLSchemaValidator(); * fSchemaValidator = validatorComponent; */ if (fSchemaValidationManager != null) { //private final ValidationManager fSchemaValidationManager;这个和上面同理 fSchemaValidationManager.reset(); fUnparsedEntityHandler.reset(); } resetSchemaValidator(); } //主要在这里! //domParser = new DOMParser();这个是在(DocumentBuilderImpl类的构造方法中实现的) //DOMParser文档介绍:这是主要的Xerces DOM解析器类。它将抽象的DOMparser与文档扫描器,dtd扫描器和验证器结合使用,就像语法池一样。 //这里的parse方法主要就是解析InputSource流 domParser.parse(is); //通过刚才解析InputSource流获得的信息构建Document对象 Document doc = domParser.getDocument(); //删除对此解析器生成的最后一个DoM的所有引用。 domParser.dropDocumentReferences(); return doc; } //resetSchemaValidator();方法,重置对象--这个暂时不深入去看,对下面没多大影响 private void resetSchemaValidator() throws SAXException { try { fSchemaValidator.reset(fSchemaValidatorComponentManager); } // This should never be thrown from the schema validator. catch (XMLConfigurationException e) { throw new SAXException(e); } }- 补充部分
![image-20210314072543535]()
![image-20210314074414683]()
![image-20210314074433519]()
- 补充部分
-
NodeList sList = d.getElementsByTagName("student");这一行就好理解了通过解析节点名称获取使用这个名称节点的
官方:以给定的标签名称返回文档中对应标签名所有ELements的NodeList。
看看源码://还是一样Document对象中没有具体在其实现子类中 public NodeList getElementsByTagName(String tagname); //CoreDocumentImpl public NodeList getElementsByTagName(String tagname) { return new DeepNodeListImpl(this,tagname);//public class DeepNodeListImpl implements NodeList }o //这里直接构建一个DeepNodeListImpl返回出去就是我们获得的NodeList //到了有些人这里会比较奇怪,如果返回的是这个那怎么区分不同标签呢? //这里就需要看到下面的获取 public DeepNodeListImpl(NodeImpl rootNode, String tagName) { this.rootNode = rootNode; this.tagName = tagName; nodes = new ArrayList<>(); } //item获取第index个Node public Node item(int index) { Node thisNode; // 如果节点树发生了改变则重新生成一个nodes if (rootNode.changes() != changes) { nodes = new ArrayList<>(); changes = rootNode.changes();//获取最新节点数 } final int currentSize = nodes.size(); if (index < currentSize) {//如果之前已经找到过这个节点了,就直接从nodes里面拿就好了 return nodes.get(index); } else {//如果还没找过这个节点 // 在我们上次最后寻找的位置寻找(可能是最开始)currentSize:nodes的size if (currentSize == 0) { thisNode = rootNode;//如果是最开始,直接获取第一个节点就好了 } else { thisNode = (NodeImpl) (nodes.get(currentSize - 1));//如果不是则获取nodes中最后一个节点--便于寻找 } // 通过nextMatchingElementAfter方法找到节点,并且添加到nodes中去 while (thisNode != null && index >= nodes.size()) { thisNode = nextMatchingElementAfter(thisNode); if (thisNode != null) { nodes.add(thisNode); } } // 找到了就传出去,没有就传null出去; return thisNode; } } // item(int):Node //通过传入的节点树(树的第一个节点)遍历搜索标签名符合tagName的节点 //注意注意这里还是刚才那个命题,获取对应节点名的节点-下面这个方法就可以看到我们传入的节点名有什么作用了 protected Node nextMatchingElementAfter(Node current) { Node next; while (current != null) {//节点不为空 // Look down to first child. if (current.hasChildNodes()) {//hasChildNodes:查看该节点是否有子节点 current = (current.getFirstChild());//存在子节点就获取第一个子节点 } // 如果没有子节点就看向他的兄弟节点 else if (current != rootNode && null != (next = current.getNextSibling())) { //getNextSibling:该节点(兄弟节点之间)之后的节点,如果没有返回null current = next;//如果存在就遍历该兄弟节点 } //如果兄弟节点也没有了就去上一层,注意不要到了最终父节点还向上 else { next = null; for (; current != rootNode; //当我们回到起点(最终父节点)时停下来 current = current.getParentNode()) {//getParentNode:获取父节点 next = current.getNextSibling();//到了父节点后向父节点的下一个节点走去 if (next != null) {//如果父节点下一个节点不为空说明父节点还有兄弟节点则去遍历父节点的这个兄弟节点 break; } } current = next; } // 判断是否找到符合tagName的节点 // 如果为*代表全部节点 if (current != rootNode && current != null && current.getNodeType() == Node.ELEMENT_NODE) {//判断节点是否不为最终父,判断该节点是ELement节点,判断不为空 if (!enableNS) {//命名空间逻辑设置:默认为false if (tagName.equals("*") || ((ElementImpl) current).getTagName().equals(tagName)) { return current;//这里判断是否符合当前逻辑符合就直接放回 } } else {//另一种命名空间逻辑 // DOM2: Namespace logic. if (tagName.equals("*")) { if (nsName != null && nsName.equals("*")) { return current; } else { ElementImpl el = (ElementImpl) current; if ((nsName == null && el.getNamespaceURI() == null) || (nsName != null && nsName.equals(el.getNamespaceURI()))) { return current; } } } else { ElementImpl el = (ElementImpl) current; if (el.getLocalName() != null && el.getLocalName().equals(tagName)) { if (nsName != null && nsName.equals("*")) { return current; } else { if ((nsName == null && el.getNamespaceURI() == null) || (nsName != null && nsName.equals(el.getNamespaceURI()))) { return current; } } } } } } // 否则继续走树 } // 如果树遍历完毕还是没有就返回null return null; } // nextMatchingElementAfter(int):Node看完源码后会发现原来节点的获取是动态获取的,只有在需要使用的时候才获取该节点,不会一来就获取节省了初始化时的开销


基础的节点使用
这里我会重点看向节点的一些使用方法获取什么东西,当然只看常用和基础的,深入的可以自行研究
public static void nodeOperating(Node node) {
NamedNodeMap attributes = node.getAttributes();//获取节点上面的属性列表(因为有多个属性)<student rollno="493">rollno就是这个节点的属性
Node rollno = attributes.getNamedItem("rollno");//通过属性名获取该属性节点
NodeList childNodes = node.getChildNodes();//获取节点的孩子节点列表
for (int j = 0; j <childNodes.getLength() ; j++) {//循环遍历该列表
Node item = childNodes.item(j);//这里item上节说过了
if (item.getNodeType()==Node.ELEMENT_NODE) {//ELEMENT_NODE代表该节点是Element节点
System.out.print(item.getNodeName() + ":");//获取该节点的名称
System.out.println(item.getFirstChild().getNodeValue());//获取该节点中的值
}
}
}
-
这里主要就是两个一个获取孩子节点列表,一个获取节点的属性列表
-
node.getAttributes();首先是这个方法//这个方法的实现子类在ElementImpl--注意的是其对象是这个类的子类DeferredElementImpl //NodeList sList = d.getElementsByTagName("student");这个列表里面的对象实例是DeferredElementImpl //所以我这里探究getAttributes方法以DeferredElementImpl对象为实例进行研究 public NamedNodeMap getAttributes() { if (needsSyncData()) {//标志设置者和获取者 //同步快速节点的数据(名称和值)。 synchronizeData();//这个在DeferredElementImpl中被重写了 } if (attributes == null) { //重点看这里生成的这个AttributeMap对象 attributes = new AttributeMap(this, null);//生成一个AttributeMap对象 } return attributes; } // getAttributes():NamedNodeMap //DeferredElementImpl对象重写了父类的这个方法 //同步快速节点的数据(名称和值)。 protected final void synchronizeData() { // 以后无需同步 needsSyncData(false);//这次同步后就设置needsSyncData为false后续就不需要再同步了 // fluff data DeferredDocumentImpl ownerDocument = (DeferredDocumentImpl)this.ownerDocument; // we don't want to generate any event for this so turn them off boolean orig = ownerDocument.mutationEvents; ownerDocument.mutationEvents = false; name = ownerDocument.getNodeName(fNodeIndex); // attributes setupDefaultAttributes(); int index = ownerDocument.getNodeExtra(fNodeIndex); if (index != -1) { NamedNodeMap attrs = getAttributes(); do { NodeImpl attr = (NodeImpl)ownerDocument.getNodeObject(index); attrs.setNamedItem(attr); index = ownerDocument.getPrevSibling(index); } while (index != -1); } // set mutation events flag back to its original value ownerDocument.mutationEvents = orig; } // synchronizeData() //生成一个节点图 protected AttributeMap(ElementImpl ownerNode, NamedNodeMapImpl defaults) { super(ownerNode); if (defaults != null) { // 使用默认值初始化图 cloneContent(defaults); if (nodes != null) { hasDefaults(true); } } } //这个是上面的super(ownerNode);,类为NamedNodeMapImpl protected NamedNodeMapImpl(NodeImpl ownerNode) { this.ownerNode = ownerNode; }-
通过上面的源码可以发现并没有初始化map可以猜测应该和之前的节点列表一样是获取时动态更新所以来看一下它的获取方法Node rollno = attributes.getNamedItem("rollno");//通过属性名获取该属性节点直接看源码--注意的是之前看到它生成的是一个
AttributeMap所以我这里研究的实例类也是它//这个方法在AttributeMap的父类NamedNodeMapImpl实现了,且没有重写 //通过名称检索节点。 public Node getNamedItem(String name) { int i = findNamePoint(name,0); return (i < 0) ? null : (nodes.get(i));//小于0说明没找到返回null } // getNamedItem(String):Node //这个方法也在AttributeMap的父类NamedNodeMapImpl实现了,且没有重写 //找到这个名称的节点的位置 protected int findNamePoint(String name, int start) { // 搜索节点位置 int i = 0; if (nodes != null) { int first = start; int last = nodes.size() - 1; while (first <= last) { i = (first + last) / 2; int test = name.compareTo(((nodes.get(i))).getNodeName()); if (test == 0) { return i; // 找到节点位置 } else if (test < 0) { last = i - 1; } else { first = i + 1; } } if (first > i) { i = first; } } return -1 - i; // not-found has to be encoded. } // findNamePoint(String):int- 然后发现其实并没有再生成一个列表,而且在Node的nodes中进行寻找,找到后将该节点位置返回;
-
-
接下来
node.getChildNodes();获取子节点列表
上源码://先把继承顺序放出来免得等下搞错 //DeferredElementImpl extends ElementImpl // extends ParentNode extends ChildNode extends NodeImpl implements Node, NodeList //关于getChildNodes这个方法我们从子类向父类去找,根据方法栈调用规则最先调用的子类的方法就是使用该方法(多态) /** 获取一个枚举该节点所有子节点的NodeList。如果没有,则返回(最初)空的NodeList。 NodeList是“活动的”;随着添加/删除子级,NodeList将立即反映这些更改。 另外,NodeList指的是实际节点,因此通过DOM树对那些节点所做的更改将反映在NodeList中,反之亦然。 在此实现中,节点实现NodeList接口并提供其自己的getChildNodes()支持。其他DOM可能会以不同的方式解决此问题。 */ //ParentNode public NodeList getChildNodes() { if (needsSyncChildren()) {//获取状态,判断是否进行下面的数据同步 synchronizeChildren();// } return this;//这里放回this是因为NodeImpl implements Node, NodeList, //所以this也是有NodeList的方法的 //然后使用NodeList中item方法获取对应对象--item方法上面讲过了 } // getChildNodes():NodeList /** 使节点的孩子与内部结构同步。 立刻将儿童弄乱导致了使两个结构保持同步的大量工作。当编辑树时,问题变得更糟,这使它变得容易得多。 */ //synchronizeChildren方法:调用类DeferredElementImpl //主要是进行数据同步所以这样里就不写了由此可以看出子节点列表其实也是Node本身进行维护的;
-
-
接下来就是是看其中的节点元素获取方法了-其中获取属性列表和子节点列表讲过就不写了
-
就只看
item.getNodeName()方法,其他的都大同小异,我会贴出对应的方法列表--其实可以直接到jdk.API进行查询//ElementImpl类实现了此方法(具体继承规则看上面) public String getNodeName() { if (needsSyncData()) {//判断状态是否进行数据同步 synchronizeData(); } return name;//直接返回此节点的name属性 }
-
-
对应方法
API列表-
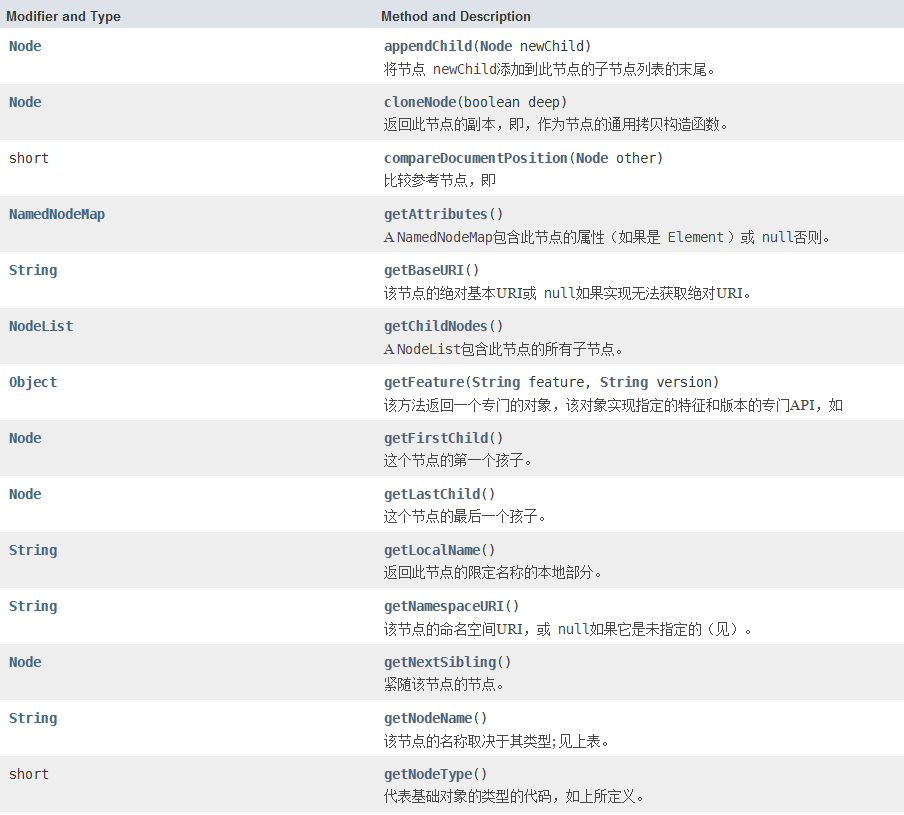
Node接口的![image-20210314105435182]()
![image-20210314105500628]()
![image-20210314105512907]()
-
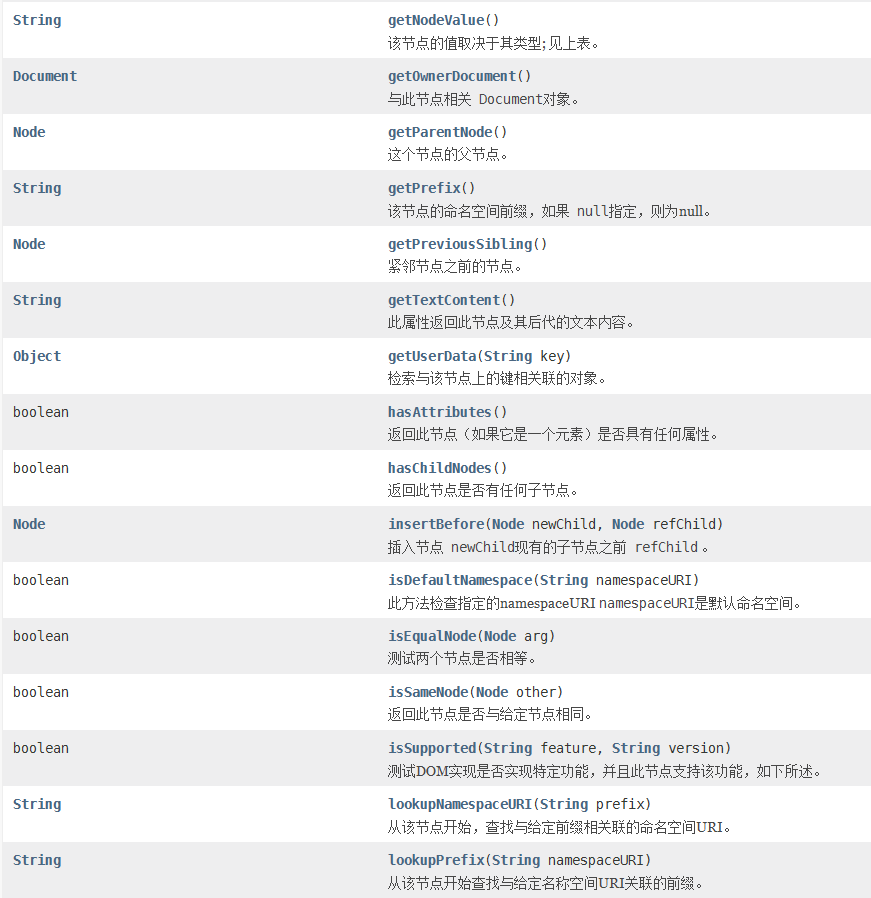
NodeList接口的
![image-20210314105700995]()
-


常用方法
package org.example;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
public class XMLStudyDemo {
public static void main(String[] args) {
Node node = initXML();
nodeOperating1(node);
nodeOperating2(node);
}
//一、初始化XML获取节点对象
public static Node initXML() {
//1.创建DocumentBuilderFactory对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
System.out.println(factory.getClass());//class com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl
try {
//2.创建DocumentBuilder对象
DocumentBuilder builder = factory.newDocumentBuilder();
System.out.println(builder.getClass());//class com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderImpl
//3.根据文件创建文档对象
Document d = builder.parse(Test.class.getClassLoader().getResourceAsStream("demo.xml"));
System.out.println(d.getClass());//class com.sun.org.apache.xerces.internal.dom.DeferredDocumentImpl
//4.根据节点标签名获取该标签名对应的所以节点的集合列表
NodeList sList = d.getElementsByTagName("student");
System.out.println(sList.getClass());//class com.sun.org.apache.xerces.internal.dom.DeepNodeListImpl
//5.根据节点列表获取此节点列表的第0个节点
Node item = sList.item(0);
System.out.println(item.getClass());//class com.sun.org.apache.xerces.internal.dom.DeferredElementImpl
System.out.println("==============");
return item;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
//二、节点的对应操作(1)
public static void nodeOperating1(Node node) {
//获取节点属性列表--通过该列表可以获取节点的属性(以节点对象显示)
NamedNodeMap attributes = node.getAttributes();
Node item = attributes.item(0);
System.out.println("item = " + item);
//获取节点的子节点列表
NodeList childNodes = node.getChildNodes();
childNodes.item(0);
System.out.println("childNodes = " + childNodes);
System.out.println("==============");
}
//三、节点的对应操作(2)
public static void nodeOperating2(Node node) {
//获取节点的标签名
String nodeName = node.getNodeName();
System.out.println("nodeName = " + nodeName);
//获取节点的值--注意这里为啥我要写两个呢?
// 因为文本在xml里也算一个节点而且不用写标签包住所以要先获取文本节点后才能获取该节点的文本值
String nodeValue = node.getNodeValue();
System.out.println("nodeValue = " + nodeValue);
String nodeValue1 = node.getFirstChild().getNodeValue();
System.out.println("nodeValue1 = " + nodeValue1);
System.out.println("--------这里做一个文本的小案例--因为student节点本身没文本所以我用它的子节点");
//值得注意的是node的第一个节点(item-0)不是我们想象中的<firstname>cxx1</firstname>而是null
System.out.println(node.getChildNodes().item(1).getFirstChild().getNodeValue());
System.out.println("--------end");
//获取此节点及其后代的文本内容。
String textContent = node.getTextContent();
System.out.println("textContent = " + textContent);
System.out.println("==============");
}
}
//XML文件的内容
/*
<?xml version="1.0" encoding="utf-8" ?>
<class>
<student>
<firstname>cxx1</firstname>
<lastname>Bob1</lastname>
<nickname>stars1</nickname>
<marks>85</marks>
</student>
<student rollno="493">
<firstname>cxx2</firstname>
<lastname>Bob2</lastname>
<nickname>stars2</nickname>
<marks>85</marks>
</student>
<student rollno="593">
<firstname>cxx3</firstname>
<lastname>Bob3</lastname>
<nickname>stars3</nickname>
<marks>85</marks>
</student>
</class>
*/
问题
第一个就碰到文件位置设置
因为在web工程中mybiatis的主配置文件是放在src下的
但是在maven工程中是放在resource文件夹下记得创建文件夹后右键将文件夹设置为Source文件夹
第二个是如何将获取XML中Node节点上的属性
Node node = list.item(i);
System.out.println("_____________________"+"".trim());
NamedNodeMap attributes = node.getAttributes();
Node rollno = attributes.getNamedItem("rollno");
System.out.println(rollno);
使用
node.getAttributes();获取节点的属性列表方法attributes.getNamedItem("rollno");根据属性名获取对应属性的节点对象


 浙公网安备 33010602011771号
浙公网安备 33010602011771号