Google Protocol Buffers 入门
个人小站,正在持续整理中,欢迎访问:http://shitouer.cn
小站博文地址:Google Protocol Buffers 入门
推荐阅读顺序,希望给你带来收获~
《Google Protocol Buffers 编码(Encoding)》
1. 前言
这篇入门教程是基于Java语言的,这篇文章我们将会:
- 创建一个.proto文件,在其内定义一些PB message
- 使用PB编译器
- 使用PB Java API 读写数据
这篇文章仅是入门手册,如果想深入学习及了解,可以参看: Protocol Buffer Language Guide, Java API Reference, Java Generated Code Guide, 以及Encoding Reference。
2. 为什么使用Protocol Buffers
接下来用“通讯簿”这样一个非常简单的应用来举例。该应用能够写入并读取“联系人”信息,每个联系人由name,ID,email address以及contact photo number组成。这些信息的最终存储在文件中。
如何序列化并检索这样的结构化数据呢?有以下解决方案:
- 使用Java序列化(Java Serialization)。这是最直接的解决方式,因为该方式是内置于Java语言的,但是,这种方式有许多问题(Effective Java 对此有详细介绍),而且当有其他应用程序(比如C++ 程序及Python程序书写的应用)与之共享数据的时候,这种方式就不能工作了。
- 将数据项编码成一种特殊的字符串。例如将四个整数编码成“12:3:-23:67”。这种方法简单且灵活,但是却需要编写独立的,只需要用一次的编码和解码代码,并且解析过程需要一些运行成本。这种方式对于简单的数据结构非常有效。
- 将数据序列化为XML。这种方式非常诱人,因为易于阅读(某种程度上)并且有不同语言的多种解析库。在需要与其他应用或者项目共享数据的时候,这是一种非常有效的方式。但是,XML是出了名的耗空间,在编码解码上会有很大的性能损耗。而且呢,操作XML DOM数非常的复杂,远不如操作类中的字段简单。
Protocol Buffers可以灵活,高效且自动化的解决该问题,只需要:
- 创建一个.proto 文件,描述希望数据存储结构
- 使用PB compiler 创建一个类,该类可以高效的,以二进制方式自动编码和解析PB数据
该生成类提供组成PB数据字段的getter和setter方法,甚至考虑了如何高效的读写PB数据。更厉害的是,PB友好的支持字段拓展,拓展后的代码,依然能够正确的读取原来格式编码的数据。
3. 定义协议格式
首先需要创建一个.proto文件。非常简单,每一个需要序列化的数据结构,编码一个PB message,然后为message中的字段指明一个名字和类型即可。该“通讯簿”的.proto 文件addressbook.proto定义如下:
package tutorial;
option java_package = "com.example.tutorial";
option java_outer_classname = "AddressBookProtos";
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}
可以看到,语法非常类似Java或者C++,接下来,我们一条一条来过一遍每句话的含义:
- .proto文件以一个package声明开始。该声明有助于避免不同项目建设的命名冲突。Java版的PB,在没有指明java_package的情况下,生成的类默认的package即为此package。这里我们生命的java_package,所以最终生成的类会位于com.example.tutorial package下。这里需要强调一下,即使指明了java_package,我们建议依旧定义.proto文件的package。
- 在package声明之后,紧接着是专门为java指定的两个选项:java_package 以及 java_outer_classname。java_package我们已经说过,不再赘述。java_outer_classname为生成类的名字,该类包含了所有在.proto中定义的类。如果该选项不显式指明的话,会按照驼峰规则,将.proto文件的名字作为该类名。例如“addressbook.proto”将会是“Addressbook”,“address_book.proto”即为“AddressBook”
- java指定选项后边,即为message定义。每个message是一个包含了一系列指明了类型的字段的集合。这里的字段类型包含大多数的标准简单数据类型,包括bool,int32,float,double以及string。Message中也可以定义嵌套的message,例如“Person” message 包含“PhoneNumber” message。也可以将已定义的message作为新的数据类型,例如上例中,PhoneNumber类型在Person内部定义,但他是phone的type。在需要一个字段包含预先定义的一个列表的时候,也可以定义枚举类型,例如“PhoneType”。
- 我们注意到, 每一个message中的字段,都有“=1”,“=2”这样的标记,这可不是初始化赋值,该值是message中,该字段的唯一标示符,在二进制编码时候会用到。数字1~15的表示需求少于一个字节,所以在编码的时候,有这样一个优化,你可以用1~15标记最常使用或者重复字段元素(repeated elements)。用16或者更大的数字来标记不太常用的可选元素。再重复字段中,每一个元素都需重复编码标签数字,所以,该优化对重复字段最佳(repeat fileds)。
message的没一个字段,都要用如下的三个修饰符(modifier)来声明:
- required:必须赋值,不能为空,否则该条message会被认为是“uninitialized”。build一个“uninitialized” message会抛出一个RuntimeException异常,解析一条“uninitialized” message会抛出一条IOException异常。除此之外,“required”字段跟“optional”字段并无差别。
- optional:字段可以赋值,也可以不赋值。假如没有赋值的话,会被赋上默认值。对于简单类型,默认值可以自己设定,例如上例的PhoneNumber中的PhoneType字段。如果没有自行设定,会被赋上一个系统默认值,数字类型会被赋为0,String类型会被赋为空字符串,bool类型会被赋为false。对于内置的message,默认值为该message的默认实例或者原型,即其内所有字段均为设置。当获取没有显式设置值的optional字段的值时,就会返回该字段的默认值。
- repeated:该字段可以重复任意次数,包括0次。重复数据的顺序将会保存在protocol buffer中,将这个字段想象成一个可以自动设置size的数组就可以了。
Notice:应该格外小心定义Required字段。当因为某原因要把Required字段改为Optional字段是,会有问题,老版本读取器会认为消息中没有该字段不完整,可能会拒绝或者丢弃该字段(Google文档是这么说的,但是我试了一下,将required的改为optional的,再用原来required时候的解析代码去读,如果字段赋值的话,并不会出错,但是如果字段未赋值,会报这样错误:Exception in thread "main" com.google.protobuf.InvalidProtocolBufferException: Message missing required fields:fieldname)。在设计时,尽量将这种验证放在应用程序端的完成。Google的一些工程师对此也很困惑,他们觉得,required类型坏处大于好处,应该尽量仅适用optional或者repeated的。但也并不是所有的人都这么想。
如果想深入学习.proto文件书写,可以参考Protocol Buffer Language Guide。但是不要妄想会有类似于类继承这样的机制,Protocol Buffers不做这个...
4. 编译Protocol Buffers
定义好.proto文件后,接下来,就是使用该文件,运行PB的编译器protoc,编译.proto文件,生成相关类,可以使用这些类读写“通讯簿”没得message。接下来我们要做:
- 如果你还没有安装PB编译器,到这里现在安装:download the package
- 安装后,运行protoc,结束后会发现在项目com.example.tutorial package下,生成了AddressBookProtos.java文件:
protoc -I=$SRC_DIR --java_out=$DST_DIR $SRC_DIR/addressbook.proto #for example protoc -I=G:\workspace\protobuf\message --java_out=G:\workspace\protobuf\src\main\java G:\workspace\protobuf\messages\addressbook.proto
- -I:指明应用程序的源码位置,假如不赋值,则有当前路径(说实话,该处我是直译了,并不明白是什么意思。我做了尝试,该值不能为空,如果为空,则提示赋了一个空文件夹,如果是当前路径,请用.代替,我用.代替,又提示不对。但是可以是任何一个路径,都运行正确,只要不为空);
- --java_out:指明目的路径,即生成代码输出路径。因为我们这里是基于java来说的,所以这里是--java_out,相对其他语言,设置为相对语言即可
- 最后一个参数即.proto文件
Notice:此处运行完毕后,查看生成的代码,很有可能会出现一些类没有定义等错误,例如:com.google cannot be resolved to a type等。这是因为项目中缺少protocol buffers的相应library。在Protocol Buffers的源码包里,你会发现java/src/main/java,将这下边的文件拷贝到你的项目,大概可以解决问题。我只能说大概,因为当时我在弄得时候,也是刚学,各种出错,比较恶心。有一个简单的方法,呵呵,对于懒汉来说。创建一个maven的java项目,在pom.xml中,添加Protocol Buffers的依赖即可解决所有问题~在pom.xml中添加如下依赖(注意版本):
<dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>2.5.0</version> </dependency>
5. Protocol Buffer Java API
5.1 产生的类及方法
接下来看一下PB编译器创建了那些类以及方法。首先会发现一个.java文件,其内部定义了一个AddressBookProtos类,即我们在addressbook.proto文件java_outer_classname 指定的。该类内部有一系列内部类,对应分别是我们在addressbook.proto中定义的message。每个类内部都有相应的Builder类,我们可以用它创建类的实例。生成的类及类内部的Builder类,均自动生成了获取message中字段的方法,不同的是,生成的类仅有getter方法,而生成类内部的Builder既有getter方法,又有setter方法。本例中Person类,其仅有getter方法,如图所示:
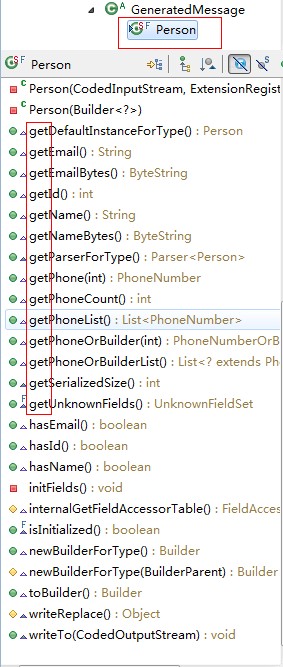
但是Person.Builder类,既有getter方法,又有setter方法,如图:
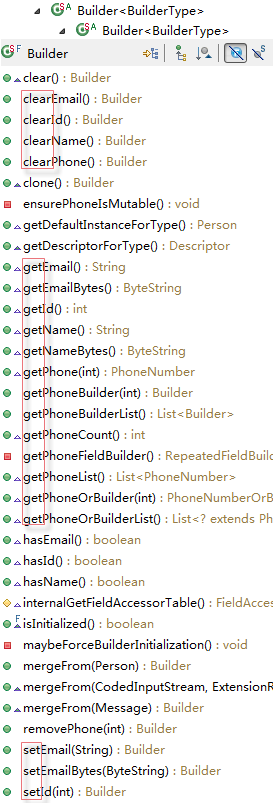
- person.builder
从上边两张图可以看到:
- 每一个字段都有JavaBean风格的getter和setter
- 对于每一个简单类型变量,还对应都有一个has这样的一个方法,如果该字段被赋值了,则返回true,否则,返回false
- 对每一个变量,都有一个clear方法,用于置空字段
对于repeated字段:
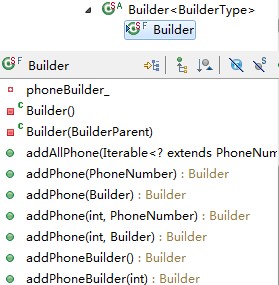
- repeated filed
从图上看:
- 从person.builder图上看出,对于repeated字段,还有一个特殊的getter,即getPhoneCount方法,及repeated字段还有一个特殊的count方法
- 其getter和setter方法根据index获取或设置一个数据项
- add()方法用于附加一个数据项
- addAll()方法来直接增加一个容器中的所有数据项
注意到一点:所有的这些方法均命名均符合驼峰规则,即使在.proto文件中是小写的。PB compiler生成的方法及字段等都是按照驼峰规则来产生,以符合基本的Java规范,当然,其他语言也尽量如此。所以,在proto文件中,命名最好使用用“_”来分割不同小写的单词。
5.2 枚举及嵌套类
从代码中可以发现,还产生了一个枚举:PhoneType,该枚举位于Person类内部:
public enum PhoneType
implements com.google.protobuf.ProtocolMessageEnum {
/**
* <code>MOBILE = 0;</code>
*/
MOBILE(0, 0),
/**
* <code>HOME = 1;</code>
*/
HOME(1, 1),
/**
* <code>WORK = 2;</code>
*/
WORK(2, 2),
;
...
}
除此之外,如我们所预料,还有一个Person.PhoneNumber内部类,嵌套在Person类中,可以自行看一下生成代码,不再粘贴。
5.3 Builders vs. Messages
由PB compiler生成的消息类是不可变的。一旦一个消息对象构建出来,他就不再能够修改,就像java中的String一样。在构建一个message之前,首先要构建一个builder,然后使用builder的setter或者add()等方法为所需字段赋值,之后调用builder对象的build方法。
在使用中会发现,这些构造message对象的builder的方法,都又会返回一个新的builder,事实上,该builder跟调用这个方法的builder是同一方法。这样做的目的,仅是为了方便而已,我们可以把所有的setter写在一行内。
如下构造一个Person实例:
Person john = Person
.newBuilder()
.setId(1)
.setName("john")
.setEmail("john@youku.com")
.addPhone(
PhoneNumber
.newBuilder()
.setNumber("1861xxxxxxx")
.setType(PhoneType.WORK)
.build()
).build();
5.4 标准消息方法
每一个消息类及Builder类,基本都包含一些公用方法,用来检查和维护这个message,包括:
- isInitialized(): 检查是否所有的required字段是否被赋值
- toString(): 返回一个便于阅读的message表示(本来是二进制的,不可读),尤其在debug时候比较有用
- mergeFrom(Message other): 仅builder有此方法,将其message的内容与此message合并,覆盖简单及重复字段
- clear(): 仅builder有此方法,清空所有的字段
5.5 解析及序列化
对于每一个PB类,均提供了读写二进制数据的方法:
- byte[] toByteArray();: 序列化message并且返回一个原始字节类型的字节数组
- static Person parseFrom(byte[] data);: 将给定的字节数组解析为message
- void writeTo(OutputStream output);: 将序列化后的message写入到输出流
- static Person parseFrom(InputStream input);: 读入并且将输入流解析为一个message
这里仅列出了几个解析及序列化方法,完整列表,可以参见:Message API reference
6. 使用PB生成类写入
接下来使用这些生成的PB类,初始化一些联系人,并将其写入一个文件中。
下面的程序首先从一个文件中读取一个通讯簿(AddressBook),然后添加一个新的联系人,再将新的通讯簿写回到文件。
package com.example.tutorial;
import com.example.tutorial.AddressBookProtos.AddressBook;
import com.example.tutorial.AddressBookProtos.Person;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.InputStreamReader;
import java.io.IOException;
import java.io.PrintStream;
class AddPerson {
// This function fills in a Person message based on user input.
static Person PromptForAddress(BufferedReader stdin, PrintStream stdout)
throws IOException {
Person.Builder person = Person.newBuilder();
stdout.print("Enter person ID: ");
person.setId(Integer.valueOf(stdin.readLine()));
stdout.print("Enter name: ");
person.setName(stdin.readLine());
stdout.print("Enter email address (blank for none): ");
String email = stdin.readLine();
if (email.length() > 0) {
person.setEmail(email);
}
while (true) {
stdout.print("Enter a phone number (or leave blank to finish): ");
String number = stdin.readLine();
if (number.length() == 0) {
break;
}
Person.PhoneNumber.Builder phoneNumber = Person.PhoneNumber
.newBuilder().setNumber(number);
stdout.print("Is this a mobile, home, or work phone? ");
String type = stdin.readLine();
if (type.equals("mobile")) {
phoneNumber.setType(Person.PhoneType.MOBILE);
} else if (type.equals("home")) {
phoneNumber.setType(Person.PhoneType.HOME);
} else if (type.equals("work")) {
phoneNumber.setType(Person.PhoneType.WORK);
} else {
stdout.println("Unknown phone type. Using default.");
}
person.addPhone(phoneNumber);
}
return person.build();
}
// Main function: Reads the entire address book from a file,
// adds one person based on user input, then writes it back out to the same
// file.
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.err.println("Usage: AddPerson ADDRESS_BOOK_FILE");
System.exit(-1);
}
AddressBook.Builder addressBook = AddressBook.newBuilder();
// Read the existing address book.
try {
addressBook.mergeFrom(new FileInputStream(args[0]));
} catch (FileNotFoundException e) {
System.out.println(args[0]
+ ": File not found. Creating a new file.");
}
// Add an address.
addressBook.addPerson(PromptForAddress(new BufferedReader(
new InputStreamReader(System.in)), System.out));
// Write the new address book back to disk.
FileOutputStream output = new FileOutputStream(args[0]);
addressBook.build().writeTo(output);
output.close();
}
}
7. 使用PB生成类读取
运行第六部分程序,写入几个联系人到文件中,接下来,我们就要读取联系人。程序入下:
package com.example.tutorial;
import java.io.FileInputStream;
import com.example.tutorial.AddressBookProtos.AddressBook;
import com.example.tutorial.AddressBookProtos.Person;
class ListPeople {
// Iterates though all people in the AddressBook and prints info about them.
static void Print(AddressBook addressBook) {
for (Person person: addressBook.getPersonList()) {
System.out.println("Person ID: " + person.getId());
System.out.println(" Name: " + person.getName());
if (person.hasEmail()) {
System.out.println(" E-mail address: " + person.getEmail());
}
for (Person.PhoneNumber phoneNumber : person.getPhoneList()) {
switch (phoneNumber.getType()) {
case MOBILE:
System.out.print(" Mobile phone #: ");
break;
case HOME:
System.out.print(" Home phone #: ");
break;
case WORK:
System.out.print(" Work phone #: ");
break;
}
System.out.println(phoneNumber.getNumber());
}
}
}
// Main function: Reads the entire address book from a file and prints all
// the information inside.
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.err.println("Usage: ListPeople ADDRESS_BOOK_FILE");
System.exit(-1);
}
// Read the existing address book.
AddressBook addressBook =
AddressBook.parseFrom(new FileInputStream(args[0]));
Print(addressBook);
}
}
至此我们已经可以使用生成类写入和读取PB message。
8. 拓展PB
当产品发布后,迟早有一天我们需要改善我们的PB定义。如果要做到新的PB能够向后兼容,同时老的PB又能够向前兼容,我们必须遵守如下规则:
- 千万不要修改现有字段后边的数值标签
- 千万不要增加或者删除required字段
- 可以删除optional或者repeated字段
- 可以添加新的optional或者repeated字段,但是必须使用新的数字标签(该数字标签必须从未在该PB中使用过,包括已经删除字段的数字标签)
如果违反了这些规则,会有一些相应的异常,可参见some exceptions,但是这些异常,很少很少会被用到。
遵守这些规则,老的代码可以正确的读取新的message,但是会忽略新的字段;对于删掉的optional的字段,老代码会使用他们的默认值;对于删除的repeated字段,则把他们置为空。
新的代码也将能够透明的读取老的messages。但是必须注意,新的optional字段在老的message中是不存在的,必须显式的使用has_方法来判断其是否设置了,或者在.proto 文件中以[default = value]形式提供默认值。如果没有指定默认值的话,会按照类型默认值赋值。对于string类型,默认值是空字符串。对于bool来说,默认值是false。对于数字类型,默认值是0。
9. 高级用法
Protocol Buffers的应用远远不止简单的存取以及序列化。如果想了解更多用法,可以去研究Java API reference。
Protocol Message Class提供了一个重要特性:反射。不需要再写任何特殊的message类型就可以遍历一条message的所有字段以及操作字段的值。反射的一个非常重要的应用是可以将PBmessage与其他的编码语言进行转化,例如与XML或者JSON之间。
反射另外一个更加高级的应用应该是两个同一类型message的之间的不同,或者开发一种可以成为“Protocol Buffers 正则表达式”的应用,使用它,可以编写符合一定消息内容的表达式。
除此之外,开动脑筋,你会发现,Protocol Buffers能解决远远超过你刚开始对他的期待。
译自:https://developers.google.com/protocol-buffers/docs/javatutorial
说实话,翻译下来整个文章非常辛苦,而且都要敲代码去亲自试验能否通过,所以如果您想转载,非常欢迎,但请注明出处,也算是对俺辛苦的尊重~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号