深入了解数据库事务隔离级别及读现象
在处理数据库事务时,我们必须做的关键一件事就是为应用程序选择适当的隔离级别。尽管有一个明确定义的标准,但每个数据库引擎可能会选择以不同的方式实现它,因此在每个隔离级别上的行为可能会有所不同。
今天,我们将通过运行一些具体的SQL查询来深入探讨MySQL和Postgres中的每个隔离级别是如何工作的。我们还将学习每个隔离级别如何防止一些读现象,例如脏读,不可重复读、幻读和串行化异常。
有关事务隔离级别的官方文档:
一、数据库事务
在深入了解事务隔离级别之前,先了解一下什么是数据库事务?
事务是一个不可分割,可以提交或回滚的工作单元。当事务对数据库进行多次更改操作时,这些更改操作要么在提交事务后全部成功,要么在回滚事务时撤销所有的更改。
事务的四个特性(ACID):
原子性(Atomicity):事务是最小的执行单元,不允许被分割,事务中的所有的操作要么全部成功,要么全部失败。一致性(Consistency):执行事务前后,数据保持一致。隔离性(Isolation):一个事务不能被其他事务干扰,它们之间是互相独立的。持久性(Durability):一个事务被提交之后,它对数据库中数据的改变是持久的,即使数据库发生了故障也不应该对其有任何影响。
二、事务隔离性和读现象
隔离性是数据库事务的四个属性之一,在最高隔离级别上,完美的隔离可以确保所有并发事务不会相互影响。
一个事务可以通过几种方式被与它同时运行的其他事务干扰。这种干扰我们称为读现象。
4种读现象:
如果数据库运行在事务隔离级别较低的情况下,可能会出现以下读取现象:
脏读:当事务读取其他尚未提交的并发事务写入的数据时,就会发生这种情况。 这非常糟糕,因为我们不知道其他事务是否最终会被提交或回滚。 因此,如果发生回滚,我们最终可能会使用不正确的数据。不可重复读:当事务两次读取同一记录并看到不同的值时,就会发生这种情况。因为该行在第一次读取后,就被其他事务提交修改了。幻读:同一查询在不同时间产生了不同的行集。
如果你现在还不完全了解这些读现象,请不要担心。在文章下面,我将为你一一展示。
4种隔离级别:
为了处理上面的这些读现象,美国国家标准协会或 ANSI 定义了4种标准隔离级别。
从低到高分别是:Read Uncommitted --> Read Committed --> Repeatable Read --> Serializable
读未提交(Read Uncommitted):一个事务还没提交时,它做的变更就能被别的事务看到。从而产生脏读。读已提交(Read Committed):一个事务提交之后,它做的变更才会被其他事务看到。因此,脏读不再可能发生。可重复读(Repeatable Read):一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一
致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。串行化(Serializable):顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
一个例子说明这几种隔离级别。假设数据表T中
只有一列,其中一行的值为1,下面是按照时间顺序执行两个事务的行为。
mysql> create table T(c int) engine=InnoDB;
insert into T(c) values(1);

我们来看看在不同的隔离级别下,事务A会有哪些不同的返回结果,也就是图里面V1、V2、V3的返回值分别是什么。
- 若隔离级别是“读未提交”, 则V1的值就是2。这时候事务B虽然还没有提交,但是结果已经被
A看到了。因此,V2、V3也都是2。 - 若隔离级别是“读提交”,则V1是1,V2的值是2。事务B的更新在提交后才能被A看到。所以,
V3的值也是2。 - 若隔离级别是“可重复读”,则V1、V2是1,V3是2。之所以V2还是1,遵循的就是这个要求:
事务在执行期间看到的数据前后必须是一致的。 - 若隔离级别是“串行化”,则在事务B执行“将1改成2”的时候,会被锁住。直到事务A提交后,
事务B才可以继续执行。所以从A的角度看, V1、V2值是1,V3的值是2。
三、演示(MySQL中的事务隔离级别)
准备数据:
mysql> select * from account;
+----+-------+---------+----------+
| id | owner | balance | currency |
+----+-------+---------+----------+
| 1 | one | 100 | CNY |
| 2 | two | 100 | CNY |
| 3 | three | 100 | CNY |
+----+-------+---------+----------+
3 rows in set (0.06 sec)
命令说明:
-- 获得当前会话的事务隔离级别
select @@transaction_isolation;
-- 更改当前会话的隔离级别
set session transaction isolation level 隔离级别;
Read Uncommitted(读未提交)
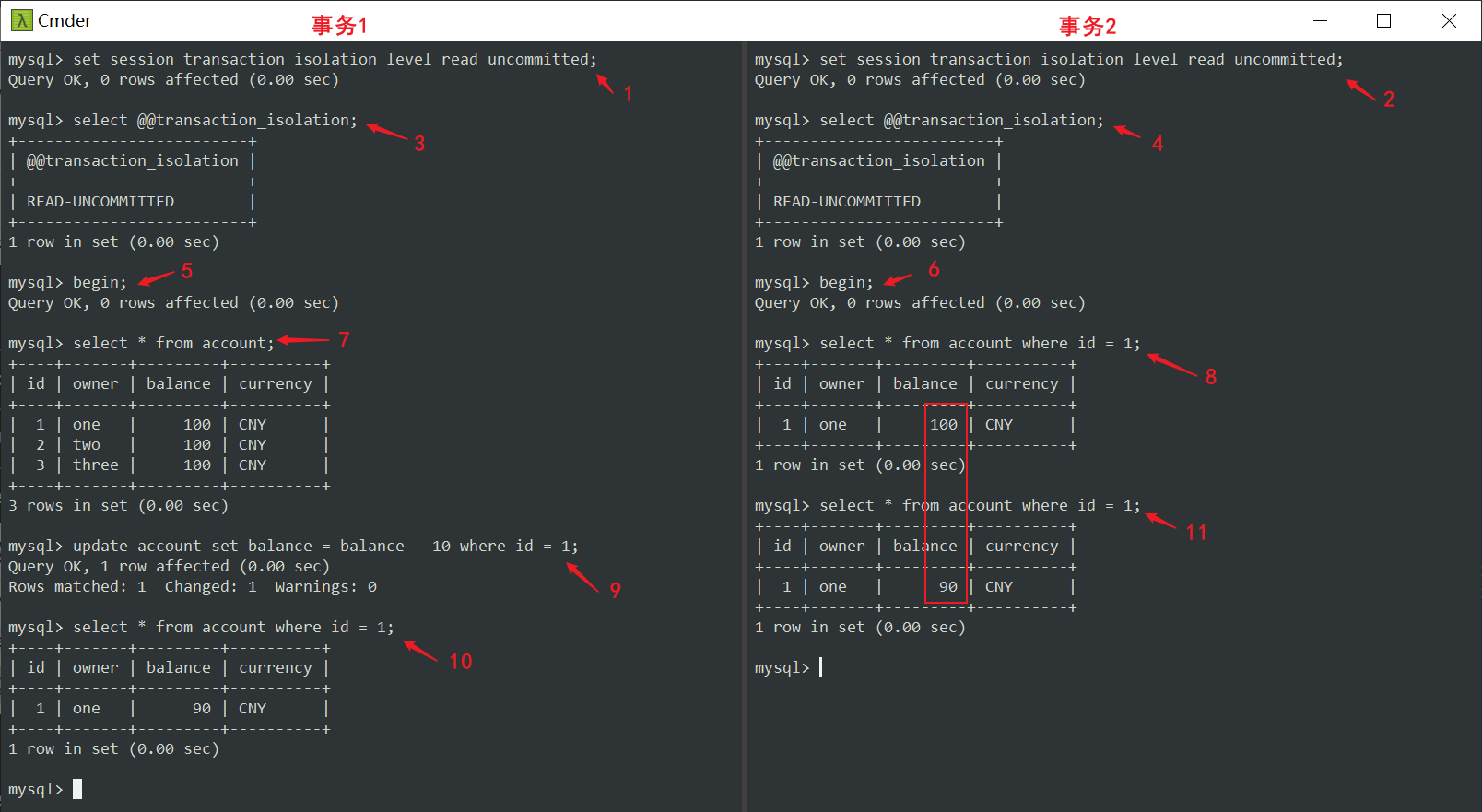
我分别设置事务1、事务2隔离级别为read uncommitted,从图中步骤3、4都可以看到,为了方便,后面的展示将不再说明。
-
分别开始事务1、事务2(步骤5、6)。
-
在事务1中,进行一个简单的查询,用来对比数据前后变化。
-
在事务2中,查看 id 为 1 的账户,金额为 100 元。
-
在事务1中,对 id 为 1 的账户余额减去 10 元,然后查询确认一下余额已经更改为 90 元。
-
但是,如果在事务2中再次运行相同的 select 语句怎么办?
你会看到余额被修改为了 90 元,而不是先前的 100 元。请注意,事务1并未提交,但事务2却看到了事务1所做的更改。
这就是
脏读现象,因为我们使用的事务隔离级别为read uncommitted(读未提交)。
OK,让我们提交这两个事务并尝试更高的隔离级别。
-- 事务1
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
-- 事务2
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
Read Committed(读已提交)
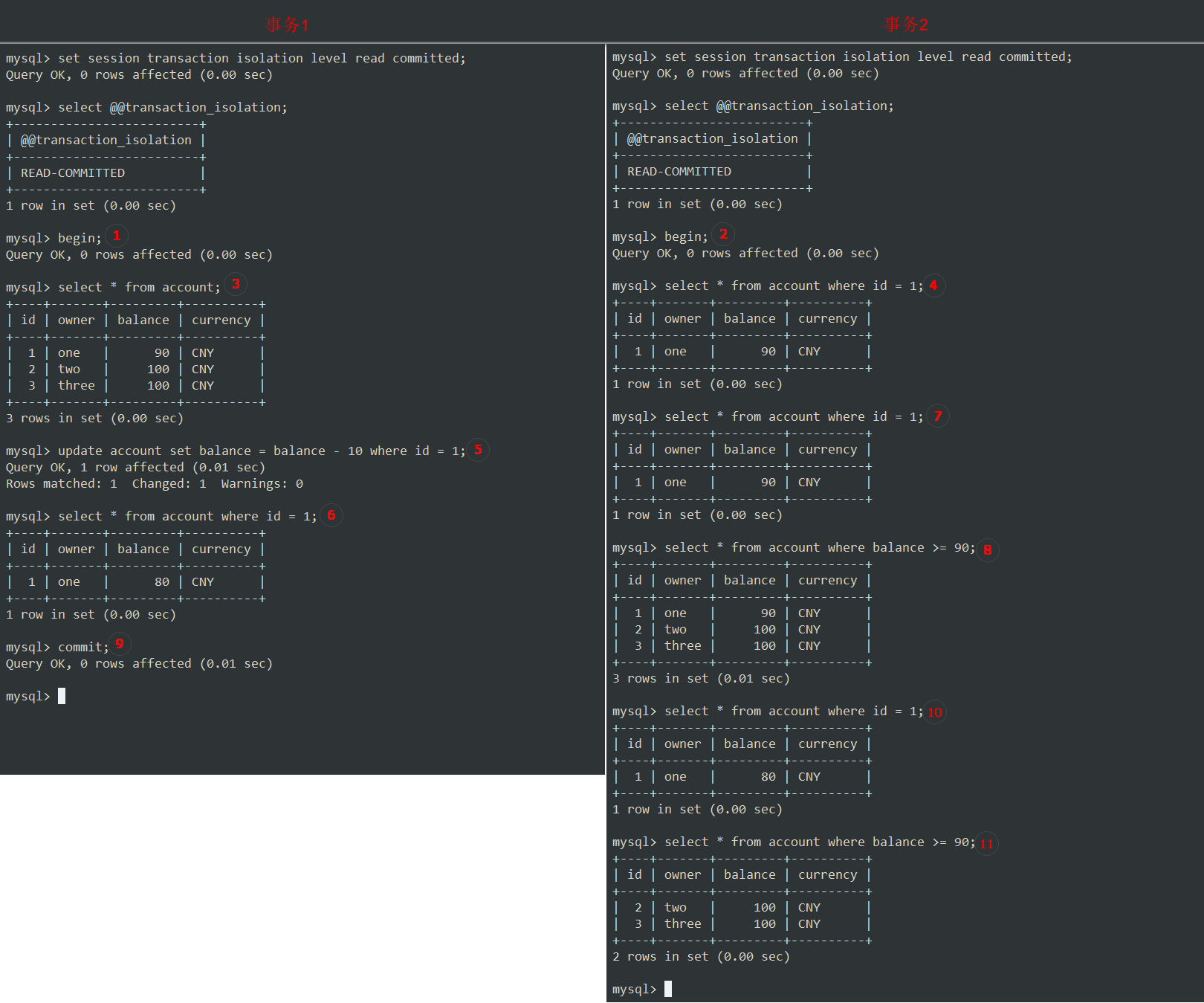
-
设置隔离级别为
read committed,并开始事务。 -
③ 在事务1中,进行一个简单的查询,用来对比数据前后变化。
-
④ 在事务2中,查看 id 为 1 的账户,金额为 90 元。
-
⑤⑥ 在事务1中,通过更新帐户余额减去 10 元,然后查询确认一下余额已经更改为 80 元,让我们看看此更改是否对事务2可见。
-
⑦ 事务2中可以看到,其余额仍然与以前一样为 90 元。
这是因为事务正在使用
read-committed隔离级别,并且由于事务1还没有提交,所以它的写入数据不能被其他事务看到。因此,读已提交 (
read-committed) 隔离级别可以防止脏读现象。那么对于不可重复读和幻读呢? -
⑧ 在事务2中,执行另一个操作,查询大于或等于 90 元的账户。
-
⑨ 事务1进行提交。
-
⑩ 现在,如果我们再次在事务2中查询帐户1余额,我们可以看到余额已更改为 80元。
所以,获得帐户1余额的同一查询返回了不同的值。 这就叫
不可重复读。 -
另外,在步骤11中,再次运行如⑧中的操作,这次只得到了2条记录,而不是以前的3条,因为事务1提交后,账户1的余额已经减少到 80 元了。
执行了相同的查询,但是返回了不同的行数。由于其他事务的提交,而导致一行数据消失,这种现象叫做
幻读。
现在,我们知道了read-committed隔离级别只能防止脏读,但是会出现不可重复读和幻读。
让我们提交事务2并尝试更高级别看看会发生什么。
Repeatable Read(可重复读)
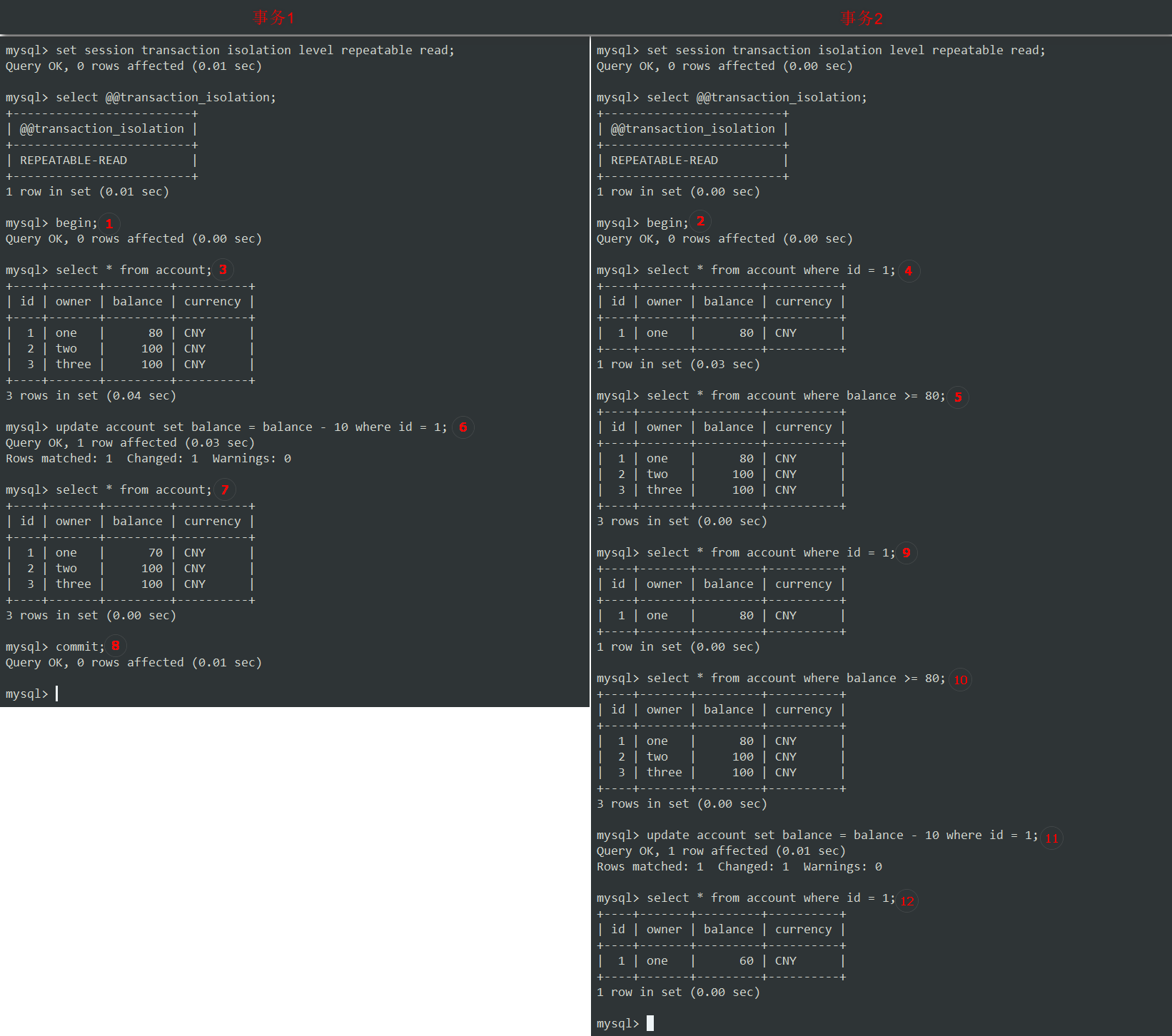
-
设置隔离级别为
Repeatable Read,并开始事务。 -
③查询事务1中的所有帐户,然后④查询事务2中ID为1的帐户,除此之外,还要⑤查询余额至少为80元的所有帐户。 这将用于验证
幻读是否仍然发生。 -
回到事务1⑥更新账户1余额减去 10 元;可以看到⑦帐户1的余额减少到了 70 元。
我们知道
脏读已在较低的隔离级别read-committed不会出现。因此,由于以下规则,我们不需要在此级别进行检查:在较低隔离级别被阻止的了读现象,不会出现在较高级别。
-
因此,让我们⑧提交事务1,然后转移到⑨事务2,看看它是否能读取到事务1所做的新更改。
可以看到,该查询返回账户1的余额与先前相同,为 80 元,尽管事务1将账户1的余额更改为 70 元,并成功提交。
这是因为
Repeatable Read(可重复读)隔离级别确保所有读查询都是可重复的,这意味着即使其他已提交的事务对数据进行了更改,它也始终返回相同的结果。 -
话说回来,让我们重新运行⑩查询余额至少 80 元的帐户。
如您所见,它仍然返回与之前相同的3条记录。 因此,在
Repeatable Read隔离级别中,也可以防止幻读现象。太好了! -
但是,我想知道如果我们还运行步骤 11,从事务1更新过的帐户1的余额中减去10,会发生什么情况? 它将余额更改为70、60还是抛出错误? 试试吧!
结果没有报错,该账户余额现在改为了 60 元,这是正确的值,因此事务1早已经提交而将余额修改为了 70 元。
但是,从事务2的角度来看,这是没有意义的,因为在上一个查询中,它获取到的是 80 元的余额,但是从帐户中减去 10 元后,现在却得到 60 元。数学运算在这里不起作用,因为此事务仍受到其他事务的并发更新的干扰。
我不知道为什么 MySQL 会选择以这种方式实现Repeatable Read(可重复读)的隔离级别。所以,在这种情况下,为了确保事务数据的一致性,通过抛出一个错误来拒绝更改会更有意义。 稍后我们将看到,这正是Postgres在此隔离级别中处理这种类型并发更新的方式。
现在,让我们回滚事务2,并转移到最高隔离级别,看看是否可以防止这个问题。
Serializable(串行化)
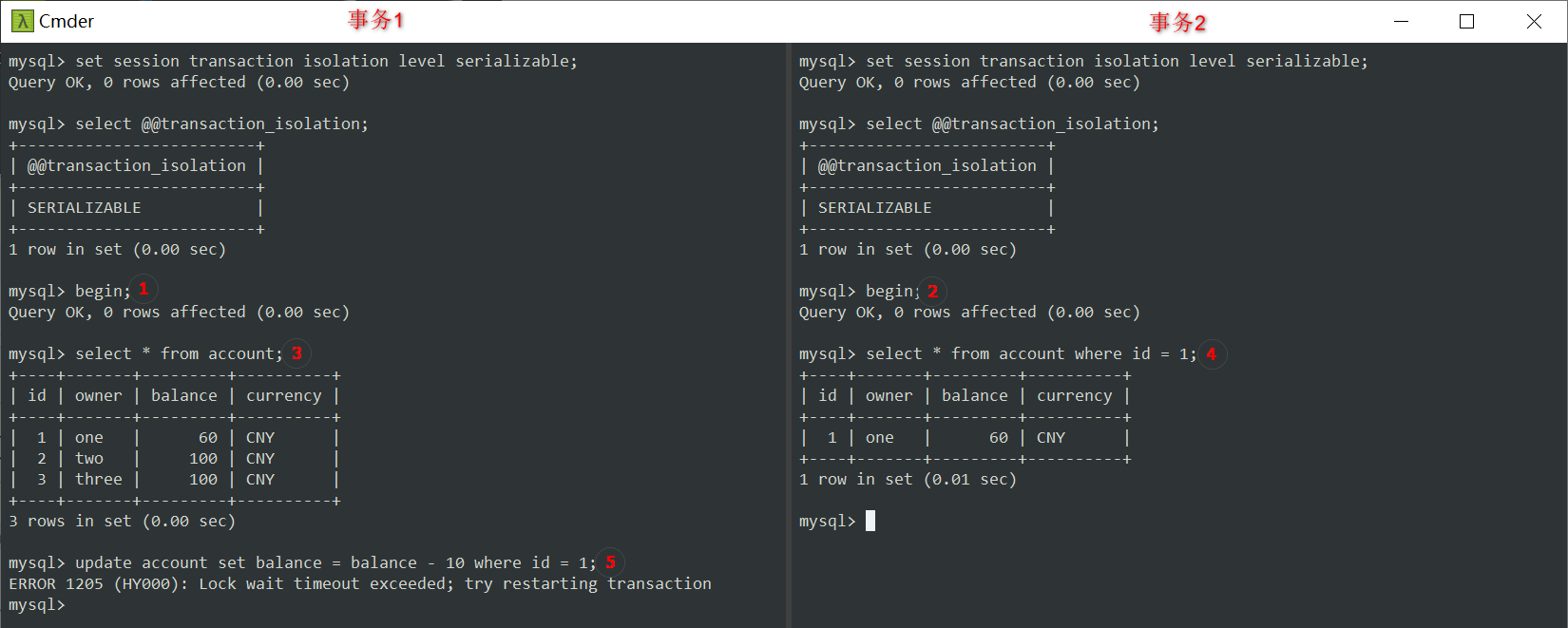
- 设置隔离级别为
Serializable,并开始事务。 - ③查询事务1中的所有帐户,然后④查询事务2中ID为1的帐户。
- 回到⑤事务1更新账户1余额减去 10 元。
有趣的是,这一次更新被阻止了。 事务2的 select 查询语句阻塞了事务1中的 update 更新语句。
原因是,在Serializable隔离级别中,MySQL隐式地将所有普通的 SELECT 查询转换为 SELECT FOR SHARE。 持有 SELECT FOR SHARE 锁的事务只允许其他事务读取行,而不能更新或删除行。
因此,有了这种锁定机制,我们以前看到的不一致数据场景不再可能出现。
但是,这个锁有一个超时持续时间。因此,如果事务2在该持续时间内未提交或回滚以释放锁,我们将看到锁等待超时错误(⑤下面显示错误)。
因此,当在应用程序中使用Serializable隔离级别时,请确保实现了一个事务重试策略,以防超时发生。
好的,将事务回滚,现在我将重新测试,看看另一种情况:
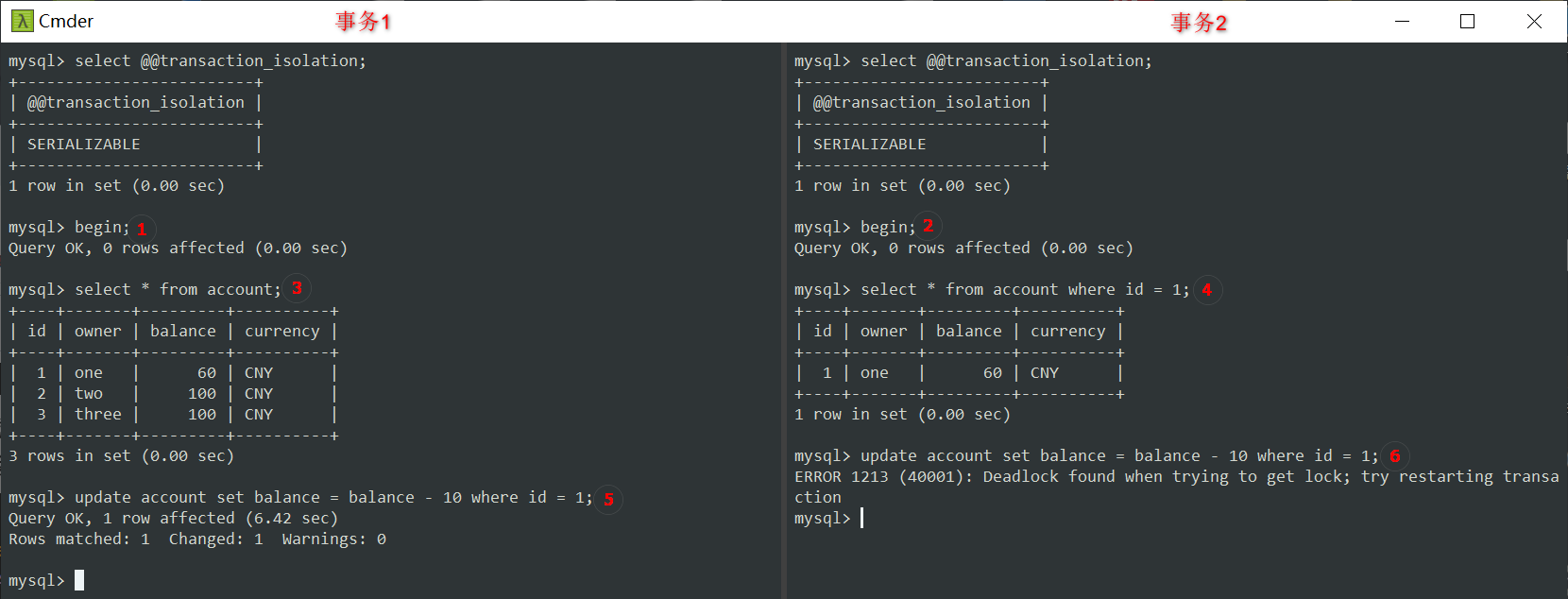
- 这一次,到步骤⑤的时候,我不会让锁等待超时发生,然后到步骤⑥也进行了跟⑤一样的操作。
- 到⑥这里,发生了死锁,因为现在事务2也需要等待事务1的 select 查询的锁。
所以请注意,除了锁等待超时之外,还需要处理可能出现的死锁情况。
现在,然我们尝试重启这两个事务:
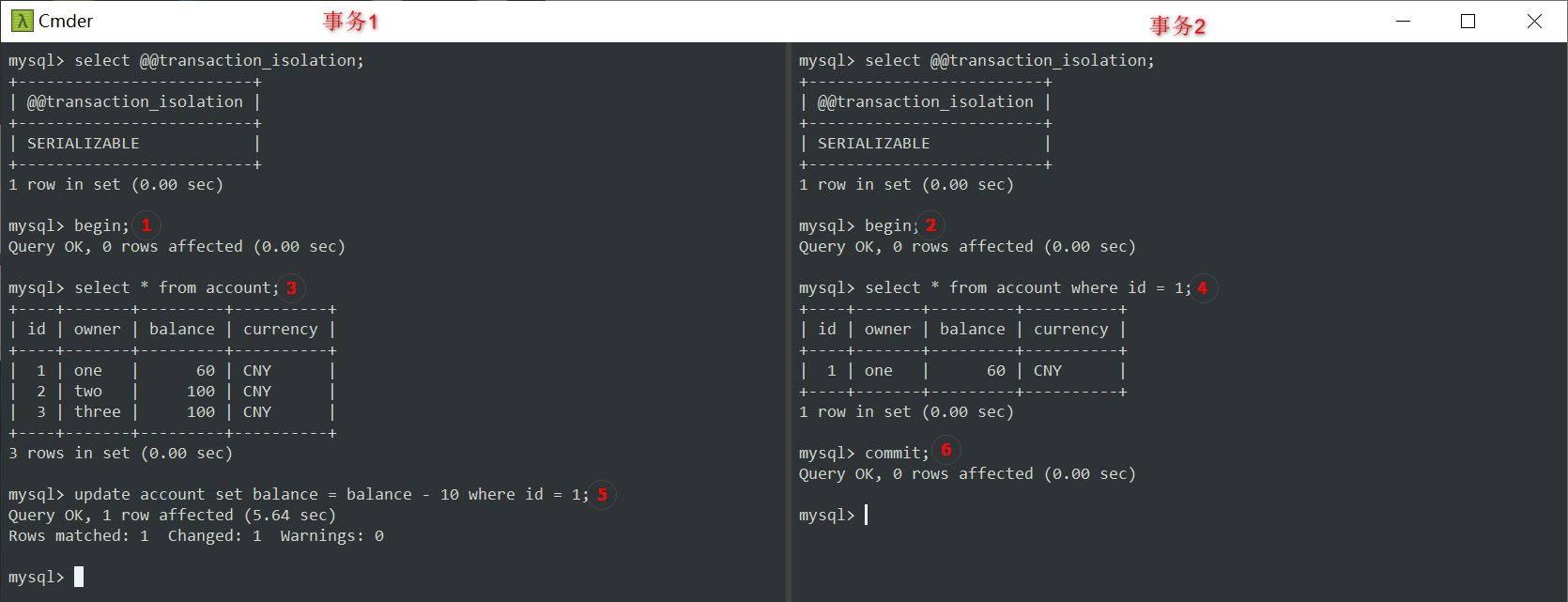
- 这次操作还是跟上面相同,到步骤⑤时,我们知道会阻塞,但如果此时步骤⑥事务2提交了,会怎样呢?
如你所见,在提交了事务2后,事务2的 select 锁立即释放,从而⑤事务1中不再阻塞,更新成功。
好的,到目前为止,我们已经在MySQL中体验了所有4种隔离级别,以及它们是如何防止某些读现象的。
现在,让我们看看它们在Postgres中的工作方式! 效果将非常相似,但也会有所不同。
四、演示(Postgres中的事务隔离级别)
在Postgres中获取当前的隔离级别:
show transaction isolation level;
默认情况下为read committed。因此,比MySQL中的默认隔离级别低1级。
更改Postgres中的隔离级别:
更改隔离级别的方式也不同。在MySQL中,我们在开始事务之前设置整个会话隔离级别。
但是在Postgres中,我们只能在事务内设置隔离级别,并且只会对那1个特定事务产生影响。
因此,开启事务,并将其隔离级别设置为read uncommitted,操作如下:
begin;
set transaction isolation level read uncommitted;
好了,知道如何开启事务和设置隔离级别,那就开始测试吧。
Read Uncommitted(读未提交)
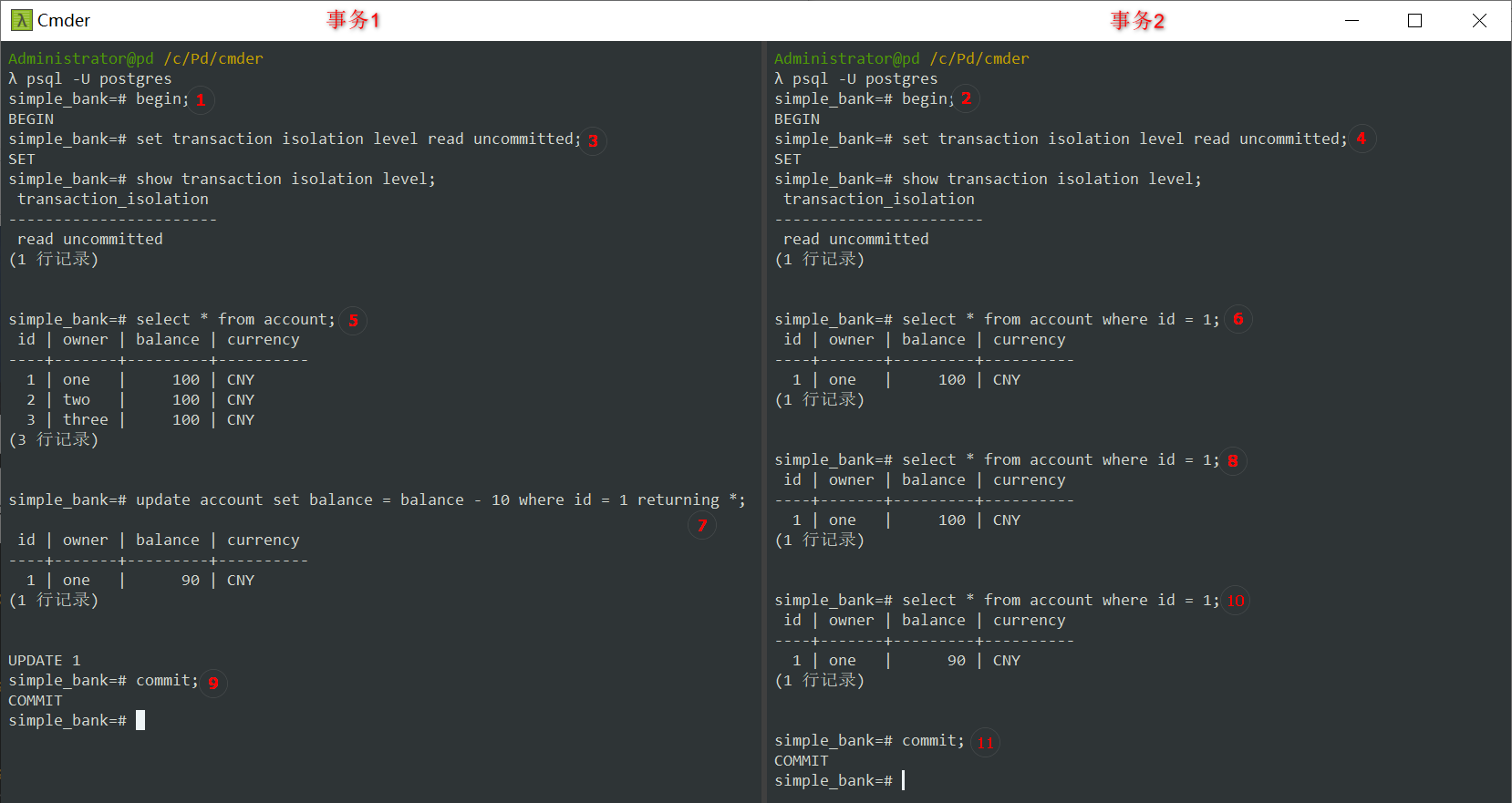
-
前面的步骤就不说,从步骤⑦开始,事务1已更改帐户1的余额为 90 元。
-
步骤⑧,事务2再次执行相同的查询。
奇怪的是,它仍然是 100 元!这是出乎意料的,因为我们使用的是
read-uncommitted隔离级别,所以像MySQL那样,事务2应该能够看到事务1的未提交数据,对吗?好吧,事实上,如果我们查看Postgres的文档,我们可以看到Postgres中
read uncommitted与read committed的行为完全相同。所以基本上,我们可以说Postgres只有3个隔离级别,最低的级别是
read committed。这是有道理的,因为通常我们不会希望在任何情况下使用read uncommitted。 -
OK,⑨让我们提交事务1。然后⑩事务2还是执行相同的查询。
现在,如预期的那样,事务2读取到的余额是 90 元。
Read Committed(读已提交)
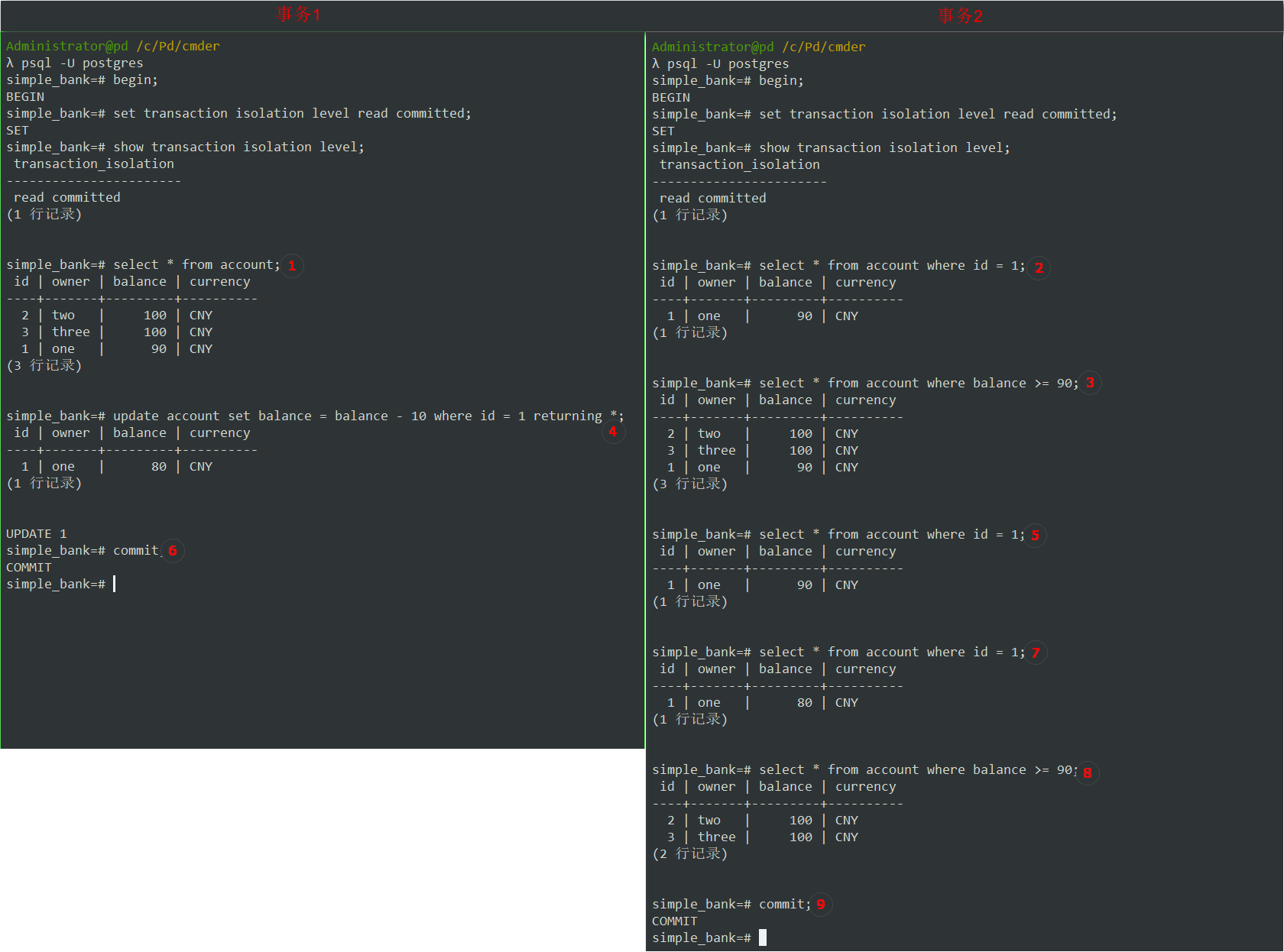
-
就像之前那样,①事务1查询所有账户。
-
②事务2查询账户1余额,除了脏读现象外,我们还希望了解它如何处理幻读,所以③查询余额大于或等于 90 元的所有帐户。可以看到,所有3条记录都满足此搜索条件。
-
④回到事务1,从帐户1的余额中扣除 10 元。
-
⑤事务2查询账户1余额,因为事务1尚未提交,因此仍为 90 元。因此
脏读在read-committed隔离级别是不可能的。 -
⑥如果提交事务1会发生什么?
-
⑦这次事务2可以看到更新后的余额 80 元。除此之外,再次查询余额大于或等于 90 元的所有帐户,这次,只看到2条记录,而不是之前的3条记录。
因为更新后的帐户1的余额不再满足搜索条件,因此已从结果集中消失。所以,
幻读已经发生在read committed隔离级别。这与MySQL中的行为相同。
Repeatable Read(可重复读)
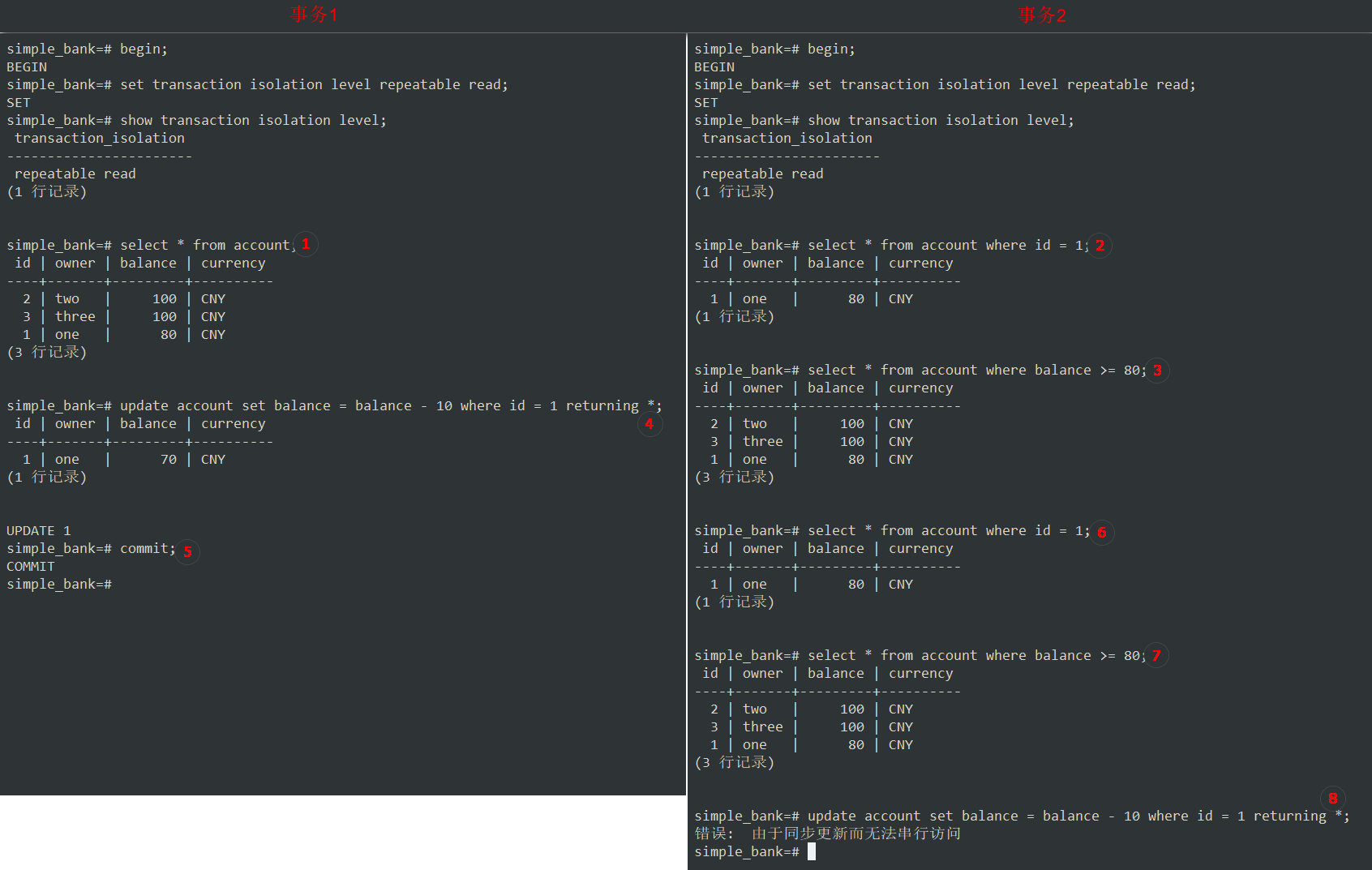
-
像上面MySQL中的那样操作,在第④⑤步,事务1已将账户1的余额更新为 70 元并已提交。看看事务2中会发生什么?
-
现在,⑥在事务2中查询帐户1余额,尽管事务1对账户1余额进行了更改并提交,但事务2仍然像以前一样是获取到的是 80 元。
这是因为使用了
repeatable read隔离级别,所以相同的 select 查询应该始终返回相同的结果。在这种情况下不会发生不可重复读现象。除此之外,再次⑦查询余额大于或等于 80 元的所有帐户。仍然获得与之前相同的3条记录。因此
幻读在此repeatable read隔离级别也被阻止了。 -
现在,尝试⑧更新帐户余额以查看其行为。
在MySQL的
repeatable read隔离级别中,可以知道它允许将余额更新为 60 元。但是在Postgres中,却遇到了一个错误:错误: 由于同步更新而无法串行访问
我认为抛出这样的错误比允许修改余额要好得多,因为它避免了一种令人困惑的状态,不像MySQL中那样,事务从80中减去10产生了60。
Postgres中的串行化异常
到目前为止,我们已经遇到了3种现象:脏读,不可重复读和幻读。 但是我们还没有遇到串行化异常。 所以这次,让我们看看它是怎么样的。
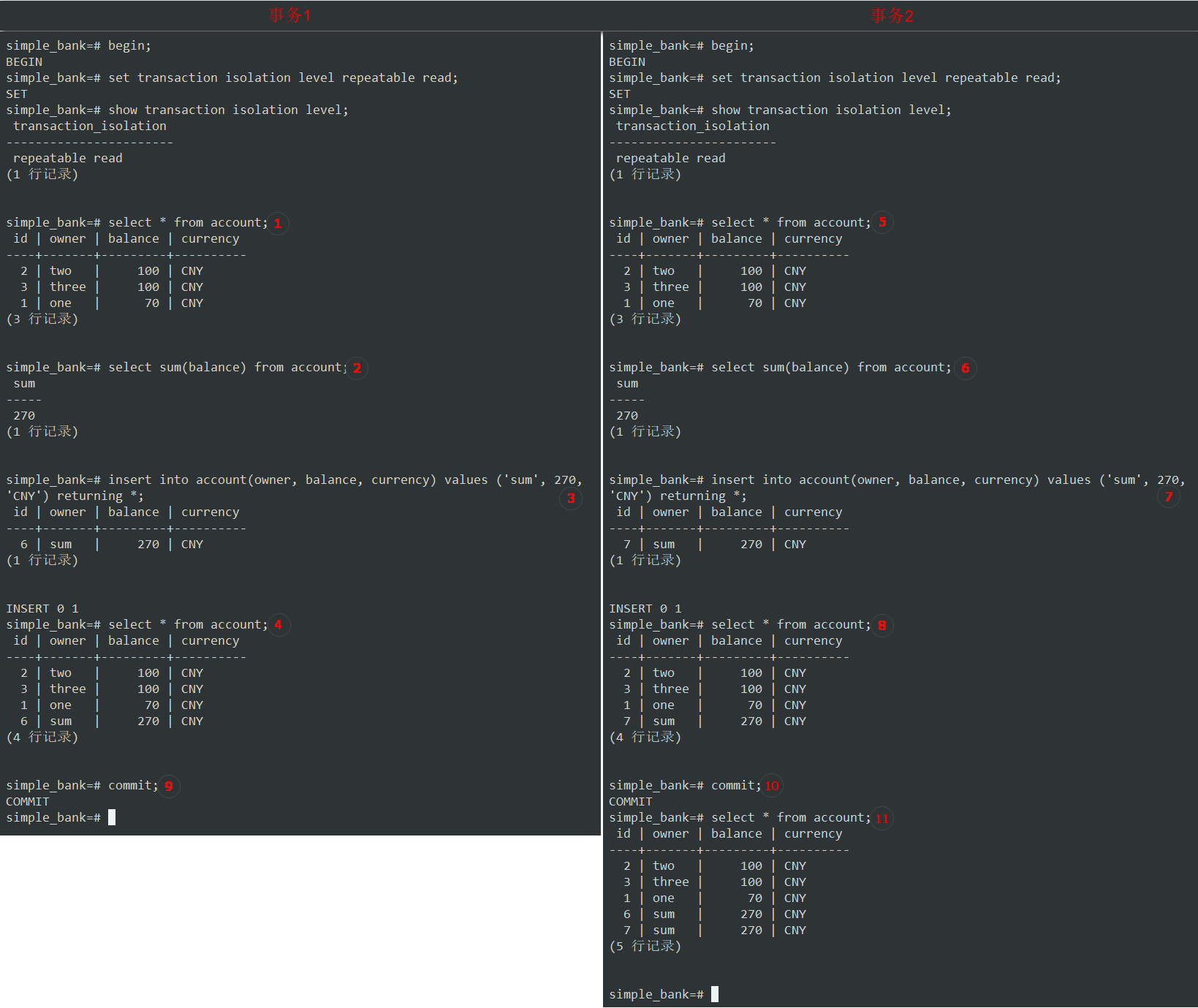
-
让我们开始2个新事务,并将其隔离级别设置为
repeatable read。 -
在事务1中,查询所有帐户记录。
-
现在,假设我们有一个案例,我们必须计算所有帐户余额的总和,然后使用该总余额创建一个新帐户。因此,让我们在事务1中执行③,往帐户表中插入一条新记录。
-
④现在可以在事务1中看到新记录了。
-
⑤由于使用的是可
repeatable read隔离级别,所以事务2中的 select 查询只获取原始的帐户列表,而没有事务1刚刚插入的新记录。 -
现在,事务2也像事务1中的③那样,往帐户表中插入一条新记录⑦。
-
⑧现在可以在事务2中看到跟事务1一样的新记录了。
-
让我们提交这两个事务,看看会发生什么。
-
可以看到两个事务都成功提交了,并且与2个重复的总记录,余额都为 270 元。
这就是
串行化异常。为什么会这样?
如果这2个交易是依次运行的,那么我们就不可能有2条记录,并且他们的总和都为 270 元。
不管是事务1还是事务2先运行,我们都应该有一个 270 元的记录,和一个 540 元的记录。
OK,这就是
repeatable read隔离级别中串行化异常的发生方式。
现在让我们尝试最高级别:Serializable,看看是否可以阻止这种异常。
Serializable(串行化)
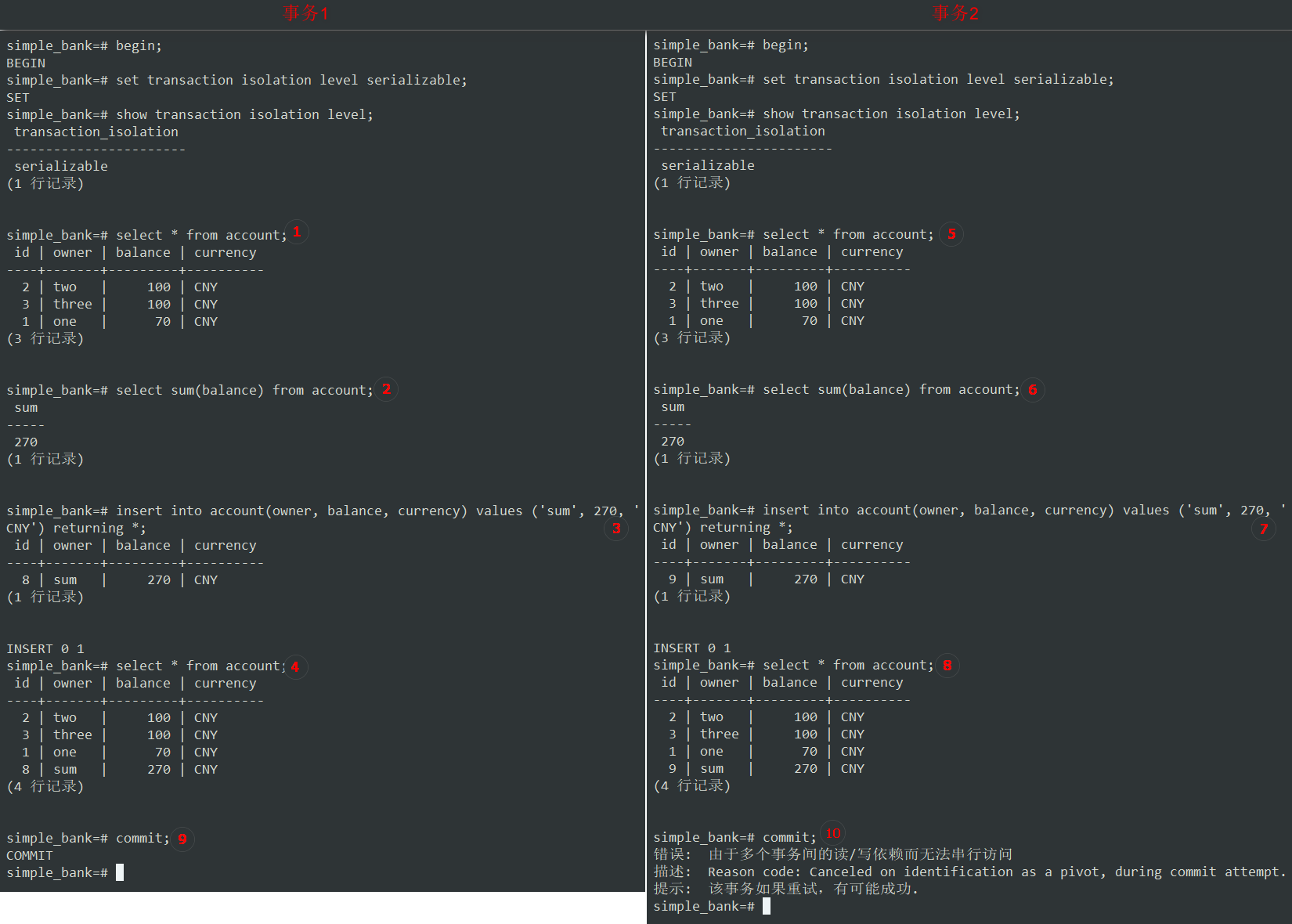
-
所有步骤同上。
-
但是这次只有事务1提交成功了,事务2却抛出了错误:
错误: 由于多个事务间的读/写依赖而无法串行访问
描述: Reason code: Canceled on identification as a pivot, during commit attempt
提示: 该事务如果重试,有可能成功Postgres还给了我们提示,如果我们重试,事务可能会成功。
所以这很好!完全防止了
串行化异常。2个并发事务不再像以前那样创建重复记录。
我们可以得出结论,Postgres使用依赖检测机制来检测潜在的读现象,并通过抛出错误来阻止它们。
五、MySQL如何处理串行化异常
另一方面,MySQL选择使用锁定机制来达到类似的结果。 让我们看看它如何处理序列化异常!
让我们打开两个MySQL控制终端,并将其事务隔离级别设置为serializable。
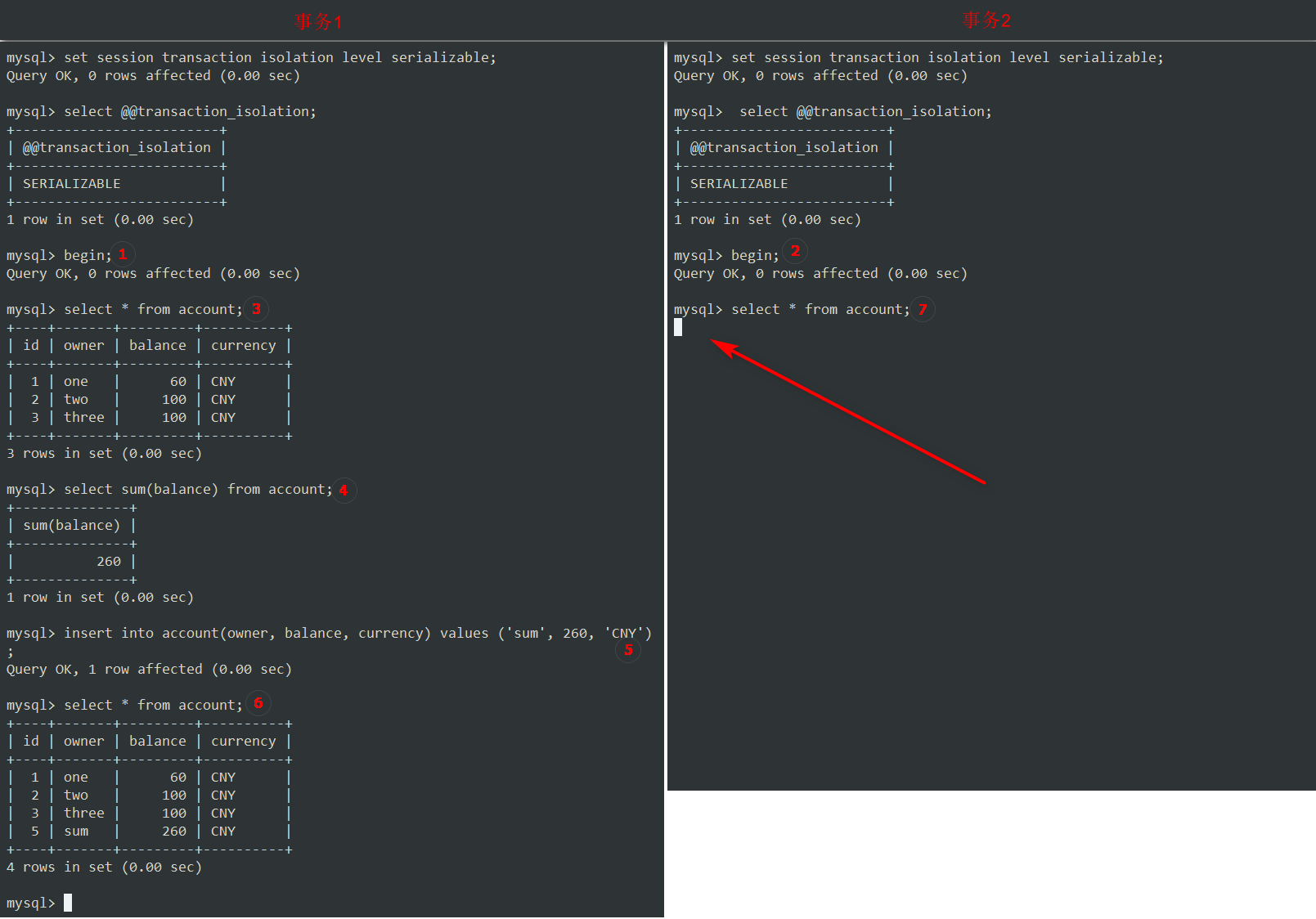
- 所有步骤同上。
- ⑦当事务2执行查询所有帐户时,它被阻止了。它需要等待事务1释放锁才能继续。
如果我们没有对事务1进行提交,那么过一段时间,事务2将会报错,如下:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
锁定等待超时,它提示让我们重试。

如果我们在事务2阻塞期间,提交了事务1,又会怎样呢?
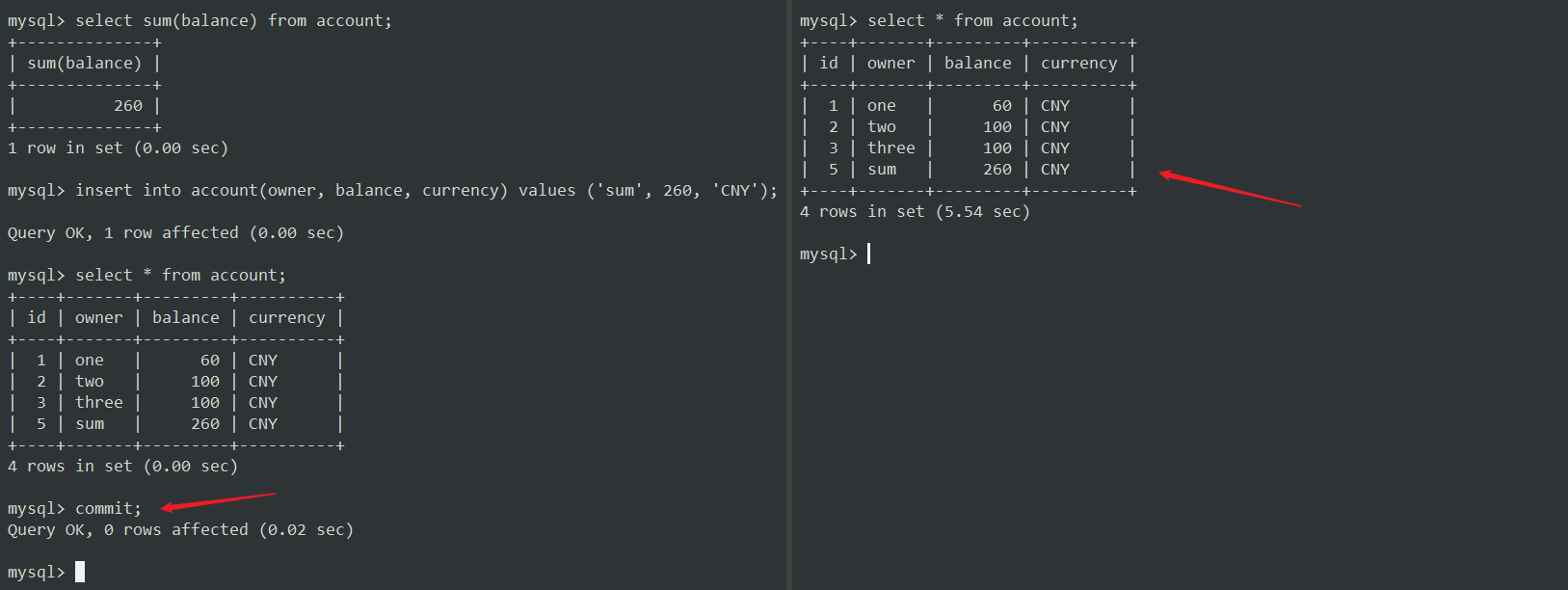
锁被释放了,事务2立即获得了其查询结果,
现在,我们继续在这个事务中运行 sum 和 insert 查询,最后提交它。
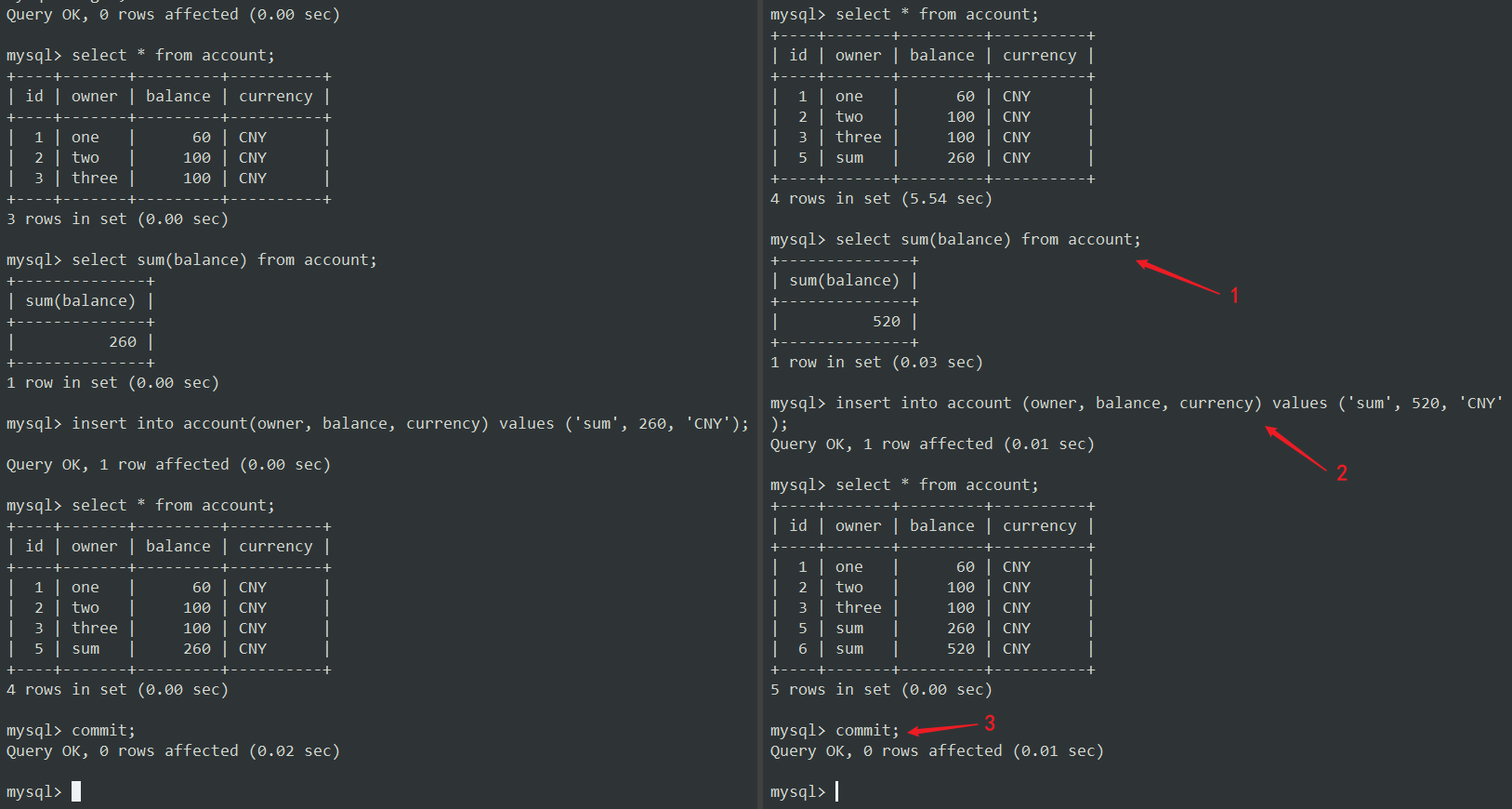
没有重复的 sum 记录。 因此,MySQL也通过其锁定机制成功地阻止了串行化异常。
现在我想在这两个事务中尝试不同的查询顺序。
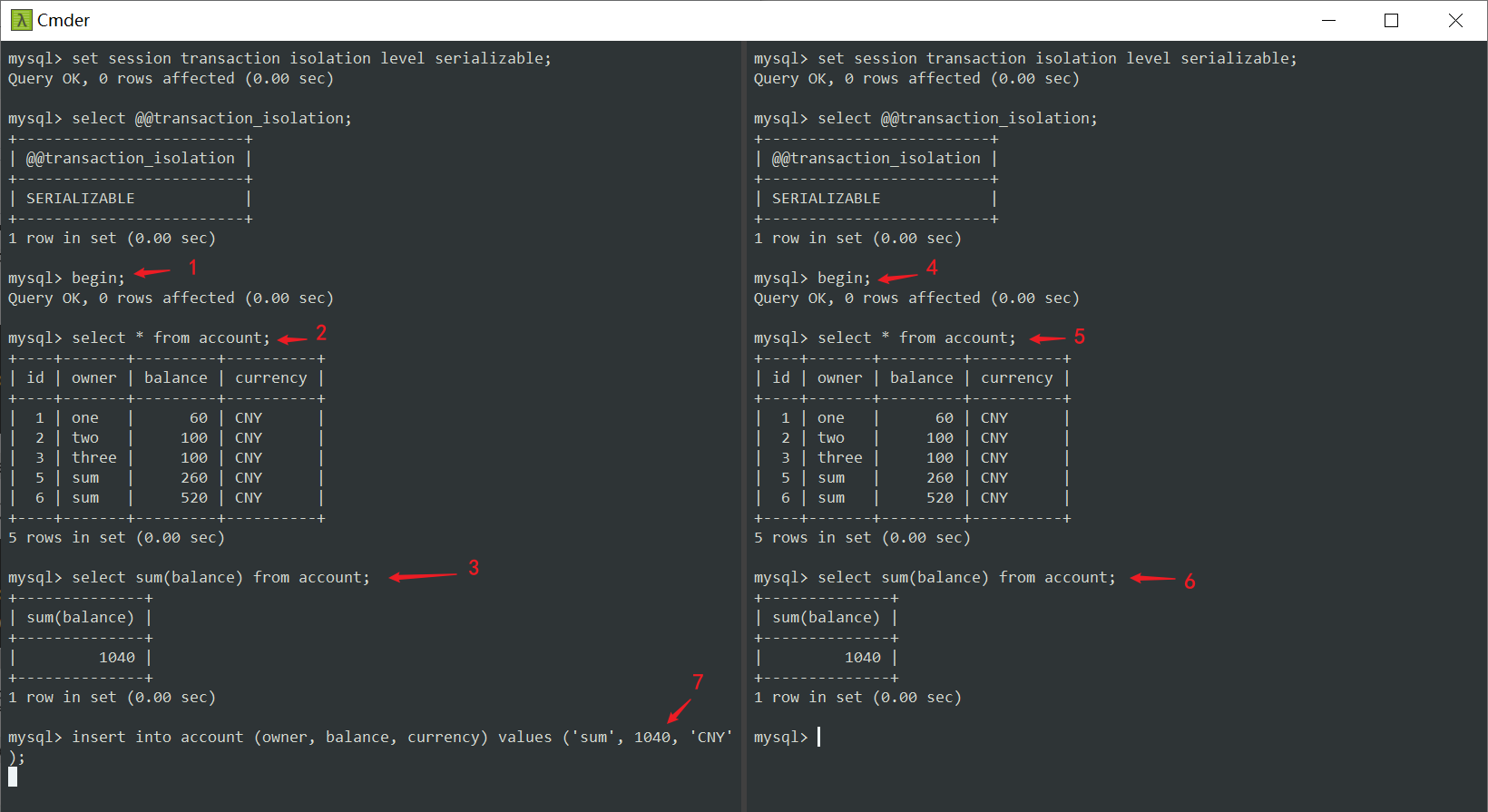
- 可以看到事务1被阻塞是因为事务2持有一个阻止其他事务更新的共享锁。
什么都不做的话,事务1同上将会报错:

如果在事务1阻塞期间,事务2也执行一条同样的sql,会怎么样呢?

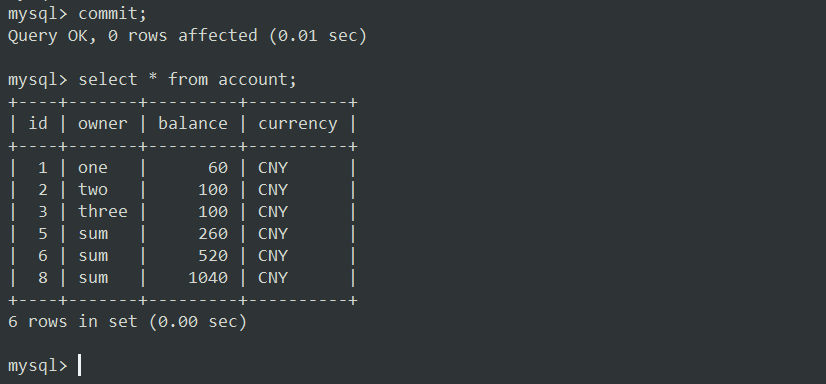
我们将会得到一个死锁,因为在这种情况下,两个事务在互相等待对方释放锁。并且事务2因死锁失败,而释放了锁,所以事务1成功获得锁,完成了插入操作。
因此,提交事务1后,我们可以看到成功插入了一条新的 sum 记录;数据库保持一致,没有串行化异常:
六、关于隔离级别和读现象之间的关系总结
MySQL

在MySQL中,最低的隔离级别read uncommitted允许所有4种现象发生。
read committed仅阻止脏读 (dirty read)。其余3种现象仍然可能。
repeatable read级别阻止了3种现象:脏读 (dirty read),不可重复读 (non-repeatable read),和幻读 (phantom read)。但它仍然有 序列化异常 (serialization anomaly),甚至会导致一些不一致的并发更新。
最高的隔离级别:串行化是最严格的。 它可以防止所有4种现象。这主要归功于它的锁定机制 (locking mechanism)。
Postgres

Postgres中的隔离级别与MySQL非常相似。 但是,仍然存在一些主要差异。
首先,read uncommitted隔离级别的行为与read committed相同。因此,基本上Postgres仅具有3个隔离级别,而不是MySQL中的4个。
其次,Postgres不像MySQL那样使用locking mechanism(锁定机制),但它使用了更好dependencies detection(依赖检测)技术来阻止不可重复读、不一致的并发更新和串行化异常。
另外,Postgres中的默认隔离级别仅是read committed,而在MySQL中是repeatable read。
切记:
使用高隔离级别时,要记住的最重要的一点是,可能存在一些错误、超时甚至死锁。 因此,我们应该谨慎地为我们的事务实现重试机制。
此外,每个数据库引擎可能会以不同的方式实现隔离级别。因此,请务必仔细阅读它的文档,并在开始编码之前先尝试使用它。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号