

[斯坦福大学2014机器学习教程笔记]第六章-分类回归
在这节以及接下来几节中,我们要开始讨论分类问题。这节将告诉我们为什么对于分类问题来说,使用线性回归并不是一个好主意。
在分类问题中,你要预测的变量y是一个离散的值,我们将学习一种叫做逻辑回归(Logistic Regression)的算法,这是当今最流行、使用最广泛的学习算法之一。
分类问题的例子有:垃圾邮件分类(判断一封电子邮件是否是垃圾邮件)、分类网上交易(判断某一个交易是否是欺诈,例如是否用盗取的信用卡等等)、肿瘤分类(判断一个肿瘤是恶性的还是良性的)。在这些问题中,我们尝试预测的变量y是可以有两个取值的变量(0或1)。我们用0表示的那一类还可以叫做负类(Negative Class),用1表示的那一类可以叫做正类(Positive Class)。一般来说,负类表示没有某样东西,比如说:没有恶性肿瘤。正类表示具有我们要寻找的东西。但是,什么是正类什么是负类是没有明确规定的。
现在我们要开始讨论只包含0和1两类的分类问题(即二元的分类问题)。那么,我们要如何开发一个分类算法呢?

这个例子的训练集是对肿瘤进行恶性或良性分类。注意到恶性与否只有两个值,0或者1。所以,我们可以做的就是对于这个给定的训练集,把我们学过的线性回归算法应用到这个数据集,用直线对数据进行拟合。如果你用直线去拟合这个训练集,你有可能得到如下图的假设直线。
如果你想做出预测,你可以将分类器输出的阀值设为0.5(即纵坐标值为0.5),如果假设输出一个大于等于0.5,可以预测y=1,如果小于0.5则预测y=0。在这个特定的例子中,似乎线性回归做的事情很合理。但是,尝试改变一下问题,将横轴延长一点。假如我们有另外一个训练样本位于右边远处。

注意这个额外的训练样本,显然它并不会改变什么,假设依然很好。但是,当我们再增加一个额外的例子,如果我们这时运行线性回归,我们会得到另一条直线(如下图)去拟合数据。此时,如果将阀值设为0.5,根据分析,这显然不是一个好的线性回归。
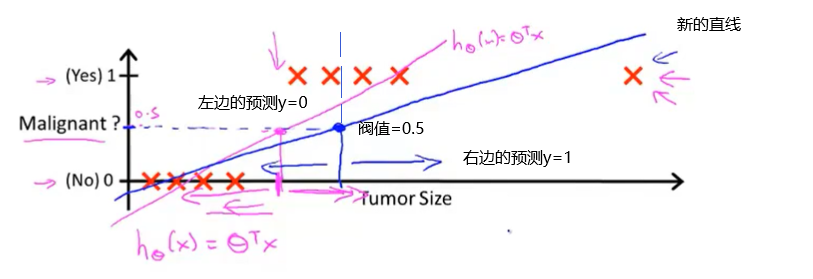
所以,将线性回归运用到分类问题中通常不是一个好主意。在增加额外的样本之前,之前的线性回归看起来很好。但是,对数据集进行线性回归,有时会很好,但这不意味着这就是一个很好的方法。因为我们可能会遇到像增加了一个额外样本之后的问题,这时,效果就比较糟糕了。尽管我们知道标签y应该取值0或者1,但是如果算法得到的值远大于1或者远小于0的话,还是会感觉很奇怪。
所以我们在接下来的要研究的算法就叫做逻辑回归算法,这个算法的特点是:它的输出值永远在0到1之间。顺便说一下,我们通常将逻辑回归算法视为一种分类算法。有时候可能因为这个算法的名字中出现了“回归”让人会感到困惑,但逻辑回归算法实际上是一种分类算法,它适用于标签y为离散值0或1的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号