

[斯坦福大学2014机器学习教程笔记]第四章-多元梯度下降法演练Ⅰ:特征缩放
在本节和下一节中,我们将介绍一下梯度下降运中的实用技巧。本节主要介绍一个称为特征缩放的方法。
这个方法如下:如果你有一个机器学习问题,这个问题有多个特征。如果你能确保这些特征都处在一个相似的范围(即不同特征的取值在相近的范围内),那么这样梯度下降法就能更快地收敛。具体来说,假如现在有一个具有两个特征的问题,其中x1是房屋大小,取值为0-2000,x2是卧室的数量,取值为1-5。如果我们画出代价函数J(θ)的等值线大概如下图所示。
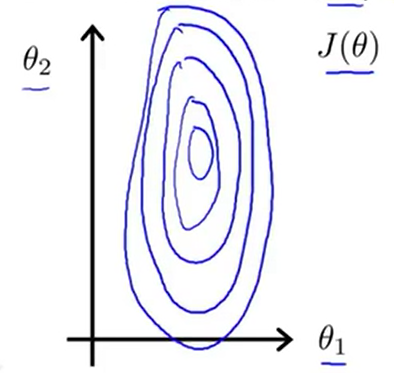
(J(θ)其实是关于θ0,θ1,θ2的函数,但是我们在这里暂时不考虑θ0,假设这个函数的变量只有θ1,θ2)我们会发现,x1的取值范围要远大于x2的取值范围,那么它会呈现出一种非常歪斜而且椭圆的形状。实际上,2000:5的比例会让这个椭圆更加细长。
如果我们在这种代价函数上运行梯度下降的话,可能需要花很长的一段时间,并且可能会来回波动,最终才会收敛到全局最小值。
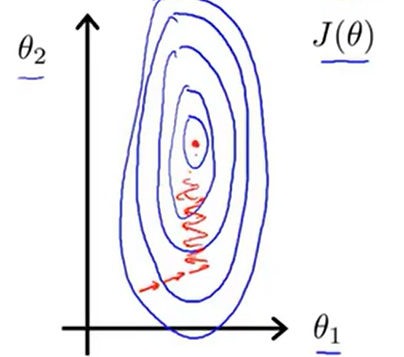
对于这种情况,我们有一种有效的方法是进行特征缩放。具体来说,我们将x1定义为房屋大小/2000,x2定义为卧室的数量/5。那么代价函数J(θ)的等值线就不会像之前一样偏移得十分严重了。而且,在这种代价函数上运行梯度下降的话,我们会找到一条更直接的路径。
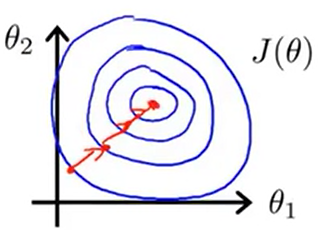
因此,通过这些特征缩放,两个变量的取值范围变得十分相近。在上面的例子中x1和x2的取值都在0到1之间。这样我们的梯度下降法就能更快地收敛。
更一般地,我们在执行特征缩放的时候,通常情况下我们的目的都是将特征的取值约束在-1到1的范围内。根据上一节所设的x0=1,显然它已经在这个范围内了,但对于其他的特征,我们可能需要通过除以不同的数来让它们处于同一个范围内。其实-1到1这个范围并不是严格去规定的,如0≤x1≤3,-2≤x2≤0.5这些也是可以的。但是,如果-100≤x3≤100,这个范围就有点大得太多了,所以这个可能是一个范围不太合适的特征。同样的,如果-0.0001≤x4≤0.0001,这个范围就有点小得太多了,所以这个可能是一个范围不太合适的特征。(可以接受的氛围:-1/3到1/3,-3到3)。
除了将特征值除以最大值之外,在特征缩放中,有时我们也会进行一个称为归一化的工作。如果我们可以用xi-μi来替换特征xi,让特征值的平均值为0。但是,我们并不需要将这一步应用到x0中,因为它总是等于1的。
在上面讲到的例子中,我们进行归一化操作后,我们会得到
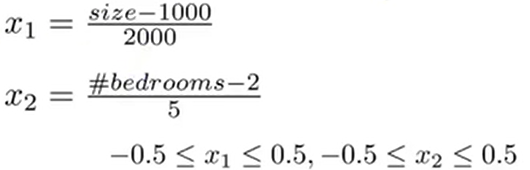
根据这个,我们可以得到一个新的x1和x2的取值范围。
- 更一般的规律就是:我们可以将xi替换为(xi-μi)/si。其中μi是训练集中特征xi的平均值,si是该特征值的范围(最大值减去最小值),或者把si设为变量的标准差。
根据这个,其实上面的x2中的s2应该为4,但其实并没有太大的区别。特征缩放并不需要太精确,我们只是为了让梯度下降运行地更快一点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号