
torch.nn
参见:https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-nn
一、Parameter
class torch.nn.Parameter()
Variable 的子类/一种。Paramenters和Modules一起使用的时候会有一些特殊的属性,即:当Paramenters赋值给Module的属性的时候,
他会自动的被加到 Module的 参数列表中(即:会出现在 parameters() 迭代器中),而把Varibale赋值给Module属性则不会有这样的影响。
二、Containers(容器)
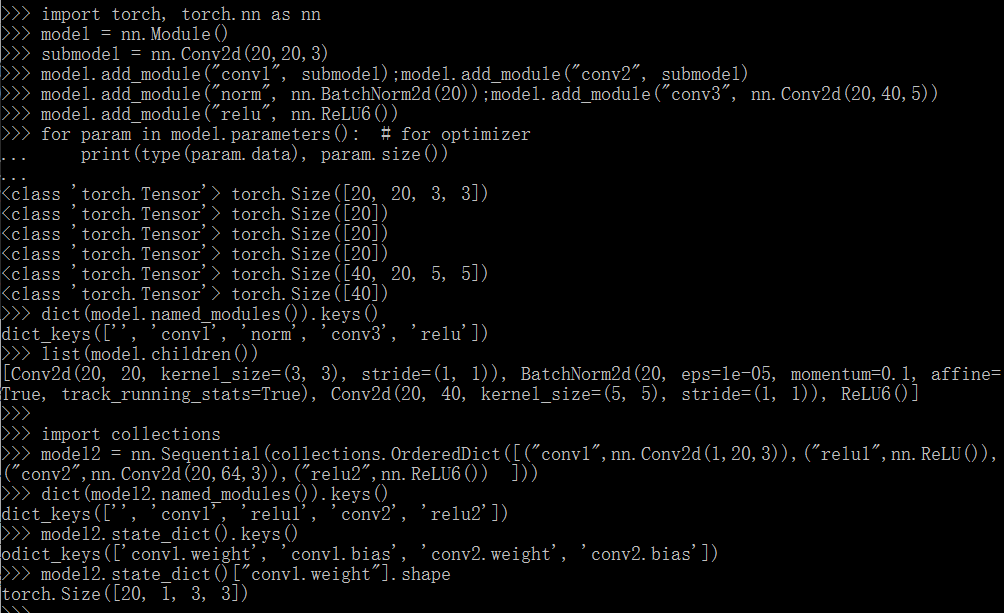
1、class torch.nn.Module()
- add_module(name, module)
import torch.nn as nn
model = nn.Module()
model.add_module("conv", nn.Conv2d(10,20,4))
print(model.conv)
- children()
- modules()
for sub in model.children():
print(sub)
- named_children()
- named_modules(meno=None, prefix='')
for name,sub in model.named_children():
print("name is :", name, ",and module is:", sub)
- parameters(memo=None) #包含模型所有参数的迭代器,一般用以当作optimizer的参数
for param in model.parameters():
print(type(param.data), param.size())
- register_forward_hook(hook)
- register_backward_hook(hook)
在module上注册一个backward hook。 每次调用backward()计算输出的时候,这个hook就会被调用。
- register_buffer(name, tensor)
- register_parameter(name, param)
向module添加 parameter, BatchNorm’s running_mean 不是一个 parameter, 但是它也是需要保存的状态之一.
- state_dict(destination=None, prefix='')[source]
返回一个字典,保存着module的所有状态, model.state_dict().keys()返回 parameter和buffer的 names。
2、class torch.nn.Sequential(* args)
时序容器,众多Modules 以其传入的顺序被添加到容器中。两种使用如下:
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1,20,5), nn.ReLU(),
nn.Conv2d(20,64,5), nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict(
[ ('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU()) ])
)
3、class torch.nn.ModuleList(modules=None)[source]
将submodules保存在一个list中,初始化modulelist = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])
- append(module)[source] #等价于list.append()
- extend(modules)[source] #等价于list.extend()
4、class torch.nn.ParameterList(parameters=None)
将parameter保存在一个list中,初始化paralist = nn.ParameterList([nn.Parameter(torch.randn(10, 10)) for i in range(10)])
- append(parameter)[source]
- extend(parameters)[source]
三、卷积层 池化层 非线性激活 Normalization 损失函数
Conv1d文本卷积、Conv2d图像卷积
1、class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, group
- padding(
intortuple,optional) - 输入的每一条边补充0的层数 - dilation(
intortuple,optional) – 卷积核元素之间的间距 用以空洞卷积 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数
eg:
# m = nn.Conv2d(16, 33, 3, stride=2) # With square kernels and equal stride
# m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
input = autograd.Variable(torch.randn(20, 16, 50, 100))
output = m(input)
变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels,kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channels)
2、class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_model=False)
class torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True)
- return_indices - 如果等于
True,会返回输出最大值的序号,对于上采样操作会有帮助 - ceil_mode - 如果等于
True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
class torch.nn.AdaptiveMaxPool2d(output_size, return_indices=False)
- 对输入信号,提供2维的自适应最大池化操作 对于任何输入大小的输入,可以将输出尺寸指定为H*W
关于MaxPool1d、MaxPool2d的区别:https://www.jianshu.com/p/c5b8e02bedbe
3、 class torch.nn.ReLU(inplace=False) #max(0,x)
class torch.nn.ReLU6(inplace=False) #min(max(0,x), 6)
class torch.nn.ELU(alpha=1.0, inplace=False) #max(0,x) + min(0, alpha * (e^x - 1))带泄露
class torch.nn.Sigmoid()
4、class torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
对小批量(mini-batch)3d数据组成的4d输入进行批标准化(Batch Normalization)操作:
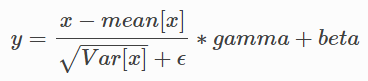
在每一个小批量(mini-batch)数据中,计算输入各个维度的均值和标准差。gamma与beta是可学习的大小为C的参数向量(C为输入大小)。
eg:
m = nn.BatchNorm2d(100)
input = autograd.Variable(torch.randn(20, 100, 35, 45)) #import torch.autograd as autograd
output = m(input)
5、损失函数
使用eg:
loss = nn.L1Loss()
output = loss(m(input), target) #两个参数可以任意shape,但元素数量都为n。
class torch.nn.L1Loss(size_average=True)

class torch.nn.MSELoss(size_average=True)

class torch.nn.CrossEntropyLoss(weight=None, size_average=True)
 二维矩阵中某class的loss
二维矩阵中某class的loss
 对该class的loss加权,适用于训练样本不均衡时
对该class的loss加权,适用于训练样本不均衡时
input_shape(num_batch, num_classes)、target_shape(num_batch);最后求解的loss为各classes下的加权平均 标量。
class torch.nn.UpsamplingNearest2d(size=None, scale_factor=None)
通过size或者scale_factor来指定上采样后的图片大小shape(N,C,H_in,W_in)-> shape(N,C,H_out,W_out).
5、其他
class torch.nn.Linear(in_features, out_features, bias=True) # 相当于全连接层
class torch.nn.Dropout2d(p=0.5, inplace=False) # 随机以概率p将输入张量中部分通道设置为0,每次前向调用都随机
class torch.nn.PairwiseDistance(p=2, eps=1e-06) #张量之间的距离
四、torch.nn.functional https://pytorch-cn.readthedocs.io/zh/latest/package_references/functional/
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)

torch.nn.functional.avg_pool2d(input, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True)
torch.nn.functional.max_pool2d(input, kernel_size, stride=None, padding=0, dilation=1, ceil_mode=False, return_indices=False)

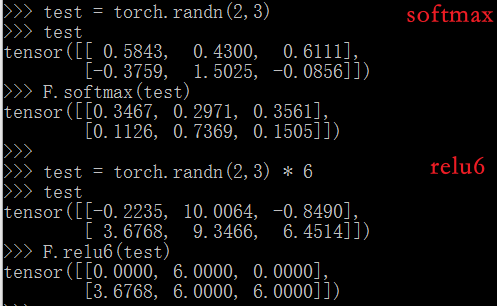
torch.nn.functional.relu6(input, inplace=False)
torch.nn.functional.leaky_relu(input, negative_slope=0.01, inplace=False)
torch.nn.functional.softmax(input)
torch.nn.functional.linear(input, weight, bias=None) #线性函数
torch.nn.functional.dropout(input, p=0.5, training=False, inplace=False) #Dropout
torch.nn.functional.pairwise_distance(x1, x2, p=2, eps=1e-06) #距离函数F.pairwise_distance(torch.randn(20,24), torch.randn(20,24))
torch.nn.functional.cross_entropy(input, target, weight=None, size_average=True) #损失函数,input_shape=(N,C) target_shape=(N)
torch.nn.functional.pad(input, pad, mode='constant', value=0)[source] #input和pad是维度相同的元组
2021-10-20 10:26:33

 浙公网安备 33010602011771号
浙公网安备 33010602011771号