卷积神经网络之卷积计算、作用与思想
博客:blog.shinelee.me | 博客园 | CSDN
卷积运算与相关运算
在计算机视觉领域,卷积核、滤波器通常为较小尺寸的矩阵,比如\(3\times3\)、\(5\times5\)等,数字图像是相对较大尺寸的2维(多维)矩阵(张量),图像卷积运算与相关运算的关系如下图所示(图片来自链接),其中\(F\)为滤波器,\(X\)为图像,\(O\)为结果。
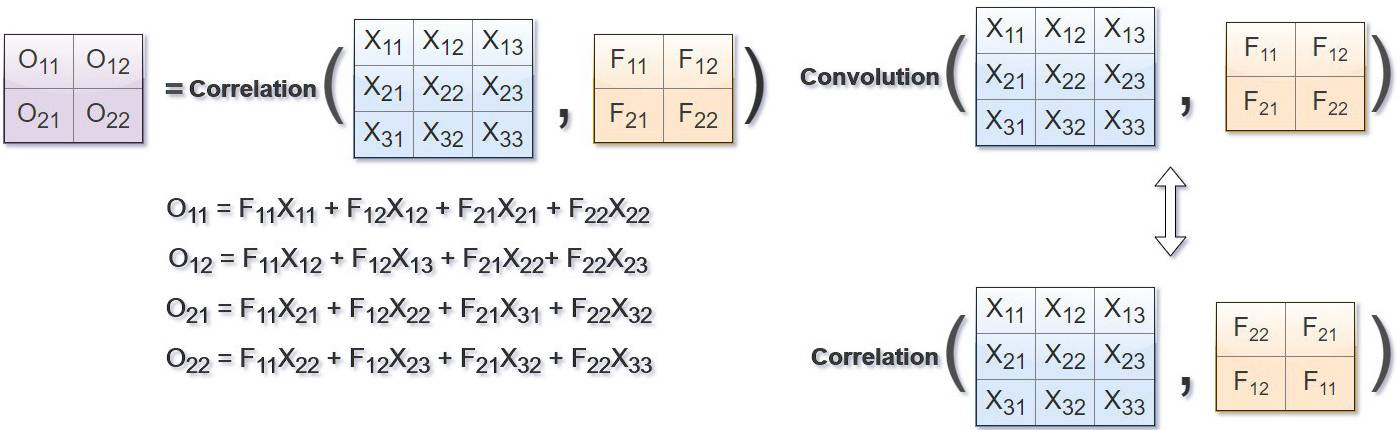
相关是将滤波器在图像上滑动,对应位置相乘求和;卷积则先将滤波器旋转180度(行列均对称翻转),然后使用旋转后的滤波器进行相关运算。两者在计算方式上可以等价,有时为了简化,虽然名义上说是“卷积”,但实际实现时是相关。
在二维图像上,使用Sobel Gx滤波器进行卷积如下图所示(图片来自链接),
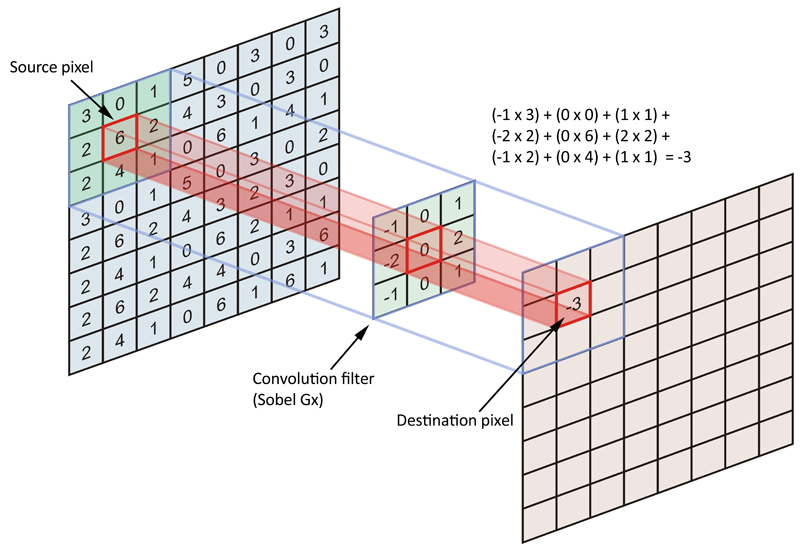
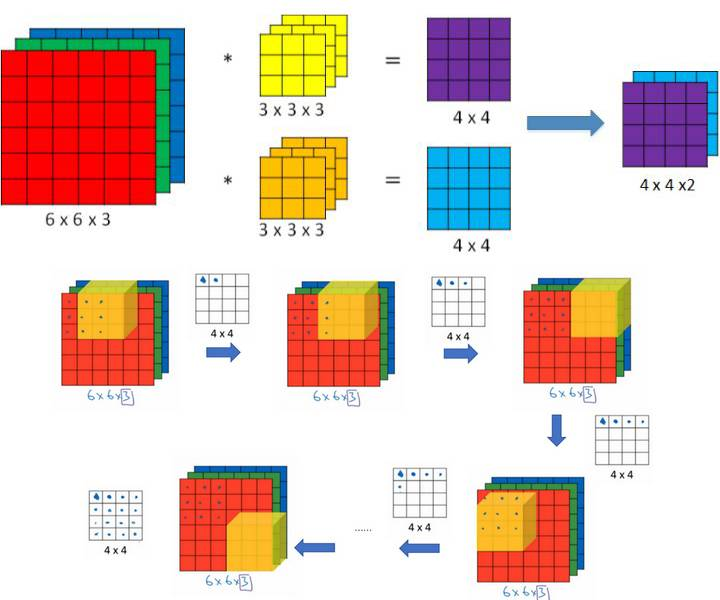
当输入为多维图像(或者多通道特征图)时,多通道卷积如下图所示(图片来自链接),图中输入图像尺寸为\(6\times6\),通道数为3,卷积核有2个,每个尺寸为\(3\times3\),通道数为3(与输入图像通道数一致),卷积时,仍是以滑动窗口的形式,从左至右,从上至下,3个通道的对应位置相乘求和,输出结果为2张\(4\times4\)的特征图。一般地,当输入为\(m\times n \times c\)时,每个卷积核为\(k\times k \times c\),即每个卷积核的通道数应与输入的通道数相同(因为多通道需同时卷积),输出的特征图数量与卷积核数量一致,这里不再赘述。
理解卷积
这里提供两个理解卷积的角度:
-
从函数(或者说映射、变换)的角度理解。 卷积过程是在图像每个位置进行线性变换映射成新值的过程,将卷积核看成权重,若拉成向量记为\(w\),图像对应位置的像素拉成向量记为\(x\),则该位置卷积结果为\(y = w'x+b\),即向量内积+偏置,将\(x\)变换为\(y\)。从这个角度看,多层卷积是在进行逐层映射,整体构成一个复杂函数,训练过程是在学习每个局部映射所需的权重,训练过程可以看成是函数拟合的过程。
-
从模版匹配的角度理解。 前面我们已经知道,卷积与相关在计算上可以等价,相关运算常用模板匹配,即认为卷积核定义了某种模式,卷积(相关)运算是在计算每个位置与该模式的相似程度,或者说每个位置具有该模式的分量有多少,当前位置与该模式越像,响应越强。下图为图像层面的模板匹配(图片来自链接),右图为响应图,可见狗头位置的响应最大。当然,也可以在特征层面进行模版匹配,卷积神经网络中的隐藏层即可以看成是在特征层面进行模板匹配。这时,响应图中每个元素代表的是当前位置与该模式的相似程度,单看响应图其实看不出什么,可以想像每个位置都有个“狗头”,越亮的地方越像“狗头”,若给定模板甚至可以通过反卷积的方式将图像复原出来。这里多说一句,我们真的是想把图像复原出来吗,我们希望的是在图像中找到需要的模式,若是通过一个非线性函数,将响应图中完全不像“狗头”的地方清零,而将像“狗头”的地方保留,然后再将图像复原,发现复原图中只有一个“狗头”,这是不是更美好——因为我们明确了图像中的模式,而减少了其他信息的干扰!

本篇文章将倾向于从第2个角度来理解卷积神经网络。
卷积能抽取特征
上一节中提到了“狗头”模板,如果把卷积核定为“狗头”模板会有什么问题?将缺乏灵活性,或者说泛化能力不够,因为狗的姿态变化是多样的,如果直接把卷积核定义得这么“死板”,狗换个姿势或者换一条狗就不认得了。
那么,为了适应目标的多样性,卷积核该怎么设计呢?这个问题,我们在下一节回答,这里先看看人工定义的卷积核是如何提取特征的。
以下图sobel算子为例(图片来自链接),对图像进行卷积,获得图像的边缘响应图,当我们看到响应图时,要知道图中每个位置的响应代表着这个位置在原图中有个形似sobel算子的边缘,信息被压缩了,响应图里的一个数值其实代表了这个位置有个相应强度的sobel边缘模式,我们通过卷积抽取到了特征。

人工能定义边缘这样的简单卷积核来描述简单模式,但是更复杂的模式怎么办,像人脸、猫、狗等等,尽管每个狗长得都不一样,但是我们即使从未见过某种狗,当看到了也会知道那是狗,所以对于狗这个群体一定是存在着某种共有的模式,让我们人能够辨认出来,但问题是这种模式如何定义?在上一节,我们知道“死板”地定义个狗的模板是不行的,其缺乏泛化能力,我们该怎么办?
通过多层卷积,来将简单模式组合成复杂模式,通过这种灵活的组合来保证具有足够的表达能力和泛化能力。
多层卷积能抽取复杂特征
为了直观,我们先上图,图片出自论文《Visualizing and Understanding Convolutional Networks》,作者可视化了卷积神经网络每层学到的特征,当输入给定图片时,每层学到的特征如下图所示,注意,我们上面提到过每层得到的特征图直接观察是看不出什么的,因为其中每个位置都代表了某种模式,需要在这个位置将模式复现出来才能形成人能够理解的图像,作者在文中将这个复现过程称之为deconvolution,详细查看论文(前文已经有所暗示,读者可以先独自思考下复现会怎么做)。

从图中可知,浅层layer学到的特征为简单的边缘、角点、纹理、几何形状、表面等,到深层layer学到的特征则更为复杂抽象,为狗、人脸、键盘等等,有几点需要注意:
-
卷积神经网络每层的卷积核权重是由数据驱动学习得来,不是人工设计的,人工只能胜任简单卷积核的设计,像边缘,但在边缘响应图之上设计出能描述复杂模式的卷积核则十分困难。
-
数据驱动卷积神经网络逐层学到由简单到复杂的特征(模式),复杂模式是由简单模式组合而成,比如Layer4的狗脸是由Layer3的几何图形组合而成,Layer3的几何图形是由Layer2的纹理组合而成,Layer2的纹理是由Layer1的边缘组合而成,从特征图上看的话,Layer4特征图上一个点代表Layer3某种几何图形或表面的组合,Layer3特征图上一个点代表Layer2某种纹理的组合,Layer2特征图上一个点代表Layer1某种边缘的组合。
-
这种组合是一种相对灵活的方式在进行,不同的边缘→不同纹理→不同几何图形和表面→不同的狗脸、不同的物体……,前面层模式的组合可以多种多样,使后面层可以描述的模式也可以多种多样,所以具有很强的表达能力,不是“死板”的模板,而是“灵活”的模板,泛化能力更强。
-
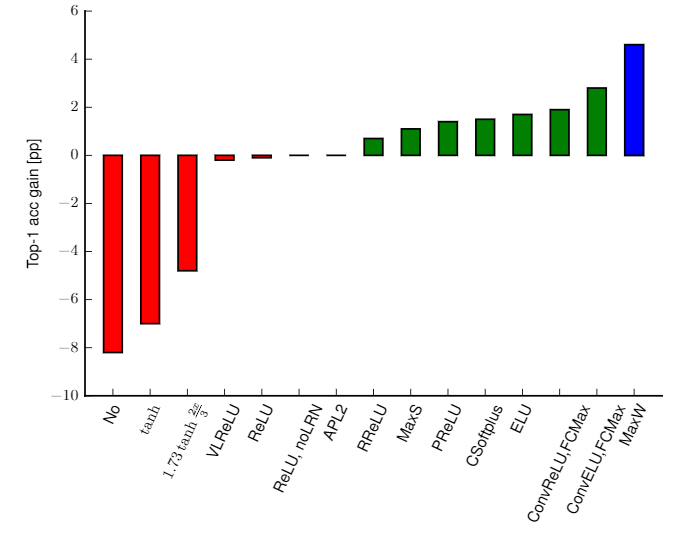
卷积神经网络真正使用时,还需要配合池化、激活函数等,以获得更强的表达能力,但模式蕴含在卷积核中,如果没有非线性激活函数,网络仍能学到模式,但表达能力会下降,由论文《Systematic evaluation of CNN advances on the ImageNet》,在ImageNet上,使用调整后的caffenet,不使用非线性激活函数相比使用ReLU的性能会下降约8个百分点,如下图所示。通过池化和激活函数的配合,可以看到复现出的每层学到的特征是非常单纯的,狗、人、物体是清晰的,少有其他其他元素的干扰,可见网络学到了待检测对象区别于其他对象的模式。
总结
本文仅对卷积神经网络中的卷积计算、作用以及其中隐含的思想做了介绍,有些个人理解难免片面甚至错误,欢迎交流指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号