

第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 编写论文查重的代码 |
psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| ·Estimate | .估计这个任务需要多少时间 | 180 | 230 |
| Development | 开发 | 15 | 20 |
| .Analysis | .需求分析(包括学习新技术) | 60 | 60 |
| .Design Spec | .生成设计文档 | 30 | 30 |
| .Design Review | .设计复审 | 5 | 5 |
| .Coding Standard | .代码规范(为目前的开发指定合适的规范) | 5 | 5 |
| .Design | .具体设计 | 30 | 20 |
| .Coding | .具体编码 | 60 | 115 |
| .Code Review | .代码复审 | 30 | 20 |
| .Test | .测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | 60 | 50 |
| .Test Report | .测试报告 | 45 | 45 |
| .Size Measurement | .计算工作量 | 5 | 5 |
| .Postmortem & Process Improvement Plan | .事后总结,并提出改进计划 | 0 | 0 |
| .合计 | 550 | 610 | 630 |
二、开发环境
操作系统:widows11
使用语言:c++
需求分析:
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
算法设计:
我这里使用的是基于哈希值的算法进行论文查重。
1.计算文本的哈希值:通过遍历文本中的每个字符或字符组合(如子字符串),使用哈希函数将它们转换成一个唯一的哈希值。常见的哈希函数可以是将字符的ASCII码相加等简单操作,但也可以使用更复杂的哈希函数。
2.构建哈希索引:将文本中的所有哈希值存储在一个索引结构中,如哈希表或哈希集合。这样可以使查找和比对哈希值的过程更加高效。
3.比对哈希值:对于原文和抄袭版论文,计算它们的哈希值,并在哈希索引中查找相同的哈希值。如果某个哈希值在原文和抄袭版论文中都存在,那么可以认为这个子字符串存在重复。
4.计算重复率:根据相同的哈希值数量以及总的子字符串数量,可以计算出重复率。通常,重复率可以用重复的子字符串数量与总的子字符串数量的比值来表示。
但是基于哈希值的算法通常只能检测到抄袭的存在,并给出相似度的估计,无法提供具体的抄袭内容。如果需要精确的抄袭内容,可能需要结合其他的算法或技术,如基于字符串匹配的算法或自然语言处理的方法。
代码:
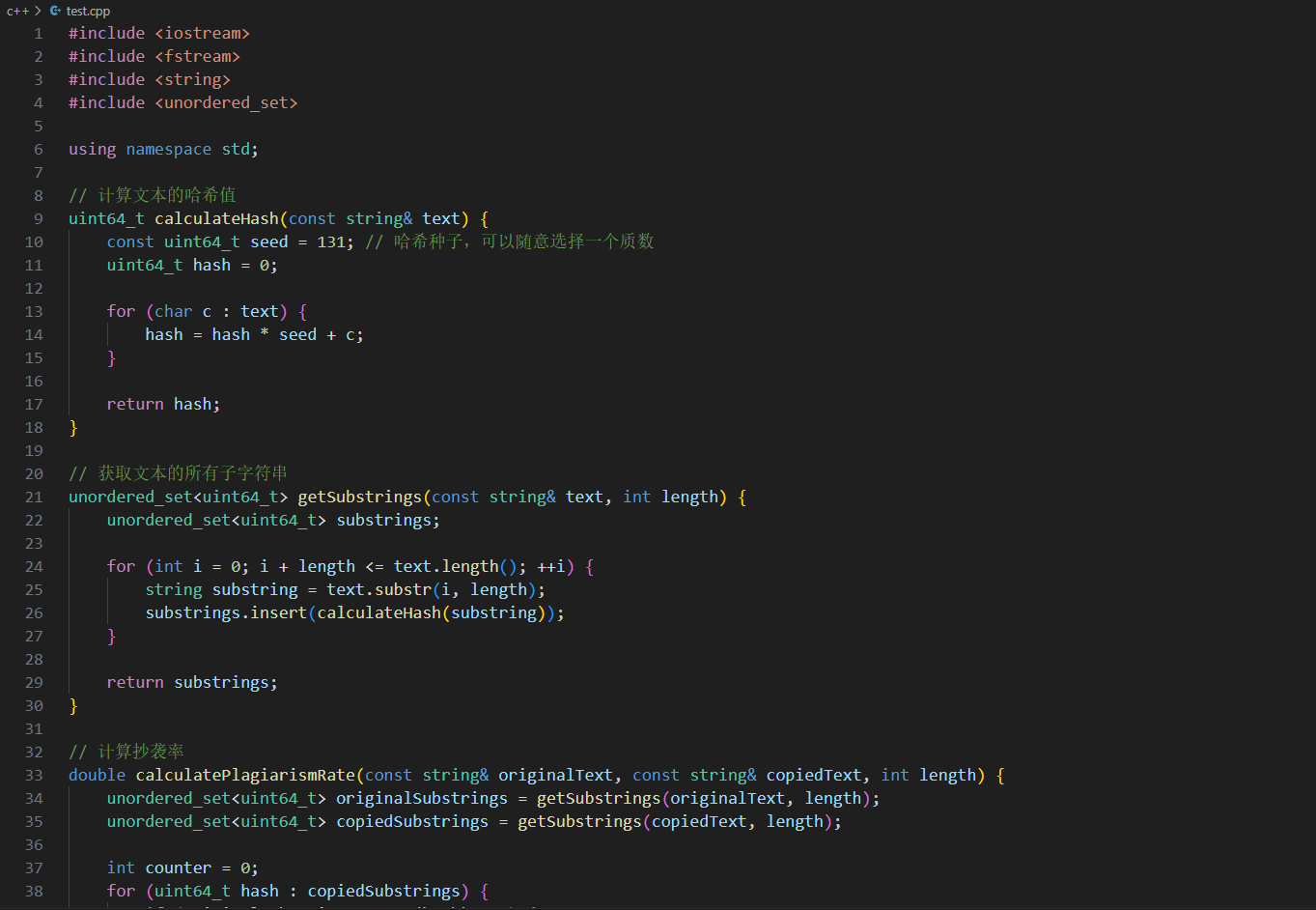
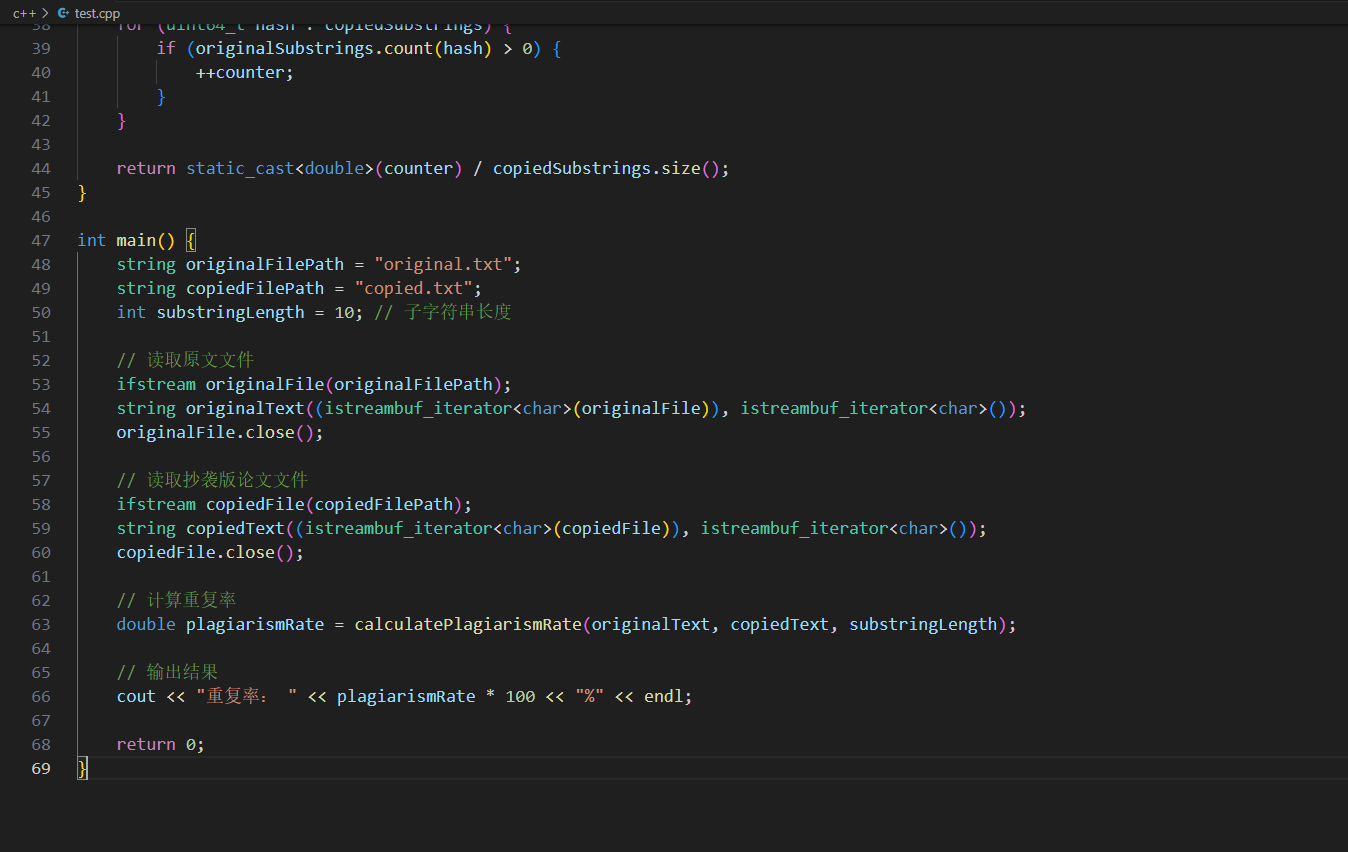
在这段代码中:
calculateHash 函数计算文本的哈希值。哈希值是使用一个质数种子乘以当前字符的 ASCII 值,然后加上之前的哈希值得到的。
getSubstrings 函数获取文本的所有长度为 length 的子字符串,并将子字符串的哈希值存储在一个无序集合中。
calculatePlagiarismRate 函数计算给定的两个文本的抄袭率。它首先获取原文和抄袭版论文的所有子字符串的哈希值,然后计算抄袭版论文中与原文相同的子字符串的数量,并将其除以抄袭版论文的总子字符串数量来得到重复率。
在 main 函数中,首先读取原文文件和抄袭版论文文件的内容,并将其存储在字符串变量中。然后调用 calculatePlagiarismRate 函数计算重复率,并将结果输出。
代码可以改进的地方:
结合其他算法或技术,单纯依靠哈希值的比对可能无法提供精确的抄袭内容。可以结合其他算法或技术,如字符串匹配算法或自然语言处理技术,来提取更多的信息并精确地确定抄袭的内容。
测试结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号