爬取B站番剧每周排行并对数据进行分析
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:BILIBILI番剧热度及排行
2.主题式网络爬虫爬取的内容与数据特征分析:内容为番剧名称,视频总播放量以及综合得分
3.主题式网络爬虫设计方案概述:通过对BILIBILI网页源代码的分析获得所需数据,并进行爬取和整理,从而得出所需结论
二、主题页面的结构特征分析
1.主题页面的结构与特征分析:红框内为我们所需要获取的数据
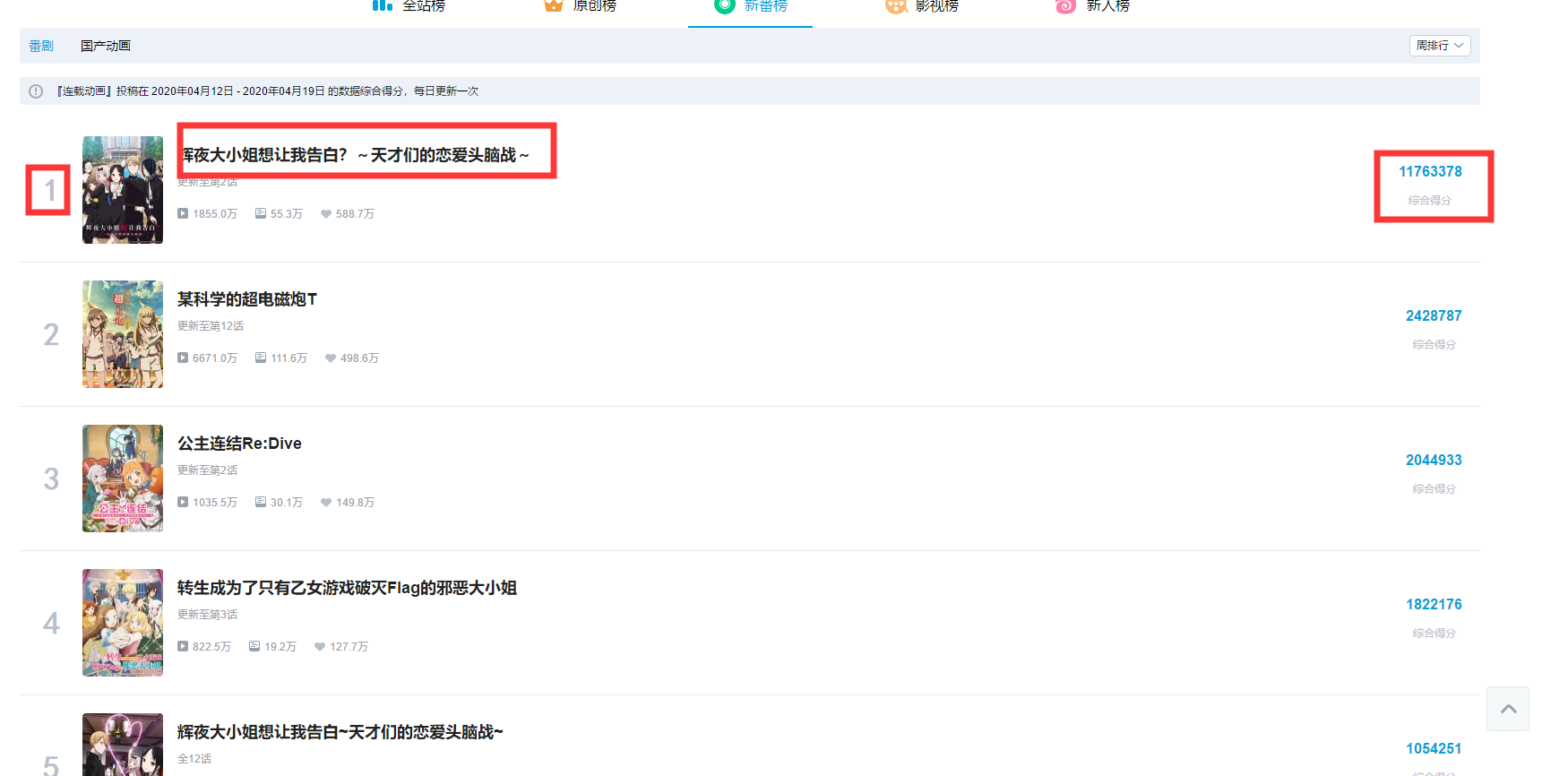
分别位于以下路径: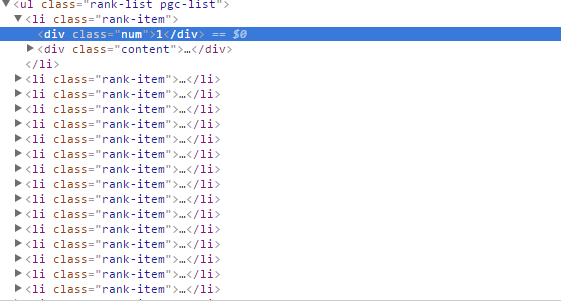


2.技术难点
所需的数据:“播放量”,“弹幕量”,‘收藏量’位于同一个标签“data-box”下,同时爬取较难区分(或需要进行额外区分)。
解决方法:利用bs4库的以下函数:【print(soup.find('meta', attrs={'name':'viewport'})) #获取第一个标签,根据属性过滤获取】爬取后,再根据字段进行分割
三、网络爬虫程序设计
1.数据爬取与采集:代码如下
def gettitle(soup): # 获取标题
getdata = soup.find_all(attrs={'class': 'title'})
data = []
for getdata in getdata:
data.append(getdata.text)
return data
def getscore(soup): # 获取评分
getdata = soup.find_all(attrs={'class': 'pts'})
data = []
for getdata in getdata:
data.append(getdata.text)
return data
def getplay(soup): # 获取播放量
getdata = soup.find_all(attrs={'class': 'data-box'})
data = []
for getdata in getdata:
data.append(getdata.text)
play = data[0:300:3]
return play
def getdanmu(soup): # 获取弹幕量
getdata = soup.find_all(attrs={'class': 'data-box'})
data = []
for getdata in getdata:
data.append(getdata.text)
play = data[1:300:3]
return play
def getfav(soup): # 获取收藏量
getdata = soup.find_all(attrs={'class': 'data-box'})
data = []
for getdata in getdata:
data.append(getdata.text)
play = data[2:300:3]
return play
将其分类标记并保存为csv文件
title = gettitle(soup)
danmu = getdanmu(soup)
play = getplay(soup)
score = getscore(soup)
fav = getfav(soup)
df = pd.DataFrame.from_dict({'排名': range(1, 51), '标题': title, '弹幕': danmu, '播放': play, '综合得分': score, '收藏': fav},
orient='index')
df = df.T
df.to_csv('D:/bilibilidata.csv')
2.对数据进行清洗和处理
已爬取的数据中包含有不同单位,对单位进行统一
filename = 'D:/bilibilidata.xls'
colnames = ["rank", "title", "danmu", "play", "score", "fav", ]
plt.rcParams['font.sans-serif'] = ['SimHei']
data = pd.read_csv(filename, skiprows=1, names=colnames)
play = []
pl = list(data.play)
for i in pl:
if i[-1] == "亿":
play.append(eval((i[:-1] * 10000)))
else:
play.append(eval(i))
danmu = []
dm = list(data.danmu)
for i in dm:
if i[-1] == "万":
danmu.append(eval(i[:-1]) * 10000)
else:
danmu.append(eval(i))
删除重复行
data.duplicated()
数据的可视化
(1)数据之间的相关性
print(data.corr())
print(data.describe() )
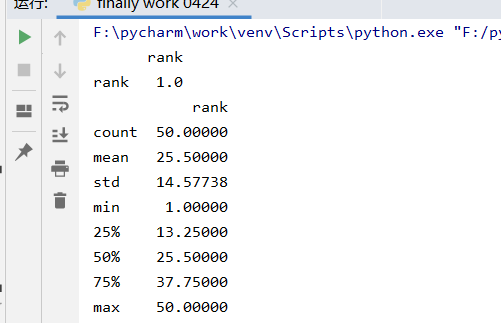
(2)数据可视化
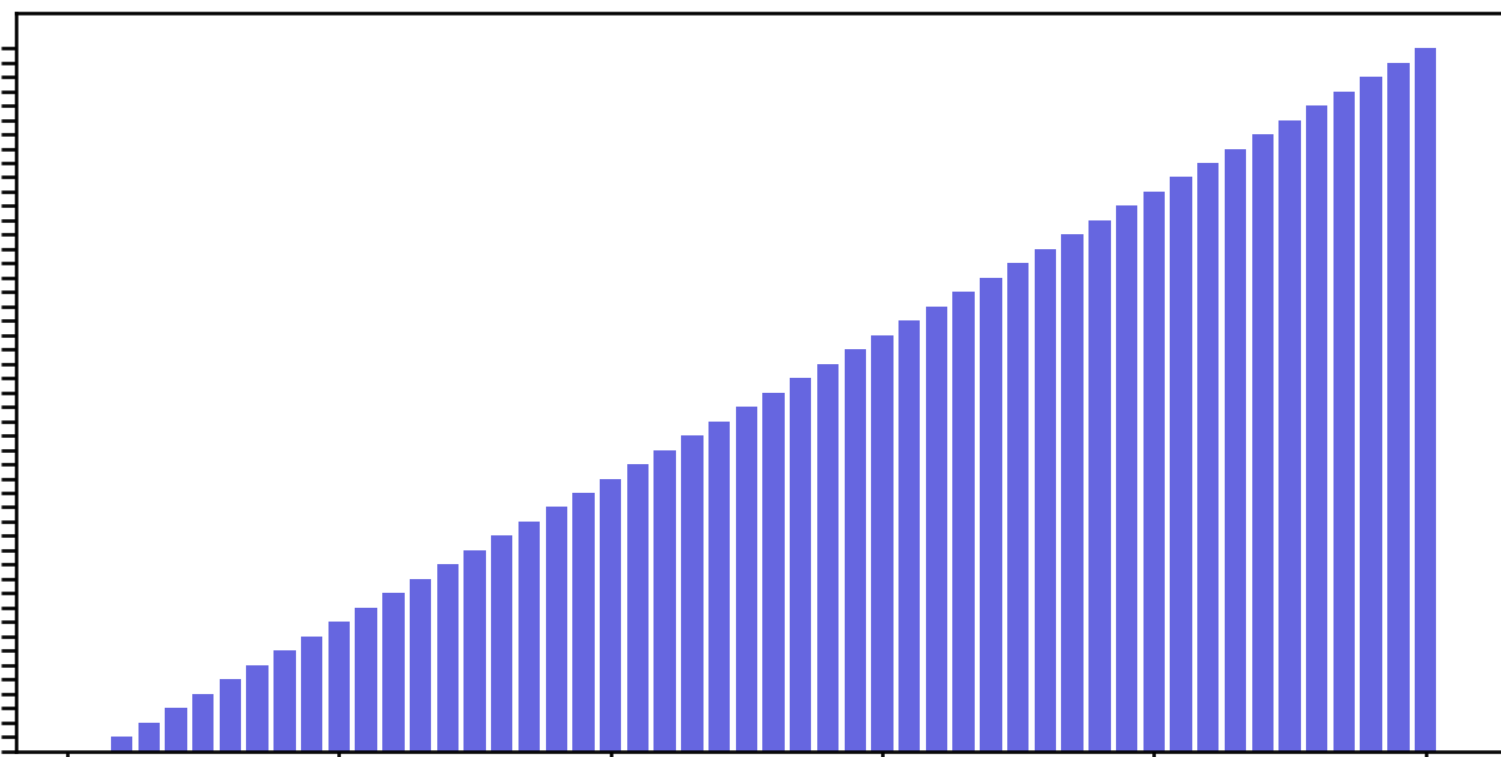
综合得分-排名直方图
plt.figure(dpi=240)
ranking = data.ranking
score = data.score
plt.bar(ranking,score,color=[0,0,0.8,0.6])
plt.title("综合得分直方图")
plt.xlabel("排名")
plt.ylabel("综合得分")
plt.show()
弹幕-排名直方图
plt.figure(dpi=240)
ranking = data.ranking
danmu = data.danmu
plt.bar(ranking,danmu,color=[0,0,0.8,0.6])
plt.title("弹幕-排名直方图")
plt.xlabel("排名")
plt.ylabel("弹幕")
plt.show()
![]()

播放-排名直方图
plt.figure(dpi=240)
ranking = data.ranking
play = data.play
plt.bar(ranking,play,color=[0,0,0.8,0.6])
plt.title("播放-排名直方图")
plt.xlabel("排名")
plt.ylabel("弹幕")
plt.show()
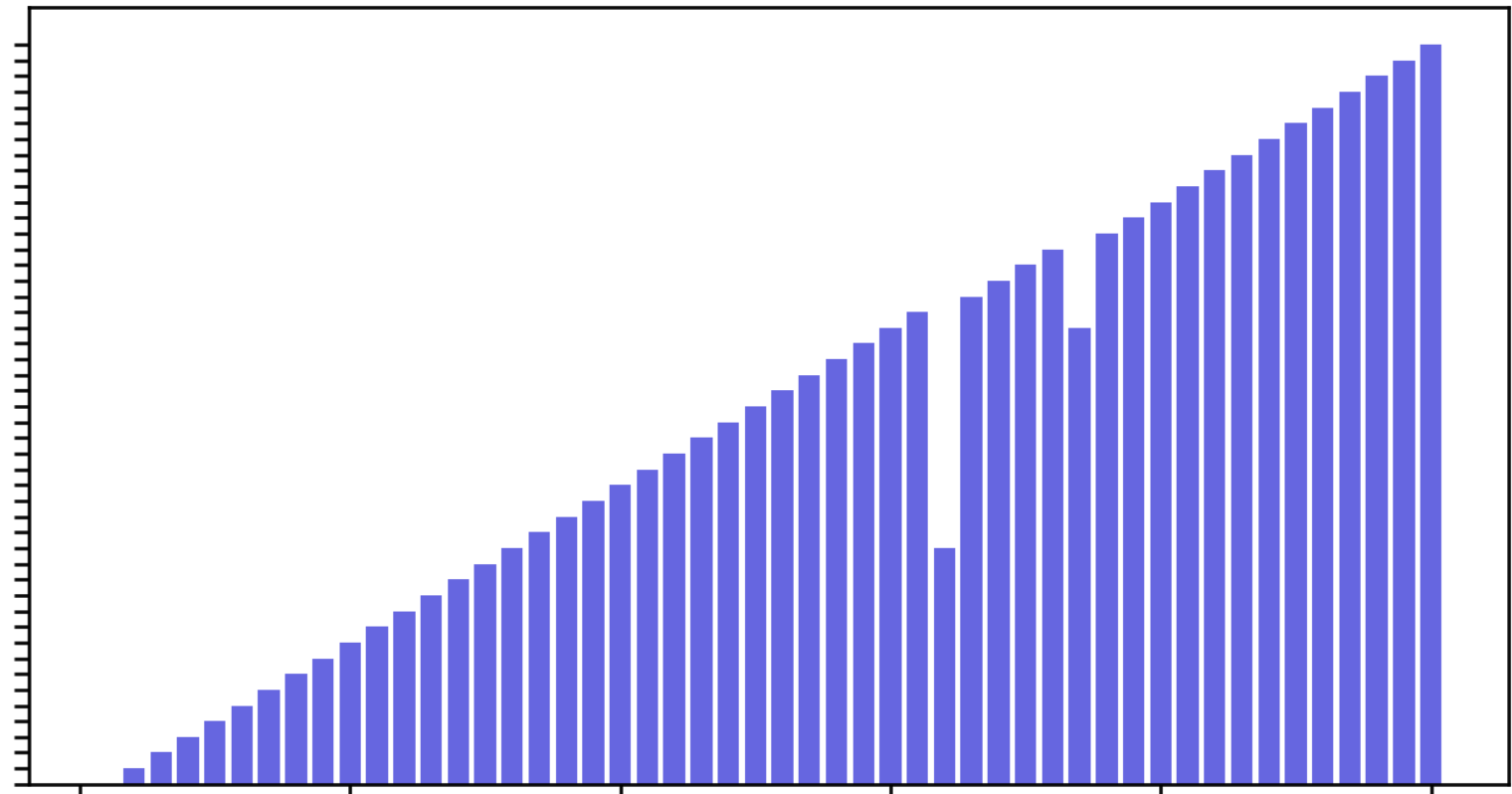
下略
3.建立回归方程
ranking = data.ranking
play = data.play
danmu = data.danmu
score = data.score
def ft(p, x):
a, b, c = p
return a * (x ** 2) + (b * x) + c
def er_ft(p, x, y):
return ft(p, x) - y
play_np = np.array(play)
score_np = np.array(score)
danmu_np = np.array(danmu)
ranking_np = np.array(ranking)
p0 = np.array(2, 3, 4)
plt.figure(dpi=240)
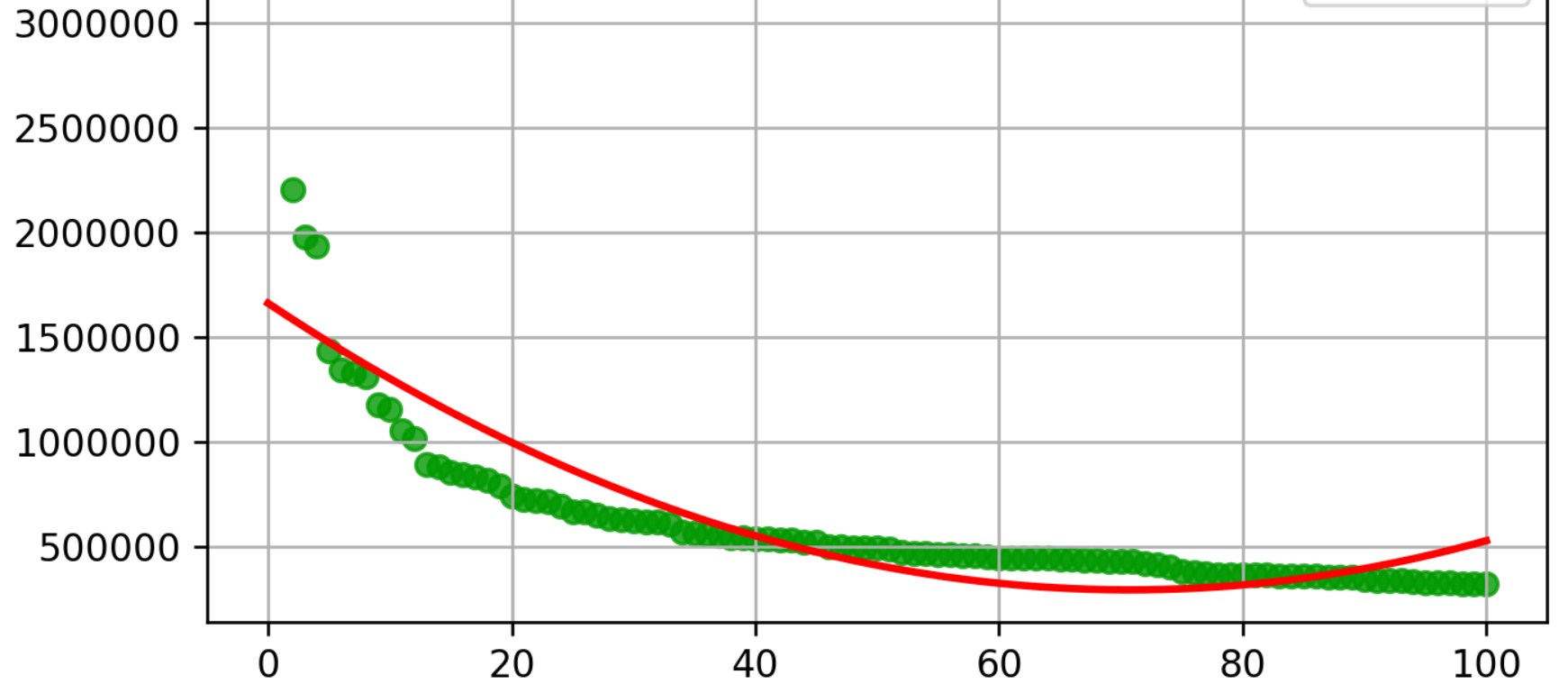
plt.scatter(ranking, play, label=u'样本数据', color=[0, 0, 0.8, 0.8])
P = leastsq(er_ft, p0, args=(ranking_np, play_np))
a, b, c = P[0]
x = np.linspace(0, 100, 1000)
y = a * (x ** 2) + (b * x) + c
plt.plot(x, y, color="green", label=u"拟合直线", linewidth=2)
plt.title('播放量散点图&拟合直线')
plt.xlabel("排名")
plt.ylabel("播放量")
plt.legend()
plt.grid()
plt.show()
例如
(1)排名与播放量的回归曲线和散点图
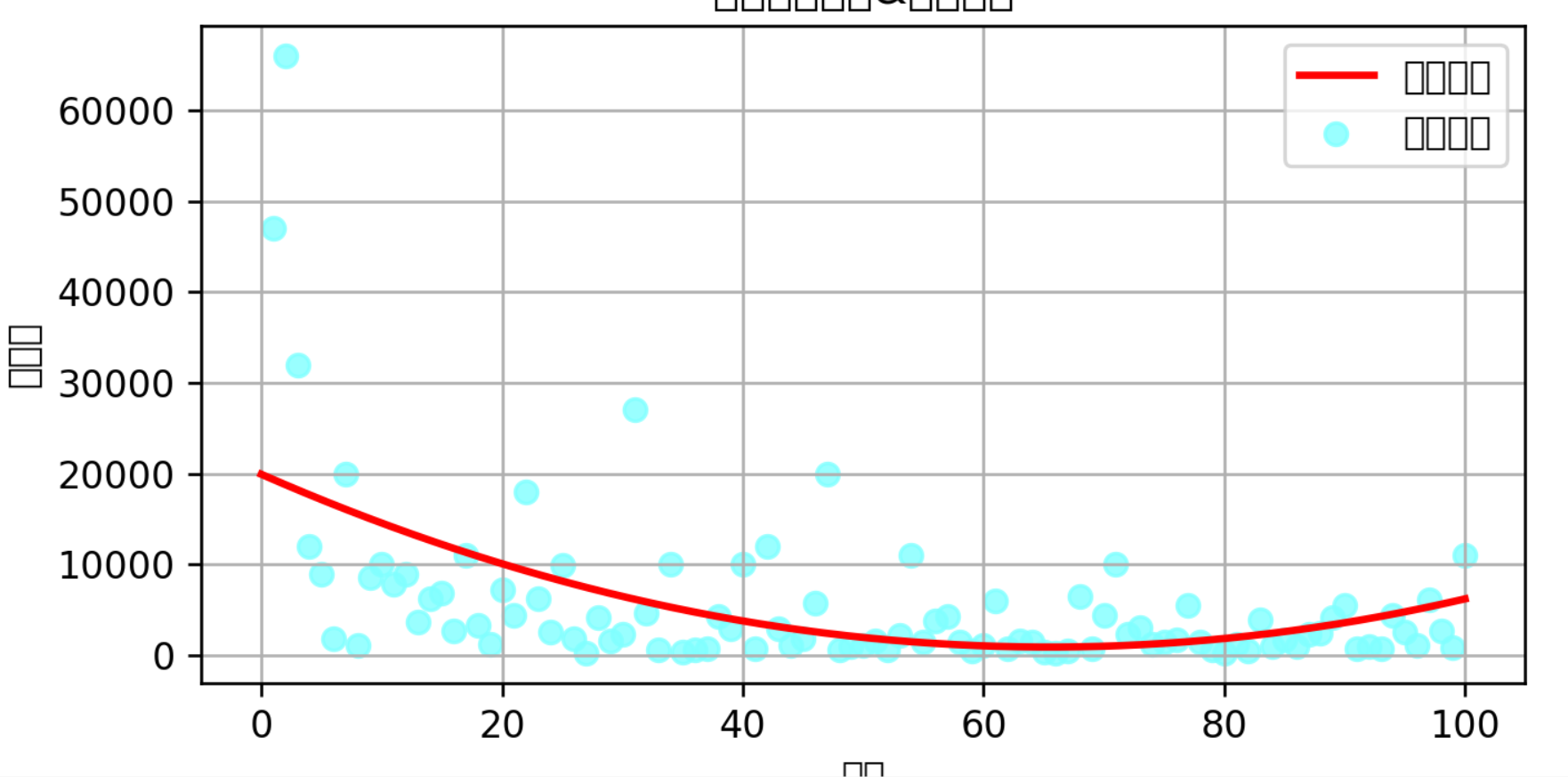
(2)排名与弹幕数的回归曲线和散点图
(3)综合得分与排名的回归曲线与散点图
以上为数据可视化
四、结论
1.经过对主题数据的分析与可视化,可以得到的结论为:
(1)一部番剧的综合排名与播放量、弹幕量、收藏量呈正相关
(2)播放量、弹幕量、收藏量决定了番剧的综合评分
2.小结
本次程序设计任务的主要难点在于对网页数据的爬取、对已爬取数据进行分类整理并清洗处理。在经过本次的程序设计实践后,我能够更加熟练的掌握若干python库的使用,对与网页结构的了解更加深刻。
五、源码
part1 数据爬取

import pandas as pd
import requests
import bs4
from bs4 import BeautifulSoup
from numpy.distutils.fcompiler import none
import xlwt
import numpy as np
import re
response = requests.get('https://www.bilibili.com/ranking/bangumi/13/0/7')
html = response.text
soup = BeautifulSoup(html, 'lxml')
def gettitle(soup): # 获取标题
getdata = soup.find_all(attrs={'class': 'title'})
data = []
for getdata in getdata:
data.append(getdata.text)
return data
def getscore(soup): # 获取评分
getdata = soup.find_all(attrs={'class': 'pts'})
data = []
for getdata in getdata:
data.append(getdata.text)
return data
def getplay(soup): # 获取播放量
getdata = soup.find_all(attrs={'class': 'data-box'})
data = []
for getdata in getdata:
data.append(getdata.text)
play = data[0:300:3]
return play
def getdanmu(soup): # 获取弹幕量
getdata = soup.find_all(attrs={'class': 'data-box'})
data = []
for getdata in getdata:
data.append(getdata.text)
play = data[1:300:3]
return play
def getfav(soup): # 获取收藏量
getdata = soup.find_all(attrs={'class': 'data-box'})
data = []
for getdata in getdata:
data.append(getdata.text)
play = data[2:300:3]
return play
title = gettitle(soup)
danmu = getdanmu(soup)
play = getplay(soup)
score = getscore(soup)
fav = getfav(soup)
df = pd.DataFrame.from_dict({'排名': range(1, 51), '标题': title, '弹幕': danmu, '播放': play, '综合得分': score, '收藏': fav},
orient='index')
df = df.T
df.to_csv('D:/bilibilidata.csv')
part2 数据可视化(由于长度过长只上传一例)
import pandas as pd
import requests
import bs4
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import numpy as np
import re
from scipy.optimize import leastsq
filename = 'D:/bilibilidata.xls'
colnames = ["ranking", "title", "danmu", "play", "score", "fav", ]
data = pd.read_csv(filename, skiprows=1, names=colnames)
ranking = data.ranking
play = data.play
danmu = data.danmu
score = data.score
plt.figure(dpi=240)
ranking = data.ranking
score = data.pts
plt.bar(ranking,score,color=[0,0,0.8,0.6])
plt.title("综合得分直方图")
plt.xlabel("排名")
plt.ylabel("综合得分")
plt.show()
def ft(p, x):
a, b, c = p
return a * (x ** 2) + (b * x) + c
def er_ft(p, x, y):
return ft(p, x) - y
play_np = np.array(play)
score_np = np.array(score)
danmu_np = np.array(danmu)
ranking_np = np.array(ranking)
p0 = np.array(2, 3, 4)
plt.figure(dpi=240)
plt.scatter(ranking, play, label=u'样本数据', color=[0, 0, 0.8, 0.8])
P = leastsq(er_ft, p0, args=(ranking_np, play_np))
a, b, c = P[0]
x = np.linspace(0, 100, 1000)
y = a * (x ** 2) + (b * x) + c
plt.plot(x, y, color="green", label=u"拟合直线", linewidth=2)
plt.title('播放量散点图&拟合直线')
plt.xlabel("排名")
plt.ylabel("播放量")
plt.legend()
plt.grid()
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号