

Dropout:随机失活
1. Dropout:是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃(使其暂时不工作),使一部分神经元工作,使另一部分神经元不工作;没有被删除的部分的参数得到更新,被删除的神经元参数保持之前的状态,此次训练过程中暂时不参加神经网络的计算,不更新权值,以达到避免过拟合,增加模型泛化的目的
△实质:让每个神经元的激活函数的输出值(激活函数值)以p的概率保持原样,以1-p的概率等于0
①在训练阶段,每个神经单元以概率p被保留,以1-p的概率被丢弃
②在测试阶段,每个神经单元都是存在的,激活函数输出值要乘以p,即[ f(W*x+b)]*p (有的博客说是权值矩阵W*p 不知道这两者有什么联系?)

一般p=0.5,使其激活函数值=0:
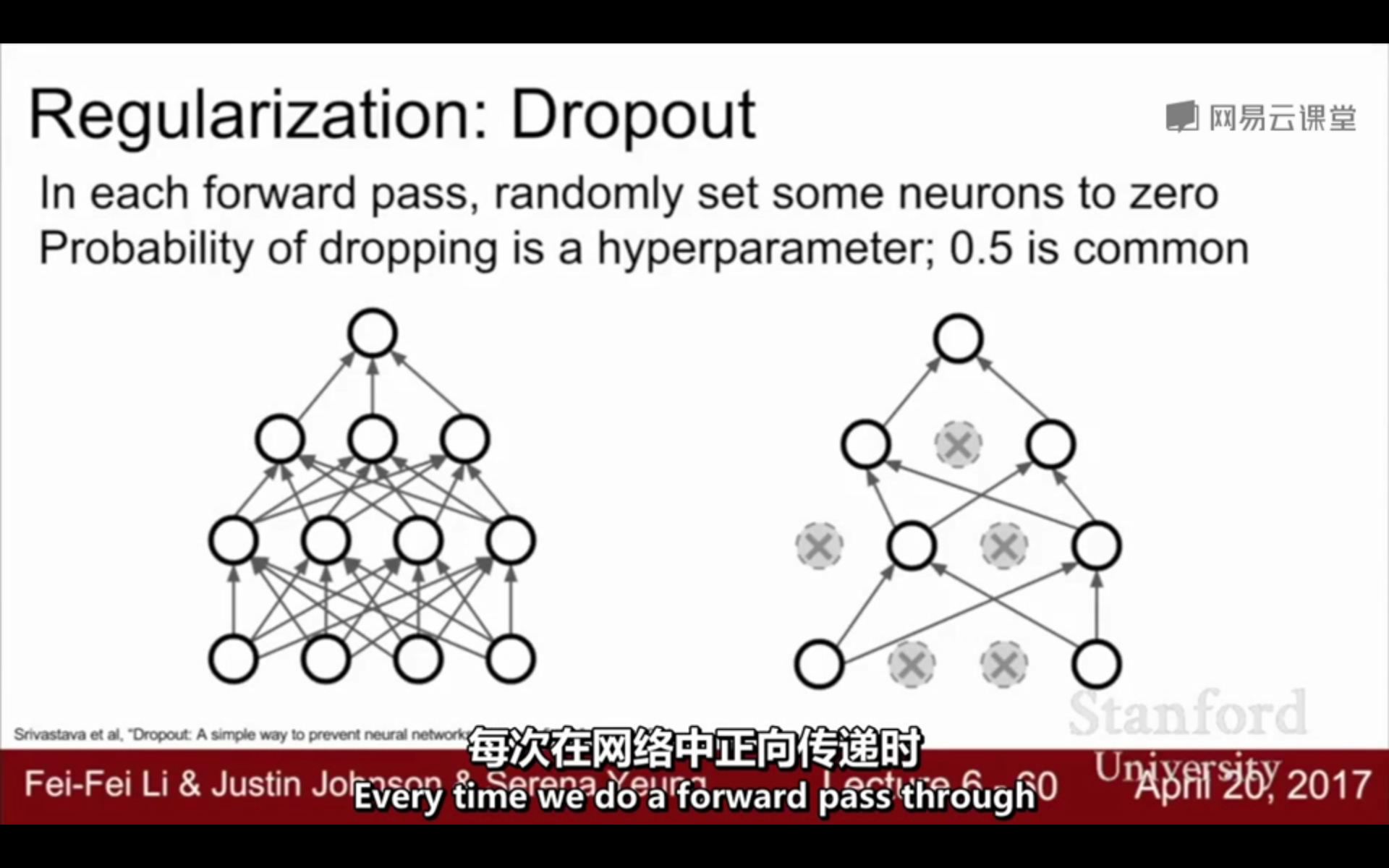
每次都是随机失活:
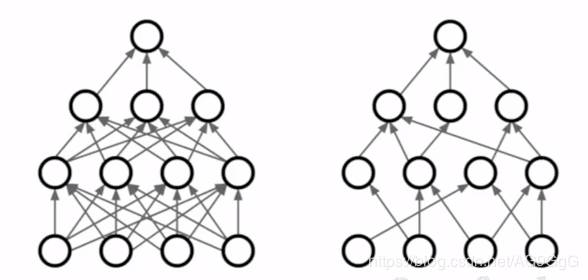
训练阶段以p的概率被保留;测试阶段(W*x + b)*p:

2. Dropout的运行:(训练阶段)一般p=0.5
①首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变
②将输入x通过修改后的网络进行前向传播,然后把得到的损失结果通过修改的网络反向传播;1个batch执行完这个过程后,在没有被删除的神经元上按照SGD更新对应的参数W、b
③然后继续重复这一过程,直到训练结束:
(1)恢复被删掉的神经元 -- 被删除的神经元保持原样,而没有被删除的神经元已经有所更新
(2)从隐藏层神经元中随机选择一个一半大小的子集临时删除掉,备份被删除神经元的参数
(3)对1个batch,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b)- 没有被删除的那一部分参数得到更新,删除的神经元参数保持之前的状态
虚线为部分临时被删除的神经元:
3. Dropout的运行:(测试阶段)
①在测试时,每个神经元的激活函数输出值乘以p:在测试时,不采用dropout,所有的神经元总是活跃的;为了让测试时的输出与训练时的数学期望输出相同,要调整测试时激活的范围,每个神经元的权重矩阵W乘以p以使得每个神经元 ->测试时的输出 = 训练时的期望输出
(1)在测试阶段要尽可能消除随机性,所以不dropout,因为采用随机失活会导致测试结果不稳定
(2)在训练阶段每个神经元以p的概率参与运算,以1-p的概率失活,假设输入=x,(不经过激活函数)那么训练阶段输出的数学期望:E = p * x +(1-p)*0 = p *x,而测试阶段的为x,所以要乘以p才相等

p乘以输出 -> 测试时的输出 = 训练时的期望输出:

4. Inverted dropout(反转dropout):为了减少测试时的运算,提高测试阶段的速度,不在测试阶段乘以p,而是在训练阶段除以p,来让二者的输出的数学期望相等
测试阶段不变,训练时除以p:

5. dropConnect:在训练时,不是将激活函数置0,而是随机将权重矩阵的一些值置为0
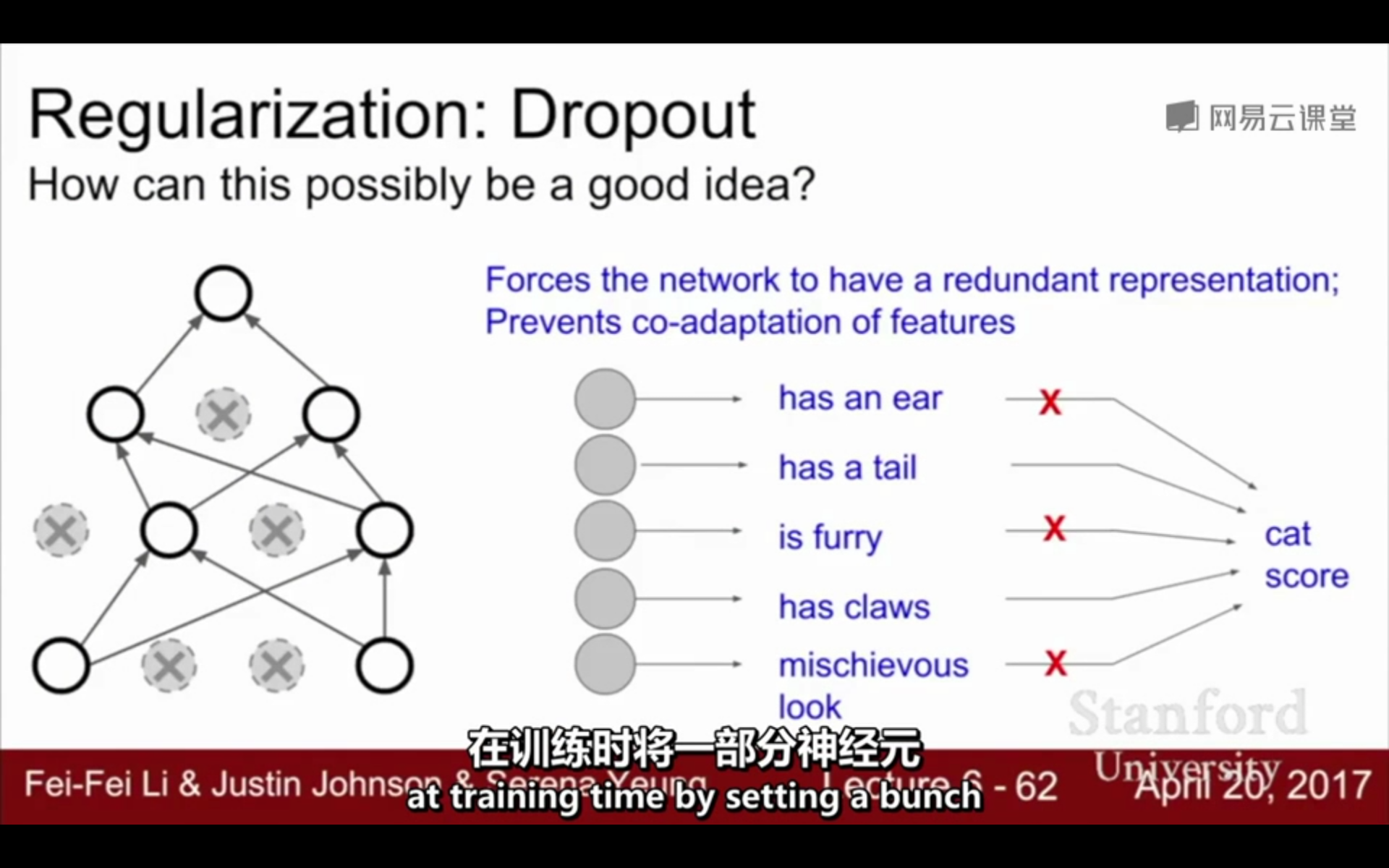
6. 正则化的共同点:
①在训练时增加随机噪声
②在测试时边缘化噪声


常见的regularization:

参考:
https://blog.csdn.net/program_developer/article/details/80737724
https://www.jianshu.com/p/cb9a7a7465b8
https://blog.csdn.net/AG9GgG/article/details/88668192

 浙公网安备 33010602011771号
浙公网安备 33010602011771号