MySQL语法
MySQL语法
MySQL的连接
mysql -u your_username -p -- 连接数据库
SHOW DATABASES; -- 列出所有可用的数据库
USE your_database; -- 选择要使用的数据库
SHOW TABLES; -- 列出所选数据库中的所有的表
EXIT/QUIT; -- 退出 mysql
MySQL 创建数据库
CREATE DATABASE 数据库名;
CREATE DATABASE [IF NOT EXISTS] database_name
[CHARACTER SET charset_name]
[COLLATE collation_name]; -- 创建数据库
-- 实例
-- 指定字符集和排序规则
CREATE DATABASE mydatabase
CHARACTER SET utf8mb4
COLLATE utf8mb4_general_ci;
MySQL 删除数据库
DROP DATABASE <database_name>; -- 直接删除数据库,不检查是否存在
MySQL 数据类型
-
数值类型
类型 大小 范围(有符号) 范围(无符号) 用途 TINYINT 1 Bytes (-128,127) (0,255) 小整数值 SMALLINT 2 Bytes (-32 768,32 767) (0,65 535) 大整数值 MEDIUMINT 3 Bytes (-8 388 608,8 388 607) (0,16 777 215) 大整数值 INT或INTEGER 4 Bytes (-2 147 483 648,2 147 483 647) (0,4 294 967 295) 大整数值 BIGINT 8 Bytes (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) (0,18 446 744 073 709 551 615) 极大整数值 FLOAT 4 Bytes (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) 0,(1.175 494 351 E-38,3.402 823 466 E+38) 单精度 浮点数值 DOUBLE 8 Bytes (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) 双精度 浮点数值 DECIMAL 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 依赖于M和D的值 依赖于M和D的值 小数值 -
日期和时间类型
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59' | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 |
| TIMESTAMP | 4 | '1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' UTC结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYY-MM-DD hh:mm:ss | 混合日期和时间值,时间戳 |
- 字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
- 枚举和集合类型
- ENUM: 枚举类型,用于存储单一值,可以选择一个预定义的集合。
- SET: 集合类型,用于存储多个值,可以选择多个预定义的集合。
MySQL创建数据表
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
);
-- 实例
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
birthdate DATE,
is_active BOOLEAN DEFAULT TRUE
);
MySQL 删除数据表
DROP TABLE table_name ; -- 直接删除表,不检查是否存在
或
DROP TABLE [IF EXISTS] table_name;
MySQL 插入数据
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
-- 实例
INSERT INTO users (username, email, birthdate, is_active)
VALUES ('test', 'test@runoob.com', '1990-01-01', true);
-- 如果你要插入所有列的数据,可以省略列名:
INSERT INTO users
VALUES (NULL,'test', 'test@runoob.com', '1990-01-01', true);
-- 这里,NULL 是用于自增长列的占位符,表示系统将为 id 列生成一个唯一的值
MySQL 查询数据
SELECT column1, column2, ...
FROM table_name
[WHERE condition]
[ORDER BY column_name [ASC | DESC]] -- 默认是升序(ASC)
[LIMIT number];
-- 实例
-- 选择所有列的所有行
SELECT * FROM users;
-- 选择特定列的所有行
SELECT username, email FROM users;
-- 添加 WHERE 子句,选择满足条件的行
SELECT * FROM users WHERE is_active = TRUE;
-- 添加 ORDER BY 子句,按照某列的升序排序
SELECT * FROM users ORDER BY birthdate;
-- 添加 ORDER BY 子句,按照某列的降序排序
SELECT * FROM users ORDER BY birthdate DESC;
-- 添加 LIMIT 子句,限制返回的行数
SELECT * FROM users LIMIT 10;
MySQL WHERE 子句
SELECT column1, column2, ...
FROM table_name
WHERE condition;
-- =:等号,检测两个值是否相等,如果相等返回true
-- <>, != : 不等于,检测两个值是否相等,如果不相等返回true
MySQL UPDATE 更新
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
-- 实例
UPDATE employees
SET salary = 60000
WHERE employee_id = 101;
MySQL DELETE 语句
DELETE FROM table_name
WHERE condition; -- 删除符合条件的行
DELETE FROM orders; -- 删除了 orders 表中的所有记录,但表结构保持不变。
MySQL LIKE 子句
LIKE 子句是在 MySQL 中用于在 WHERE 子句中进行模糊匹配的关键字。它通常与通配符一起使用,用于搜索符合某种模式的字符串。
LIKE 子句中使用百分号 %字符来表示任意字符,类似于UNIX或正则表达式中的星号 *****。
如果没有使用百分号 %, LIKE 子句与等号 = 的效果是一样的。
SELECT column1, column2, ...
FROM table_name
WHERE column_name LIKE pattern;
-- 实例
SELECT * FROM customers WHERE last_name LIKE 'S%'; -- 选择所有姓氏以 'S' 开头的客户
-- % 通配符表示零个或多个字符
-- _ 通配符表示一个字符
MySQL UNION操作符
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合,并去除重复的行。
SELECT column1, column2, ...
FROM table1
WHERE condition1
UNION -- 使用 UNION ALL 不去除重复行:
SELECT column1, column2, ...
FROM table2
WHERE condition2
[ORDER BY column1, column2, ...];
MySQL ORDER BY(排序) 语句
MySQL ORDER BY(排序) 语句可以按照一个或多个列的值进行升序(ASC)或降序(DESC)排序。
SELECT column1, column2, ...
FROM table_name
ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...;
-- 实例
SELECT first_name, last_name, salary
FROM employees
ORDER BY 3 DESC, 1 ASC; -- 使用数字表示列的位置
-- 使用表达式排序:
SELECT product_name, price * discount_rate AS discounted_price
FROM products
ORDER BY discounted_price DESC; -- 将选择产品表 products 中的产品名称和根据折扣率计算的折扣后价格,并按折扣后价格降序 DESC 排序。
-- 使用 NULLS FIRST 或 NULLS LAST 处理 NULL 值:
SELECT product_name, price
FROM products
ORDER BY price DESC NULLS LAST; -- 将选择产品表 products 中的产品名称和价格,并按价格降序 DESC 排序,将 NULL 值排在最后。
MySQL GROUP BY 语句
GROUP BY 语句根据一个或多个列对结果集进行分组。
SELECT column1, aggregate_function(column2)
FROM table_name
WHERE condition
GROUP BY column1;
-- 实例
SELECT customer_id, SUM(order_amount) AS total_amount
FROM orders
GROUP BY customer_id; -- 使用 GROUP BY customer_id 将结果按 customer_id 列分组,然后使用 SUM(order_amount) 计算每个组中 order_amount 列的总和。
-- 使用 WITH ROLLUP
-- WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
coalesce 语法:
select coalesce(a,b,c);
-- 参数说明:如果 a==null,则选择 b;如果 b==null,则选择 c;如果 a!=null,则选择 a;如果 a b c 都为 null ,则返回为 null(没意义)。
MySQL 连接的使用
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
-- INNER JOIN 返回两个表中满足连接条件的匹配行
SELECT column1, column2, ...
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name;
-- 实例
SELECT orders.order_id, customers.customer_name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id; -- 将选择 orders 表和 customers 表中满足连接条件的订单 ID 和客户名称
-- LEFT JOIN 返回左表的所有行,并包括右表中匹配的行,如果右表中没有匹配的行,将返回 NULL 值
SELECT column1, column2, ...
FROM table1
LEFT JOIN table2 ON table1.column_name = table2.column_name;
-- RIGHT JOIN 返回右表的所有行,并包括左表中匹配的行,如果左表中没有匹配的行,将返回 NULL 值
SELECT column1, column2, ...
FROM table1
RIGHT JOIN table2 ON table1.column_name = table2.column_name;
MySQL NULL 值处理
MySQL提供了三大运算符:
- IS NULL: 当列的值是 NULL,此运算符返回 true。
- IS NOT NULL: 当列的值不为 NULL, 运算符返回 true。
- <=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。
关于 NULL 的条件比较运算是比较特殊的。你不能使用 = NULL 或 != NULL 在列中查找 NULL 值 。
在 MySQL 中,NULL 值与任何其它值的比较(即使是 NULL)永远返回 NULL,即 NULL = NULL 返回 NULL 。
-- 1. 检查是否为 NULL:
-- 要检查某列是否为 NULL,可以使用 IS NULL 或 IS NOT NULL 条件。
SELECT * FROM employees WHERE department_id IS NULL;
-- 2. 使用 COALESCE 函数处理 NULL:
SELECT product_name, COALESCE(stock_quantity, 0) AS actual_quantity
FROM products; -- 如果 stock_quantity 列为 NULL,则 COALESCE 将返回 0。
-- 3. 使用 IFNULL 函数处理 NULL:
-- IFNULL 函数是 COALESCE 的 MySQL 特定版本,它接受两个参数,如果第一个参数为 NULL,则返回第二个参数。
SELECT product_name, IFNULL(stock_quantity, 0) AS actual_quantity
FROM products;
-- 4. NULL 排序:
-- 在使用 ORDER BY 子句进行排序时,NULL 值默认会被放在排序的最后。如果希望将 NULL 值放在最前面,可以使用 ORDER BY column_name ASC NULLS FIRST,反之使用 ORDER BY column_name DESC NULLS LAST。
SELECT product_name, price
FROM products
ORDER BY price ASC NULLS FIRST;
-- 5. 使用 <=> 操作符进行 NULL 比较:
-- <=> 操作符是 MySQL 中用于比较两个表达式是否相等的特殊操作符,对于 NULL 值的比较也会返回 TRUE。它可以用于处理 NULL 值的等值比较。
-- 6. 注意聚合函数对 NULL 的处理:
-- 在使用聚合函数(如 COUNT, SUM, AVG)时,它们会忽略 NULL 值,因此可能会得到不同于预期的结果。如果希望将 NULL 视为 0,可以使用 COALESCE 或 IFNULL。
SELECT AVG(COALESCE(salary, 0)) AS avg_salary FROM employees;
MySQL正则表达式
MySQL 中使用 REGEXP 和 RLIKE操作符来进行正则表达式匹配。
下表中的正则模式可应用于 REGEXP 操作符中。
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像 '[.\n]' 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 | |
| m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
正则表达式匹配的字符类
.:匹配任意单个字符。^:匹配字符串的开始。$:匹配字符串的结束。*:匹配零个或多个前面的元素。+:匹配一个或多个前面的元素。?:匹配零个或一个前面的元素。[abc]:匹配字符集中的任意一个字符。[^abc]:匹配除了字符集中的任意一个字符以外的字符。[a-z]:匹配范围内的任意一个小写字母。\d:匹配一个数字字符。\w:匹配一个字母数字字符(包括下划线)。\s:匹配一个空白字符
-- REGEXP 用于检查一个字符串是否匹配指定的正则表达式模式
SELECT column1, column2, ...
FROM table_name
WHERE column_name REGEXP 'pattern';
SELECT name FROM person_tbl WHERE name REGEXP '^st';-- 查找 name 字段中以 'st' 为开头的所有数据
SELECT name FROM person_tbl WHERE name REGEXP 'ok$'; -- 查找 name 字段中以 'ok' 为结尾的所有数据
SELECT name FROM person_tbl WHERE name REGEXP 'mar';-- 查找 name 字段中包含 'mar' 字符串的所有数据:
SELECT * FROM orders WHERE order_description REGEXP 'item[0-9]+';-- 选择订单表中描述中包含 "item" 后跟一个或多个数字的记录。
SELECT * FROM products WHERE product_name REGEXP BINARY 'apple';-- 使用 BINARY 关键字,使得匹配区分大小写:
MySQL 事务
- 在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
- 事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
- 事务用来管理 insert、update、delete 语句
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作。因此要显式地开启一个事务务须使用命令 BEGIN 或 START TRANSACTION,或者执行命令 SET AUTOCOMMIT=0,用来禁止使用当前会话的自动提交。
事务控制语句:
- BEGIN 或 START TRANSACTION 显式地开启一个事务;
- COMMIT 也可以使用 COMMIT WORK,不过二者是等价的。COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
- ROLLBACK 也可以使用 ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
- SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
- RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
- ROLLBACK TO identifier 把事务回滚到标记点;
- SET TRANSACTION 用来设置事务的隔离级别。InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
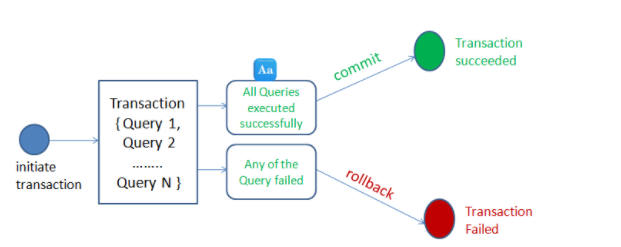
MYSQL 事务处理主要有两种方法:
1、用 BEGIN, ROLLBACK, COMMIT 来实现
- BEGIN 或 START TRANSACTION:开用于开始一个事务。
- ROLLBACK 事务回滚,取消之前的更改。
- COMMIT:事务确认,提交事务,使更改永久生效。
2、直接用 SET 来改变 MySQL 的自动提交模式:
- SET AUTOCOMMIT=0 禁止自动提交
- SET AUTOCOMMIT=1 开启自动提交
-- 开始事务
START TRANSACTION;
-- 执行一些SQL语句
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
-- 判断是否要提交还是回滚
IF (条件) THEN
COMMIT; -- 提交事务
ELSE
ROLLBACK; -- 回滚事务
END IF;
MySQL ALTER 命令
MySQL 的 ALTER 命令用于修改数据库、表和索引等对象的结构。
- 添加列
ALTER TABLE table_name
ADD COLUMN new_column_name datatype;
- 修改列的数据类型
ALTER TABLE TABLE_NAME
MODIFY COLUMN column_name new_datatype;
- 修改列名
ALTER TABLE table_name
CHANGE COLUMN old_column_name new_column_name datatype;
-- 表中的某个列的名字由 old_column_name 修改为 new_column_name,并且可以同时修改数据类型
- 删除列
ALTER TABLE table_name
DROP COLUMN column_name;
- 添加 PRIMARY KEY
ALTER TABLE table_name
ADD PRIMARY KEY (column_name);
- 添加 FOREIGN KEY
ALTER TABLE child_table
ADD CONSTRAINT fk_name
FOREIGN KEY (column_name)
REFERENCES parent_table (column_name);
- 修改表名
ALTER TABLE old_table_name
RENAME TO new_table_name;
MySQL 索引
MySQL 索引是一种数据结构,用于加快数据库查询的速度和性能。
索引分单列索引和组合索引:
- 单列索引,即一个索引只包含单个列,一个表可以有多个单列索引。
- 组合索引,即一个索引包含多个列。
创建索引
使用 CREATE INDEX 语句可以创建普通索引。
普通索引是最常见的索引类型,用于加速对表中数据的查询。
CREATE INDEX 的语法:
CREATE INDEX index_name
ON table_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
-- ASC和DESC(可选): 用于指定索引的排序顺序。默认情况下,索引以升序(ASC)排序。
- 修改表结构(添加索引)
ALTER TABLE 允许你修改表的结构,包括添加、修改或删除索引。
ALTER TABLE table_name
ADD INDEX index_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
- 创建表的时候直接指定
CREATE TABLE table_name (
column1 data_type,
column2 data_type,
...,
INDEX index_name (column1 [ASC|DESC], column2 [ASC|DESC], ...)
);
- 删除索引的语法
DROP INDEX index_name ON table_name;
-
唯一索引
在 MySQL 中,你可以使用 CREATE UNIQUE INDEX 语句来创建唯一索引。
唯一索引确保索引中的值是唯一的,不允许有重复值。
CREATE UNIQUE INDEX index_name
ON table_name (column1 [ASC|DESC], column2 [ASC|DESC], ...);
- 修改表结构添加索引
ALTER table mytable
ADD CONSTRAINT unique_constraint_name UNIQUE (column1, column2, ...);
-- UNIQUE (column1, column2, ...): 指定要索引的表列名。你可以指定一个或多个列作为索引的组合。这些列的数据类型通常是数值、文本或日期
- 显示索引信息
mysql> SHOW INDEX FROM table_name\G
........
-- \G: 格式化输出信息。
MySQL 临时表
临时表只在当前连接可见,当关闭连接时,MySQL 会自动删除表并释放所有空间。
在 MySQL 中,临时表是一种在当前会话中存在的表,它在会话结束时会自动被销毁。
-- 创建临时表
CREATE TEMPORARY TABLE temp_table_name (
column1 datatype,
column2 datatype,
...
);
-- 或者简写
CREATE TEMPORARY TABLE temp_table_name AS
SELECT column1, column2, ...
FROM source_table
WHERE condition;
-- 插入数据到临时表
INSERT INTO temp_table_name (column1, column2, ...)
VALUES (value1, value2, ...);
-- 查询临时表
SELECT * FROM temp_table_name;
-- 修改临时表
ALTER TABLE temp_table_name
ADD COLUMN new_column datatype;
-- 删除临时表
DROP TEMPORARY TABLE IF EXISTS temp_table_name;
-- 实例
-- 创建临时表
CREATE TEMPORARY TABLE temp_orders AS
SELECT * FROM orders WHERE order_date >= '2023-01-01';
-- 查询临时表
SELECT * FROM temp_orders;
-- 插入数据到临时表
INSERT INTO temp_orders (order_id, customer_id, order_date)
VALUES (1001, 1, '2023-01-05');
-- 查询临时表
SELECT * FROM temp_orders;
-- 删除临时表
DROP TEMPORARY TABLE IF EXISTS temp_orders;
MySQL 复制表
CREATE TABLE targetTable LIKE sourceTable;
INSERT INTO targetTable SELECT * FROM sourceTable;
-- 可以拷贝一个表中其中的一些字段:
CREATE TABLE newadmin AS
(
SELECT username, password FROM admin
)
MySQL 元数据
MySQL 元数据是关于数据库和其对象(如表、列、索引等)的信息。
以下是一些常用的 MySQL 元数据查询:
查看所有数据库:
SHOW DATABASES;
选择数据库:
USE database_name;
查看数据库中的所有表:
SHOW TABLES;
查看表的结构:
DESC table_name;
查看表的索引:
SHOW INDEX FROM table_name;
查看表的创建语句:
SHOW CREATE TABLE table_name;
查看表的行数:
SELECT COUNT(*) FROM table_name;
查看列的信息:
SELECT COLUMN_NAME, DATA_TYPE, IS_NULLABLE, COLUMN_KEY
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'your_database_name'
AND TABLE_NAME = 'your_table_name';
以上SQL 语句中的 'your_database_name' 和 'your_table_name' 分别是你的数据库名和表名。
查看外键信息:
SELECT
TABLE_NAME,
COLUMN_NAME,
CONSTRAINT_NAME,
REFERENCED_TABLE_NAME,
REFERENCED_COLUMN_NAME
FROM
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE
TABLE_SCHEMA = 'your_database_name'
AND TABLE_NAME = 'your_table_name'
AND REFERENCED_TABLE_NAME IS NOT NULL;
- 获取服务器元数据
以下命令语句可以在 MySQL 的命令提示符使用,也可以在脚本中 使用,如PHP脚本。
| 命令 | 描述 |
|---|---|
| SELECT VERSION( ) | 服务器版本信息 |
| SELECT DATABASE( ) | 当前数据库名 (或者返回空) |
| SELECT USER( ) | 当前用户名 |
| SHOW STATUS | 服务器状态 |
| SHOW VARIABLES | 服务器配置变量 |
MySQL 序列使用(AUTO_INCREMENT)
在 MySQL 中,序列是一种自增生成数字序列的对象,是一组整数 1、2、3、...,由于一张数据表只能有一个字段自增主键。
尽管 MySQL 本身并没有内建的序列类型,但可以使用 AUTO_INCREMENT 属性来模拟序列的行为,通常 AUTO_INCREMENT 属性用于指定表中某一列的自增性
CREATE TABLE example_table (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50)
);
-- 使用 LAST_INSERT_ID() 函数来获取刚刚插入的行的自增值:
SELECT LAST_INSERT_ID();
-- 需要获取表的当前自增值,可以使用以下语句:
SHOW TABLE STATUS LIKE 'example_table';
-- 重置序列
-- 删除了数据表中的多条记录,并希望对剩下数据的 AUTO_INCREMENT 列进行重新排列,那么你可以通过删除自增的列,然后重新添加来实现。
ALTER TABLE insect DROP id;
ALTER TABLE insect
ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
ADD PRIMARY KEY (id);
-- 设置序列的开始值
mysql> CREATE TABLE insect
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL,
-> date DATE NOT NULL,
-> origin VARCHAR(30) NOT NULL
)engine=innodb auto_increment=100 charset=utf8;
-- 或者在表创建成功后
mysql> ALTER TABLE t AUTO_INCREMENT = 100;
MySQL 处理重复数据
-
防止表中出现重复数据
你可以在 MySQL 数据表中设置指定的字段为 PRIMARY KEY(主键) 或者 UNIQUE(唯一) 索引来保证数据的唯一性。
-
设置表中字段 first_name,last_name 数据不能重复,你可以设置双主键模式来设置数据的唯一性, 如果你设置了双主键,那么那个键的默认值不能为 NULL,可设置为 NOT NUL
-
INSERT IGNORE INTO 与 INSERT INTO 的区别就是 INSERT IGNORE INTO 会忽略数据库中已经存在的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据
-- 统计重复数据
mysql> SELECT COUNT(*) as repetitions, last_name, first_name
-> FROM person_tbl
-> GROUP BY last_name, first_name
-> HAVING repetitions > 1;
-- 过滤重复数据
-- 读取不重复的数据可以在 SELECT 语句中使用 DISTINCT 关键字来过滤重复数据。
mysql> SELECT DISTINCT last_name, first_name
-> FROM person_tbl;
-- 使用 GROUP BY 来读取数据表中不重复的数据
mysql> SELECT last_name, first_name
-> FROM person_tbl
-> GROUP BY (last_name, first_name);
-- 删除重复数据
mysql> CREATE TABLE tmp SELECT last_name, first_name, sex FROM person_tbl GROUP BY (last_name, first_name, sex);
mysql> DROP TABLE person_tbl;
mysql> ALTER TABLE tmp RENAME TO person_tbl;
MySQL及SQL注入
如果您通过网页获取用户输入的数据并将其插入一个 MySQL 数据库,那么就有可能发生 SQL 注入安全的问题。
所谓 SQL 注入,就是通过把 SQL 命令插入到 Web 表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的 SQL 命令。
假设有一个登录系统,用户通过输入用户名和密码进行身份验证:
SELECT * FROM users WHERE username = 'input_username' AND password = 'input_password';
如果没有正确的输入验证和防范措施,攻击者可以输入类似于以下内容的用户名:
' OR '1'='1'; --
在这种情况下,SQL 查询会变成:
SELECT * FROM users WHERE username = '' OR '1'='1'; --' AND password = 'input_password';
这会使查询返回所有用户,因为 1=1 总是为真,注释符号 -- 用于注释掉原始查询的其余部分,以确保语法正确。
防范 SQL 注入:
- 使用参数化查询或预编译语句: 使用参数化查询(Prepared Statements)可以有效防止 SQL 注入,因为它们在执行查询之前将输入数据与查询语句分离。
- 输入验证和转义: 对用户输入进行适当的验证,并使用合适的转义函数(如
mysqli_real_escape_string)来处理输入,以防止恶意注入。 - 最小权限原则: 给予数据库用户最小的权限,确保它们只能执行必要的操作,以降低潜在的损害。
- 使用ORM框架: 使用对象关系映射(ORM)框架(如Hibernate、Sequelize)可以帮助抽象 SQL 查询,从而降低 SQL 注入的风险。
- 禁用错误消息显示: 在生产环境中,禁用显示详细的错误消息,以防止攻击者获取有关数据库结构的敏感信息。
防止SQL注入,我们需要注意以下几个要点:
- 1. 永远不要信任用户的输入 -- 对用户的输入进行校验,可以通过正则表达式,或限制长度,对单引号和双等进行转义等。
- 2. 永远不要使用动态拼装 SQL -- 可以使用参数化的 SQL 或者直接使用存储过程进行数据查询存取。
- 3. 永远不要使用管理员权限的数据库连接 -- 为每个应用使用单独的权限有限的数据库连接。
- 4. 不要把机密信息直接存放 -- 使用 hash 加密密码和敏感的信息。
- 5. 应用的异常信息应该给出尽可能少的提示 -- 最好使用自定义的错误信息对原始错误信息进行包装。
- 6. SQL 注入的检测方法一般采取辅助软件或网站平台来检测 -- 使用专门的漏洞扫描工具(如 sqlmap、Acunetix、Netsparker)对应用程序进行自动化的 SQL 注入检测。
MySQL导出数据
MySQL 中你可以使用 SELECT...INTO OUTFILE 语句来简单的导出数据到文本文件上。
SELECT column1, column2, ...
INTO OUTFILE 'file_path'
FROM your_table
WHERE your_conditions;
MySQL导入数据
-- 1. mysql 命令导入
mysql -u your_username -p -h your_host -P your_port -D your_database
-- 实例
mysql -uroot -p123456 < runoob.sql
-- 2、source 命令导入
mysql> create database abc; # 创建数据库
mysql> use abc; # 使用已创建的数据库
mysql> set names utf8; # 设置编码
mysql> source /home/abc/abc.sql # 导入备份数据库
-- 3、使用 LOAD DATA 导入数据
mysql> LOAD DATA LOCAL INFILE 'dump.txt' INTO TABLE mytbl;
MySQL 函数
MySQL 有很多内置的函数,以下列出了这些函数的说明。
https://www.runoob.com/mysql/mysql-functions.html
MySQL 运算符
- 算术运算符
| 运算符 | 作用 |
|---|---|
| + | 加法 |
| - | 减法 |
| * | 乘法 |
| / 或 DIV | 除法 |
| % 或 MOD | 取余 |
-- 加
select 1+2;
-- 减
select 3-2;
-- 乘
select 2*3;
-- 除
select 2/3;
-- 商
select 10 DIV 3;
-- 取余
select 10 MOD 4;
- 比较运算符
| 符号 | 描述 |
| = | 等于 |
| <>, != | 不等于 |
| > | 大于 |
| < | 小于 |
| <= | 小于等于 |
| >= | 大于等于 |
| BETWEEN | 在两值之间 |
| NOT BETWEEN | 不在两值之间 |
| IN | 在集合中 |
| NOT IN | 不在集合中 |
| <=> | 严格比较两个NULL值是否相等 |
| LIKE | 模糊匹配 |
| REGEXP 或 RLIKE | 正则式匹配 |
| IS NULL | 为空 |
| IS NOT NULL | 不为空 |
- 逻辑运算符
| 运算符号 | 作用 |
|---|---|
| NOT 或 ! | 逻辑非 |
| AND | 逻辑与 |
| OR | 逻辑或 |
| XOR | 逻辑异或 |
-
位运算符
运算符号 作用 & 按位与 | 按位或 ^ 按位异或 ! 取反 << 左移 >> 右移 -
运算符优先级
最低优先级为: :=
最高优先级为: !、BINARY、 COLLATE。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号