django ORM 相关梳理 - 复习回顾用
ORM 原理机优劣
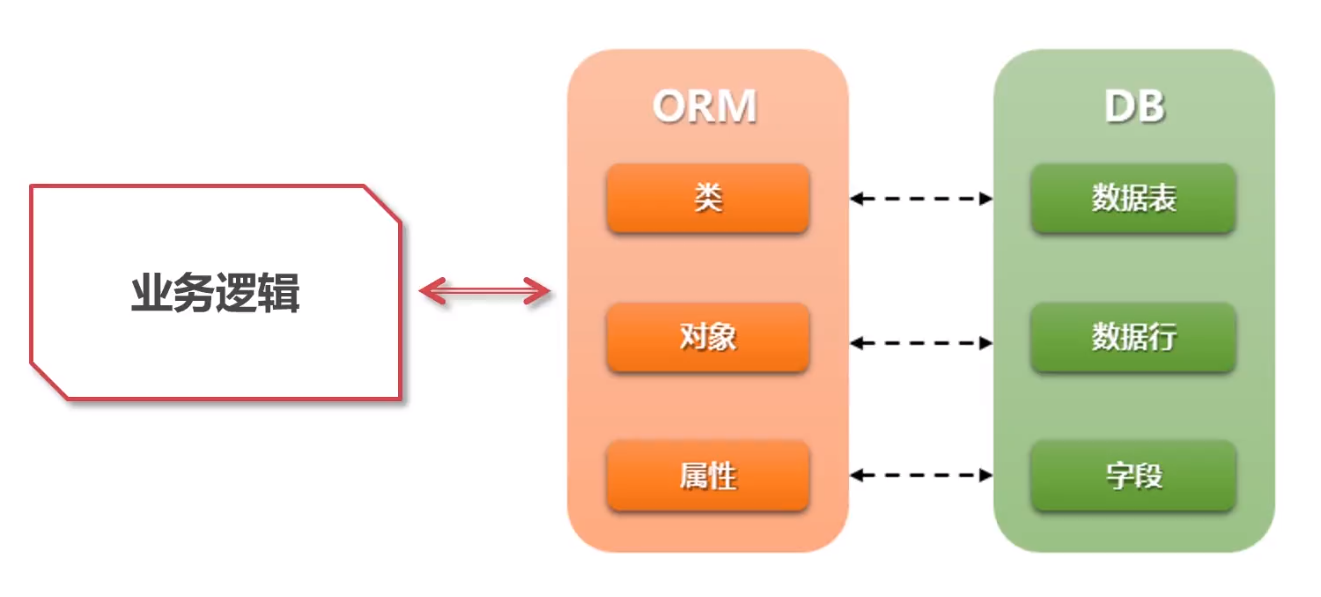
优势 提升开发效率, 兼容多种不同的 db 支持可以以相同的开发方式来处理
劣势 一定程度上降低执行效率
ORM 字段
单表字段
class Test(models.Model): _ = models.AutoField() # 自增长字段 _ = models.BigAutoField() # 允许范围更大的自增长字段 # 二进制字段 _ = models.BinaryField() # 布尔类型 _ = models.BooleanField() # 不允许为空的布尔字段 _ = models.NullBooleanField() # 允许为空的布尔字段 # 整型类型 不带 Positiv 表示可正可负, 带表示只能为正 _ = models.PositiveSmallIntegerField() # 正整数, 可存储字节大小为 5 _ = models.SmallIntegerField() # 整数, 可存储字节大小为 6 _ = models.PositiveIntegerField() # 正整数, 可存储字节大小为 10 _ = models.IntegerField() # 整数, 可存储字节大小为 11 _ = models.BigIntegerField() # 整数, 可存储字节大小为 20 # 字符串类型 _ = models.CharField() # 对应 mysql 中的 varchar _ = models.TextField() # 对应 langtext # 时间日期类型 _ = models.DateField() # 年月日 _ = models.DateTimeField() # 年月日时分秒 _ = models.DurationField() # 一段时间, 数据表是 int 类型, 底层用 timedelta 实现 # 浮点型 _ = models.FloatField() _ = models.DecimalField() # 需要指定整数位, 小数位 # 其他字段 _ = models.EmailField() # 邮箱 _ = models.ImageField() # 图片 _ = models.FileField() # 文件 _ = models.FilePathField() # 文件路基 _ = models.UUIDField() # uuid _ = models.URLField() # url _ = models.GenericIPAddressField() # ip 地址
关系型字段
class A(models.Model): _ = models.OneToOneField(Test) # 一对一 class B(models.Model): _ = models.ForeignKey(A) # 一对多 class C(models.Model): _ = models.ManyToManyField(A) # 多对多
ORM 字段参数
class A(models.Model): """1. 所有字段都有的参数""" _ = models.CharField( db_column="new_name", # 生成数据表后的字段名 primary_key=True, # 设置主键, 默认 False verbose_name="别名", # 设置别名, 或者备注 unique=True, # 唯一索引, 默认 False null=True, # 数据库允许为空. 默认为 False blank=True, # 前端 form 表单提交时允许为空, 默认为 False db_index=True, # 设置索引 help_text="", # 在表单中显示帮助信息 editable=False, # 不可更改. 默认为 True , 在 admin 和表单中都可以修改 ) """2. 部分字段独有的参数""" _ = models.CharField( max_length=100, # utf8 编码的长度 ) _ = models.DateField( unique_for_year=True, # 保证时间年份必须唯一 unique_for_month=True, # 保证时间月份必须唯一 unique_for_date=True, # 保证时间日期必须唯一 auto_now=True, # 更新当前记录时候的时间 auto_now_add=True # 新增记录的时间 ) _ = models.DecimalField( max_digits=4, # 总共有多少位数 decimal_places=2, # 小数点有多少位 # 38.25, 49.36 ) """3. 关系型字段的参数""" _ = models.ForeignKey( Test, related_name="name", # 反向关联的时候父表通过此字段查询子表的信息 on_delete="CASCADE" # 当外键所关联的字段被删除的时候, 要进行的操作方式 """ on_delete 可取值 CASCADE: 模拟 sql 中的 ON DELETE CASCADE 约束, 删除级联 (django 默认) PROTECT: 阻止删除操作, 弹出 ProtectedError 异常 SET_NULL: 将外键字段设为默认值. 只有当字段设置了 default 参数才可使用 DO_NOTHING: 什么都不做 SET(): 设置一个传递给 SET() 的值或者一个回调函数的返回值, 注意大小写 """ )
自关联
外键可以设置自己
设置方式有两种, 可以直接设置 'self' 也可以通常方式设置表名, 用第一种方式的时候需要设置 __str__ 方法
class A(models.Model): _ = models.CharField() pid2 = models.OneToOneField(A, on_delete="CASCADE") pid1 = models.OneToOneField("self", on_delete="CASCADE") def __str__(self): return self._
使用场景
自关联相关经常适用于商品表中用于不同商品分类, 或者地域表中不同的region zone
从而可以在单表中实现上下信息的查询
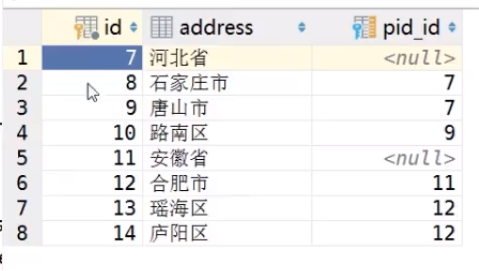 如此图效果
如此图效果
元数据 Meta
class C(models.Model): _ = models.CharField() _1 = models.CharField() _2 = models.CharField() class Meta: # 定义元数据 db_table = 'C__c' # 指定表名, 默认的表名为 app名字_C ordering = ['_1'] # 指定排序, 元祖列表形式, 可以指定多个 verbose_name = 'test' # 提供直观可读信息 verbose_name_plural = verbose_name # 通常用于设置 verbose_name 的复数 abstract = True # 类继承, 设置后生成数据表的时候不会生成, 主要用于给其他数据表提供基础字段 permissions = (('定义好的权限', '权限说明')) # 指定权限 unique_together = ('_1', '_2') # 联合唯一键 app_label = '' # 指定app, 如果app,没有加进去配置, 则需要此参数进行指定 db_tablespace = '' # 数据库表空间指定
模型关系示例
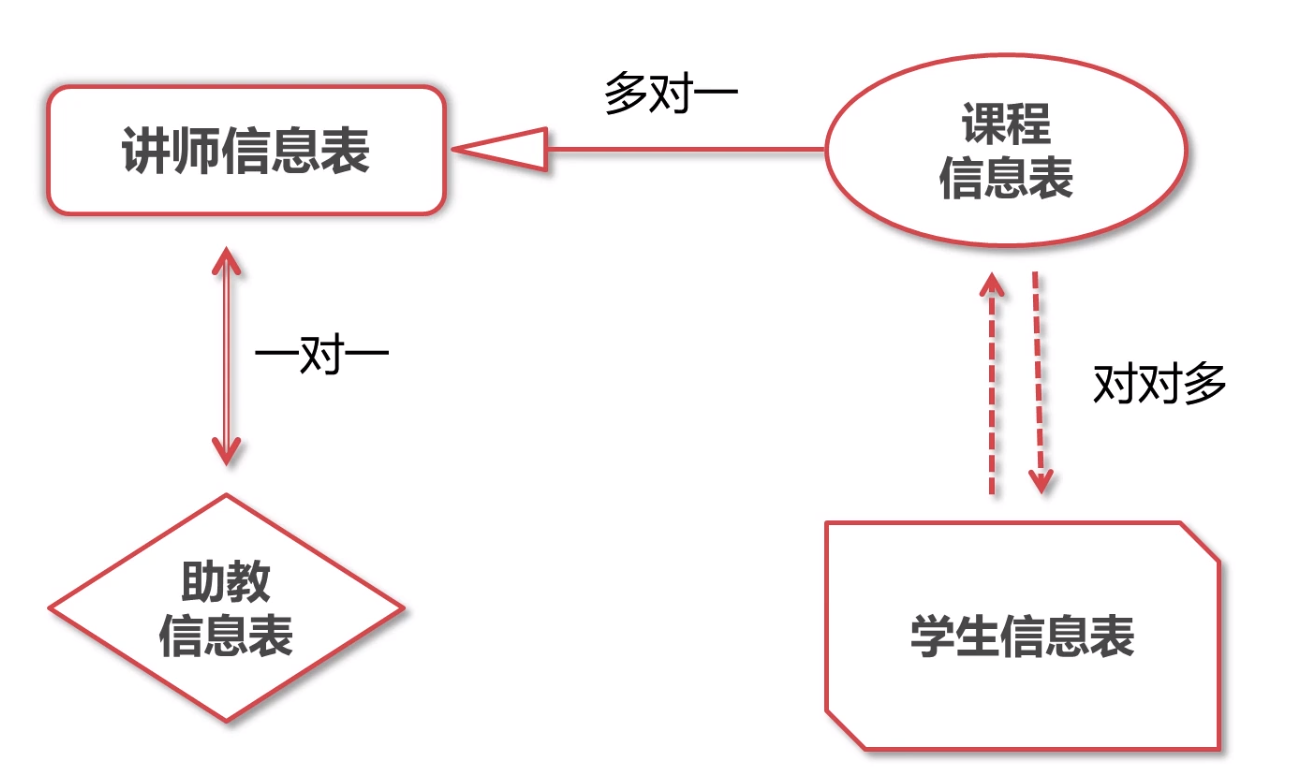
模型字段

数据导入 / 创建
django shell 操作
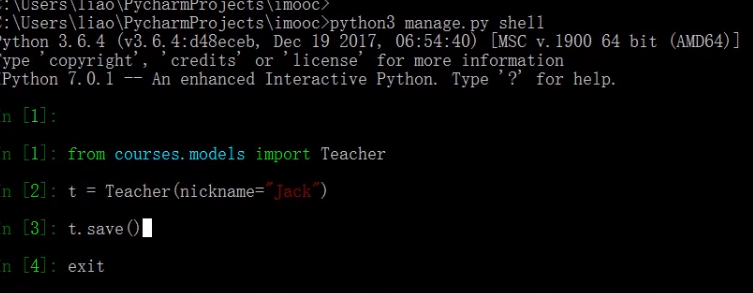
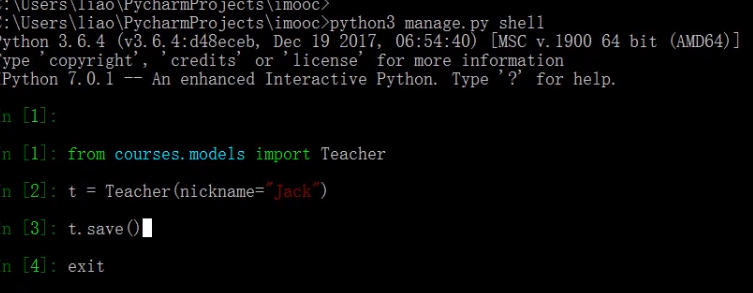
create 创建单条

bulk_create 批量创建

update_or_create 更新或创建
将 主键或者具备唯一特性的字段放在外面, 要设置的值放在 defaults 里面

get_or_create 查询或创建
查询到就返回, 查询不到就创建, 用法类似 update_or_create

add 外键添加 / _set.add 反向添加
这里课程表对学生来说是父表 (外键字段在学生表中)
因为字段在字表, 因此子表可以直接通过自己的字段查询到父表, 为正向查询
反之父表可以通过 related_name 或者这样 _set 进行反向操作

返回新的 QuerySet API
all / filter 查询

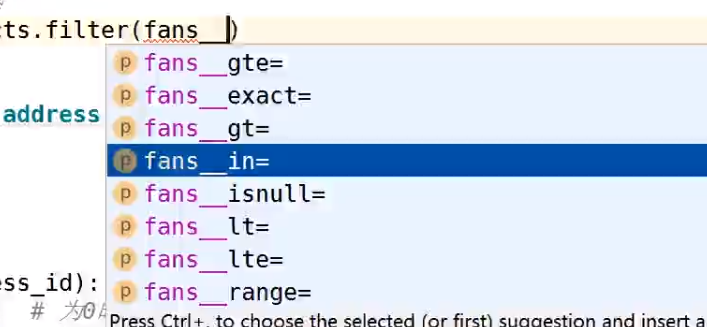
双下划线方法
数字类型
大于等于 / 完全等于/ 大于/ 在范围内 / 为空 / 小于 / 小于等于 / 在数值范围内
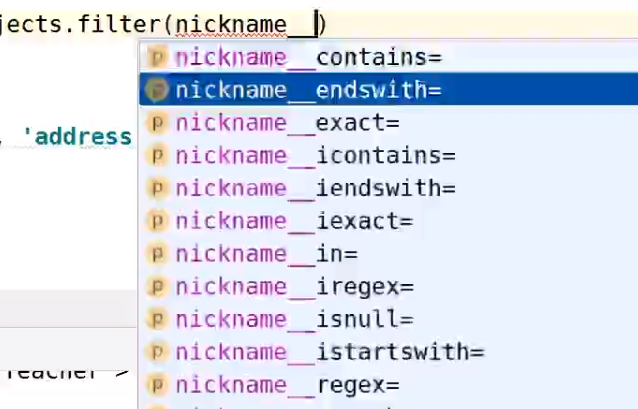
字符类型
包含 / 结尾为 / 等于 / 范围内 / 为空 / 开始为 / 正则表达式
前面加 i 表示大小写敏感
order_by, reverse 排序 / 切片 / 链式操作
切片支持索引切片, 排序使用 order_by 方法, 参数支持容器, 字段名前加 "-" 表示降序
链式操作支持多级进行数据处理

使用 reverse 方法的时候需要在模型元类中添加 ordering
查看执行的 原生 sql 语句
最后追加 .query 后 str 显示即可

exclude 排除
对结果的数据进行反向排除
distinct 去重
extra 别名
extra 表示对结果的数据设置别名替换, 类似 selet a_name as a .....

defer / only 选择
defer 排除某些字段, only 只查询某些字段
values , values_list
对返回的结果调整 kv 格式, falt 设置为 True 可以方便单个数据的时候进行合并


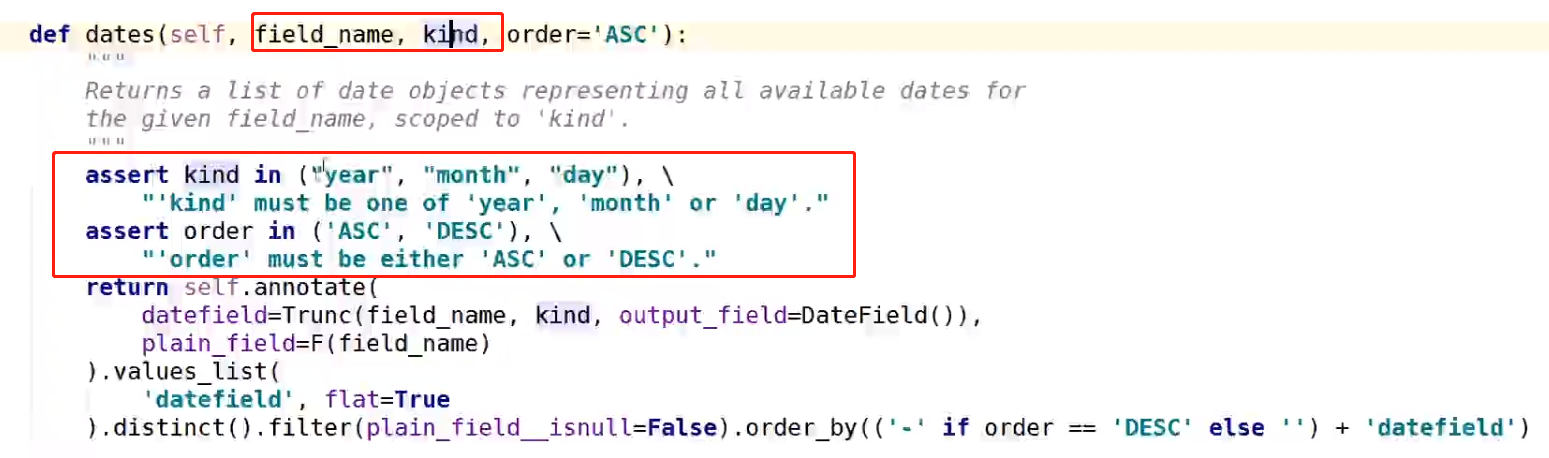
dates, datetimes 查询时间
时间类型查询的两个参数在源码中有相关的提示
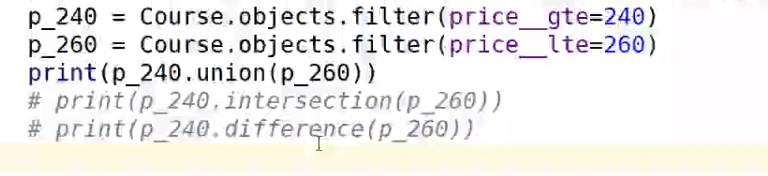
union / intersection / difference 交并补集
mysql 的引擎只支持并集

select_related / prefetch_related 查询优化
分表用一对一多对一优化, 以及一对多多对多优化
未进行优化前

设置查询优化指定外键字段
![]()
优化后

反向查询 _set
在父表要查询的子表名后进行追加 _set
![]()
若设置了 related_name 则可以通过设置值进行反向查询

使用时会自动提示

annotate 聚合
相关的聚合函数导入 from django.db.models import Sum, Avg, Max, Min, Count
![]()
![]()
row 原生 sql 执行
适用于某些特殊场景要求较为复杂的 sql 语句的使用
不返回新的 QuerySet API

使用 latest 和 earliest 时需要在元类中设置 get_latest_by 属性指定根据的字段

aggragate 和 annotate 的区别在于, annotate 一般和 values 结合使用对分组后的数据进行统计
而 aggragate 是对整个数据表的数据进行统计, 返回的是字典, 默认聚合的字段为字段名+双下划线方法名
![]()
![]()
F / Q 查询
F 用于对数据列进行操作, 比如直接进行相应的运算, 或者几个字段进行比较
![]()
![]()
Q 用于对数据进行进行与或非操作, 如果是于操作直接逗号也可以, 同时 Q 操作和于操作同时存在时
需要将 Q 写在前面

本文来自博客园,作者:羊驼之歌,转载请注明原文链接:https://www.cnblogs.com/shijieli/p/14659416.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号