

python函数
一、函数的结构与调用
1.函数的结构
定义:函数时组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
def 函数名():
函数体
def关键词开头,空格之后接函数名称和小括号(),最后还有一个':'。
def是固定的,不能变,他就是定义函数的关键字。
函数名:函数名只能包含字符串,下划线和数字且不能以数字开头。虽然函数名可以随便起,但是我们给函数起名字还是要尽量简短,并且要具有可描述性
函数作用:
-
使代码的可读性更好
-
减少代码的重复性,提高开发效率
2.函数的调用
使用函数名加小括号就可以调用了 写法:函数名() 这个时候函数的函数体才会被执行
二、函数的返回值
函数的返回值return,函数中一定要有return返回值才是完整的函数。如果你没有python定义函数的返回值,那么函数就是执行一个隐式的代码语句'return None',也就是函数都会有一个返回值,如果没有定义就执行隐性语句,定义的了就要返回定义的内容。
1.函数中遇到return,此函数结束不在执行
def shuai():
l1 = [1, 2, 3]
l2 = ['a', 'b']
return l1, l2
print('你真帅')
print(shuai()) # ([1, 2, 3], ['a', 'b'])
2.return会给函数的执行者返回值
当然,也可以返回多个值,如果返回多个值,是以元组的形式返回的。
def shuai():
l1 = [1, 2, 3]
l2 = ['a', 'b']
return l1, l2
print('你真帅')
a = shuai()
print(a) # ([1, 2, 3], ['a', 'b'])
总结一下:
1. 遇到return,函数结束,return下面的(函数内)的代码不会执行。
2. return会给函数的执行者返回值:
- 如果return后面什么都不写,或者函数中没有return,则返回的结果是None
- 如果return后面写了一个值,返回给调用者这个值
- 如果return后面写了多个结果,返回给调用者一个tuple(元组),调用者可以直接使用元组的结构获取多个变量
三、函数的参数
函数的参数可以从两个角度划分:
1. 形参:写在函数声明的位置的变量叫形参,形式上的一个完整。表示这个函数需要XXX
2. 实参:在函数调用的时候给函数传递的值
1.实参角度
1、位置参数
位置参数就是从左至右,实参与形参一一对应
def date(sex, age, hobby):
print(f'性别: {sex},年龄:{age},爱好:{hobby}')
date('女', '25~30', '唱歌') # 性别: 女,年龄:25~30,爱好:唱歌
def f(a,b):
c = a if a > b else b #当a>b就把a赋值给c,否则就把b赋值给c
return c
msg = f(5,7)
print(msg) # 7
2、关键字参数
我们不需要记住每个参数的位置. 只要记住每个参数的名字就可以了
def date(sex, age, hobby):
print(f'性别: {sex},年龄:{age},爱好:{hobby}')
date(sex='女', hobby='唱歌', age='25~30') # 性别: 女,年龄:25~30,爱好:唱歌
3、混合参数
两种参数混合着使用,在调用函数的时候即可以给出位置参数, 也可以指定关键字参数.混合参数一定要记住:关键字参数一定在位置参数后边
def date(sex, age, hobby):
print(f'性别: {sex},年龄:{age},爱好:{hobby}')
date('女', hobby='唱歌', age='25~30') # 性别: 女,年龄:25~30,爱好:唱歌
2.形参角度
1、位置参数
位置参数其实与实参角度的位置参数是一样的,就是按照位置从左至右,一一对应
def date(sex, age, hobby):
print(f'性别: {sex},年龄:{age},爱好:{hobby}')
date('女', '25~30', '唱歌') # 性别: 女,年龄:25~30,爱好:唱歌
2、默认值参数
在函数声明的时候, 就可以给出函数参数的默认值. 默认值参数一般是这个参数使用率较高,才会设置默认值参数,可以看看open函数的源码,mode=‘r’就是默认值参数.
def date(sex, hobby,age=18):
print(f'性别: {sex},年龄:{age},爱好:{hobby}')
date('女', '唱歌') # 性别: 女,年龄:18,爱好:唱歌
def date(sex, hobby,age=18):
print(f'性别: {sex},年龄:{age},爱好:{hobby}')
date('女', '唱歌',20) # 性别: 女,年龄:18,爱好:唱歌
# 默认参数输入新值则更改,否则显示默认值
3、动态参数
动态参数(魔法参数)分为两种:动态接受位置参数 *args,动态接收关键字参数**kwargs。
动态接收位置参数:*args
def date(*args):
print(f'{args}') # ('女', '唱歌', 18)
date('女', '唱歌', 18)
args就是一个普通的形参,但是如果你在args前面加一个* ,那么就拥有了特殊的意义:在python中除了表示乘号,他是有魔法的。*args这样设置形参,那么这个形参会将实参所有的位置参数接收,放置在一个元组中,并将这个元组赋值给args这个形参,这里起到魔法效果的是 * 而不是args,a也可以达到刚才效果,但是我们PEP8规范中规定就使用args,约定俗成的。
动态接收关键字参数: **kwargs
实参角度有位置参数和关键字参数两种,python中既然有*args可以接受所有的位置参数那么肯定也有一种参数接受所有的关键字参数,那么这个就是** kwargs,同理这个是具有魔法用法的,kwargs约定俗成使用作为形参。举例说明:** kwargs,是接受所有的关键字参数然后将其转换成一个字典赋值给kwargs这个形参。
def func(**kwargs):
print(kwargs)
func(name='世界', sex='男') # {'name': '世界', 'sex': '男'}
*的魔性用法
- 函数中分为打散和聚合
- 函数外可以处理剩余元素
函数的聚合和打散
#聚合
def travel(*args):
print(f'我要去{args}')
travel('杭州','北京','天津') # 我要去('杭州', '北京', '天津')
#打散
a = [1,2,3,4]
b = '世界'
def func(*args):
print(args)
func(a,b) # ([1, 2, 3, 4], '世界')
a = [1,2,3,4]
b = '世界'
def func(*args):
print(args)
func(*a,*b) # (1, 2, 3, 4, '世', '界')
a = {'name':'shijie', 'age':18}
b = '世界'
def func(*args, **kwargs):
print(args, kwargs)
func(*b,**a) # ('世', '界') {'name': 'shijie', 'age': 18}
*处理剩下的元素
# *除了在函数中可以聚合打散外,在函数外还可以灵活运用
# 之前讲过的分别赋值
a,b = (1,2)
print(a, b) # 1 2
# 其实还可以这么用:
a,*b = (1, 2, 3, 4,)
print(a, b) # 1 [2, 3, 4]
*rest,a,b = range(5)
print(rest, a, b) # [0, 1, 2] 3 4
print([1, 2, *[3, 4, 5]]) # [1, 2, 3, 4, 5]
4.形参的顺序
所有形参的顺序为:位置参数,*args,默认参数,**kwargs。
5.形参的第四种参数:仅限关键字参数
仅限关键字参数是python3x更新的新特性,他的位置要放在*args后面,**kwargs前面(如果有**kwargs),也就是默认参数的位置,它与默认参数的前后顺序无所谓,它只接受关键字传的参数:
# 这样传参是错误的,因为仅限关键字参数c只接受关键字参数
def func(a,b,*args,c):
print(a,b)
print(args)
func(1, 2, 3, 4, 5)
# 这样就正确了:
def func(a,b,*args,c):
print(a,b) # 1 2
print(args) # (3, 4)
print(c) # 5
func(1, 2, 3, 4, c=5)
这个仅限关键字参数从名字定义就可以看出他只能通过关键字参数传参,其实可以把它当成不设置默认值的默认参数而且必须要传参数,不传就报错。
所以形参角度的所有形参的最终顺序为:位置参数,*args,默认参数,仅限关键字参数,**kwargs。
四、名称空间,作用域
1.名称空间
在python解释器开始执行之后,就会在内存中开辟一个空间,每当遇到一个变量的时候,就把变量名和值之间的关系记录下来,但是当遇到函数定义的时候,解释器只是把函数名读入内存,表示这个函数存在了,至于函数内部的变量和逻辑,解释器是不关心的。也就是说一开始的时候函数只是加载进来,仅此而已,只有当函数被调用和访问的时候,解释器才会根据函数内部声明的变量来进行开辟变量的内部空间。随着函数执行完毕,这些函数内部变量占用的空间也会随着函数执行完毕而被清空。
"存放名字与值的关系"的空间叫命名空间。
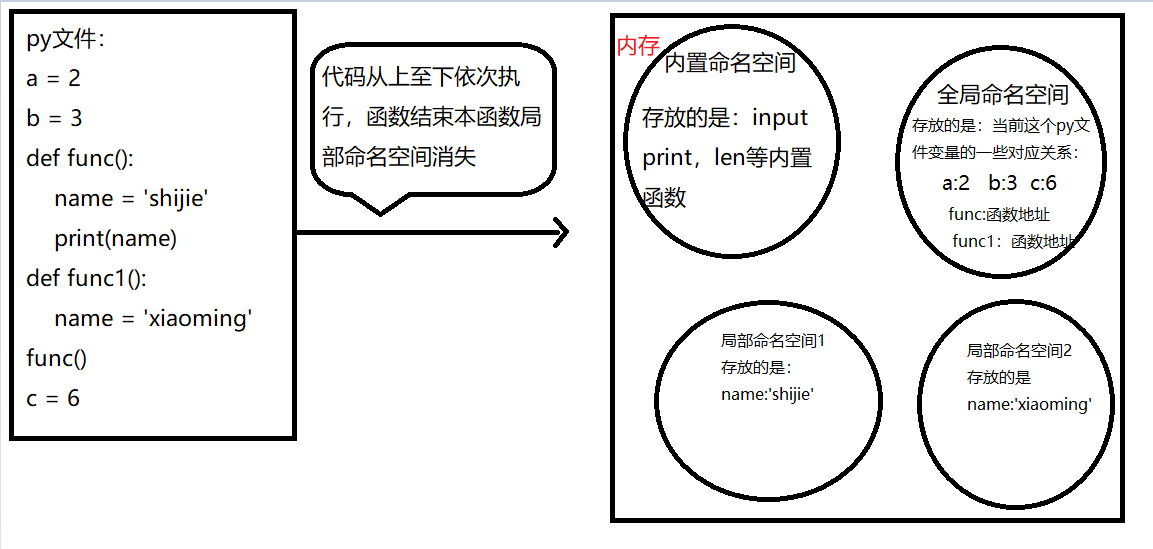 ![]
![]
全局命名空间:在py文件中,函数外声明的变量都属于全局命名空间
局部命名空间:在函数中声明的变量会放在局部命名空间
内置命名空间:存放python解释器为我们提供的名字,list,int,print的内置命名空间
这三个空间的加载顺序为:内置命名空间(程序运行伊始加载)->全局命名空间(程序运行中:从上到下加载)->局部命名空间(程序运行中:调用时才加载)。
2.作用域
作用域就是作用范围, 按照生效范围来看分为全局作用域和局部作用域。
全局作用域: 包含内置命名空间和全局命名空间. 在整个文件的任何位置都可以使用(遵循 从上到下逐⾏执行).
局部作用域: 在函数内部可以使用.
作⽤域命名空间:
1. 全局作用域: 全局命名空间 + 内置命名空间
2. 局部作⽤域: 局部命名空间
1、内置函数globals(),locals()
globals(): 以字典的形式返回全局作用域所有的变量对应关系。
locals(): 以字典的形式返回当前作用域的变量的对应关系。
# 在全局作用域下打印,则他们获取的都是全局作用域的所有的内容。
a = 2
b = 3
print(globals())
print(locals())
# 这两个值是一样的
'''
{'__name__': '__main__', '__doc__': None, '__package__': None,
'__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001806E50C0B8>,
'__spec__': None, '__annotations__': {},
'__builtins__': <module 'builtins' (built-in)>,
'__file__': 'D:/lnh.python/py project/teaching_show/day09~day15/function.py',
'__cached__': None, 'a': 2, 'b': 3}
'''
# 在局部作用域中打印。
a = 2
b = 3
def foo():
c = 3
print(globals()) # 和上面一样,还是全局作用域的内容
print(locals()) # {'c': 3}
foo()
2.global
局部作用域对全局作用域的变量(此变量只能是不可变的数据类型)只能进行引用,而不能进行改变,只要改变就会报错,但是有些时候,在程序中会遇到局部作用域去改变全局作用域的一些变量的需求,这就得用到关键字global:
global第一个功能:在局部作用域中可以更改全局作用域的变量。
count = 1
def func():
global count
count = 2
func()
print(count)
所以global关键字有两个作用:
- 声明一个全局变量
- 在局部作用域想要对全局作用域的全局变量进行修改时,需要用到global(限于字符串,数字)。
五、内置函数
format
# format()
# 第一种
a = "{}{}{}".format('shijie','最','帅')
print(a)
# 第二种
a = "{0}{1}{0}".format('shijie','最','帅')
print(a)
# 第三种
a = "{name}{age}{hobby}".format(name='shijie', age=18,hobby='paobu')
print(a)
# 第四种字典
a = {'name':'dcs', 'url':'www.duoceshi.com'}
b = "{name},{url}".format(**a)
print(b)
# 第五种列表
a = ['dcs', 'www.duoceshi.com']
b = "{0[0]}, {0[1]}".format(a)
print(b)
zip
用于将可迭代对象作为参数,将对象中的对应元素打包成一个个元组,如果可迭代的对象元素不一致时,与最短可迭代对象的长度相同
a = ['a','b','c']
b = [1,2,3]
c = zip(a,b)
print(list(c)) #[('a',1),('b',2),('c',3)]
print(dict(c)) # {'a':1,'b':2,'c':3}
# 解压*
a,b=zip(*zip(a,b))
print(a,b) # ('a', 'b', 'c') (1, 2, 3)
文件操作
用于打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写
# 第一种用法open(file, mode='r', encoding=None)
#file 文件路径
#mode 操作方式
#encoding 编码方式
#1. 打开文件,得到文件句柄并赋值给一个变量
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r
#2. 通过句柄对文件进行操作
data=f.read()
#3. 关闭文件
f.close()
#路径问题
#路径里面的\,如\D就有了特殊意义,其实跟\t,\n,换行符一样,所以针对这种情况,可以有两种解决方式
# 第一种
#'c:\\Users\\11.txt' 凡是路径会发生化学反应的地方多加一个\这样就是前面的\对后面的\进行转译,告诉计算机这个只是单纯的表示\路径而已
# 第二种
# 前边加r r'c:\Users\11.txt'
1.文件的读
#r模式
#以只读方式打开文件,文件的指针将会放在文件的开头。是文件操作最常用的模式,也是默认模式,如果一个文件不设置mode,那么默认使用r模式操作文件
f = open('haha.txt','r',encoding='utf-8')
msg = f.read()
f.close()
print(msg)
# 结果杭州
天津
上海
北京
广州
# read() 将文件中的内容全部读取出来;弊端 如果文件很大就会非常的占用内存,容易导致内存奔溃.
# read()读取的时候指定读取到什么位置 在r模式下,n按照字符读取
f = open('haha.txt','r',encoding='utf-8')
msg = f.read(2)
f.close()
print(msg) # 杭州
#readline() 读取每次只读取一行,注意点:readline()读取出来的数据在后面都有一个\n 解决这个问题只需要在我们读取出来的文件后边加一个strip()就OK了
# 如msg1 = f.readline().strip()
f = open('haha.txt','r',encoding='utf-8')
msg1 = f.readline()
msg2 = f.readline()
msg3 = f.readline()
f.close()
print(msg1)
print(msg2)
print(msg3)
# 结果
杭州
天津
上海
# readlines() 返回一个列表,列表里面每个元素是原文件的每一行,如果文件很大,占内存,容易崩盘。
f = open('haha.txt','r',encoding='utf-8')
msg1 = f.readlines()
f.close()
print(msg1)
# 结果 ['杭州\n', '天津\n', '上海\n', '北京\n', '广州']
# 上面这四种都不太好,因为如果文件较大,他们很容易撑爆内存
#for循环
f = open('haha.txt','r',encoding='utf-8')
# for i in f:
# print(i)
print(f.readline())
print(f.readline())
print(f.readline())
print(f.readline())
f.close()
#rb模式 rb模式:以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。
#并且如果你要是带有b的模式操作文件,那么不用声明编码方式。
2.文件写
第二类就是写,就是在文件中写入内容。这里也有四种文件分类主要四种模式:w,wb,w+,w+b
#如果文件不存在,利用w模式操作文件,那么它会先创建文件,然后写入内容.
#如果文件存在,利用w模式操作文件,先清空原文件内容,在写入新内容。
#wb模式:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,
#并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如:图片,音频,视频等。
#write写入文档,把之前文档覆盖
f = open('haha.txt','w',encoding='utf-8')
f.write('多测师大佬')
f.close()
#writelines写入文档,把之前文档覆盖
3.文件的追加
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。有四种文件分类主要四种模式:a,ab,a+,a+b
#1. 打开文件的模式有(默认为文本模式):
r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
w,只写模式【不可读;不存在则创建;存在则清空内容】
a, 只追加写模式【不可读;不存在则创建;存在则只追加内容】
#2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)
rb
wb
ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
#3,‘+’模式(就是增加了一个功能)
r+, 读写【可读,可写】
w+,写读【可写,可读】
a+, 写读【可写,可读】
#4,以bytes类型操作的读写,写读,写读模式
r+b, 读写【可读,可写】
w+b,写读【可写,可读】
a+b, 写读【可写,可读】
注意:如果你在读写模式下,先写后读,那么文件就会出问题,因为默认光标是在文件的最开始,你要是先写,则写入的内容会讲原内容覆盖掉,直到覆盖到你写完的内容,然后在后面开始读取。
文件打开的另一种方式
with open() as…
# 1,利用with上下文管理这种方式,它会自动关闭文件句柄。
with open('t1',encoding='utf-8') as f1:
f1.read()
# 2,一个with 语句可以操作多个文件,产生多个文件句柄。
with open('t1',encoding='utf-8') as f1,
open('Test', encoding='utf-8', mode = 'w') as f2:
f1.read()
f2.write('老男孩')
这里要注意一个问题,虽然使用with语句方式打开文件,不用你手动关闭文件句柄,比较省事儿,但是依靠其自动关闭文件句柄,是有一段时间的,这个时间不固定,所以这里就会产生问题,如果你在with语句中通过r模式打开t1文件,那么你在下面又以a模式打开t1文件,此时有可能你第二次打开t1文件时,第一次的文件句柄还没有关闭掉,可能就会出现错误,他的解决方式只能在你第二次打开此文件前,手动关闭上一个文件句柄。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号