-
python关于mysql的API-----pymysql模块
-
事务
-
索引
一、pymsql模块
pymsql是python中操作MYSQL的模块
1、模块的安装
pip install pymysql / 也可以用pycharm自带的编译器内置安装
2、执行sql语句
1 # _*_ encoding:utf-8 _*_ 2 __author__ = 'listen' 3 __date__ = '2018/12/13 21:51' 4 import pymysql 5 conn=pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='',db='s3') 6 # cursor=conn.cursor() #默认 元组形式 7 cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #取数据字典的形式 知道取出来的东西是什么了 8 # sql="""CREATE TABLE test( 9 # id int primary key auto_increment, 10 # name varchar(25), 11 # age int 12 # ) 13 14 # """ 15 # cursor.execute(sql) 16 #添加数据 17 # row_affected=cursor.execute('create table hello(id int primary key ,name varchar(20))') 18 # row_affected=cursor.execute("insert into hello(id,name) values (1,'alex'),(2,'listen'),(3,'chunlv'),(4,'jia'),(5,'jian')") 19 # row_affcted=cursor.execute('update hello set name="cheng" where id=5 ') 20 21 #查询数据 22 row_affected=cursor.execute('select * from hello') 23 # print(row_affected) #5 打印的是5 24 one=cursor.fetchone() #取一行数据 25 # many=cursor.fetchmany(3) #取多行,可以自定义参数 26 # all=cursor.fetchall() #所有的 27 print(one) #(1, 'alex') 28 # print(many) #((2, 'listen'), (3, 'chunlv'), (4, 'jia')) 29 # print(all) #((5, 'cheng'),) 若前面有取数据接着把后面所有数据取出来,若前面没做什么操作,直接把所有数据取出来((1, 'alex'), (2, 'listen'), (3, 'chunlv'), (4, 'jia'), (5, 'cheng')) 30 31 #scroll 光标的位置移动 32 print(cursor.fetchone()) 33 # cursor.scroll(1,mode='relative') #正数是向下取,负数向上取 取相对位置 34 # cursor.scroll(-1,mode='relative') 35 cursor.scroll(1,mode='absolute') #取绝对位置 36 print(cursor.fetchone()) 37 38 conn.commit() #针对于数据的提交 创建表不需要commit数据库中就会创建一个表 插入一条数据是必须提交了才会放到数据库里面去 39 cursor.close() 40 conn.close()
二、事务
事务指逻辑上的一组操作,组成这组操作的各个单元,要不全部成功,要不全部失败。
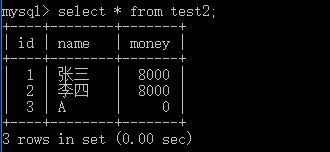
转账实例
数据库开启事务的命令:
start transaction 开启事务
Rollback 回滚事务,即撤销指定sql的语句(只能回退insert、update、delete语句),回滚到上一次commit的位置
commit 提交事务,提交未存储的事务
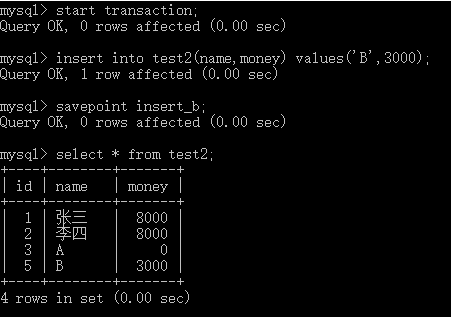
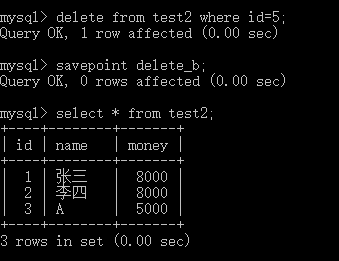
savepoint保留点,事务处理中设置的临时占位符,可以对它发布回退(与整个事务回退不同),回退到自己没出错的地方,不用全部回退(设置一个savepoint可以实现)。
1、保留点的实例:





2、python中调用数据库启动事务的方式
1 # _*_ encoding:utf-8 _*_ 2 __author__ = 'listen' 3 __date__ = '2018/12/15 10:07' 4 import pymysql 5 conn=pymysql.connect(host='127.0.0.1',port=3306,user='root',passwd='',db='s3') 6 cursor=conn.cursor() 7 # sql="""create table bank(id int primary key auto_increment, 8 # name varchar(25), 9 # money double 10 # ) 11 # """ 12 # cursor.execute(sql) 13 # insertsql = "insert into bank(name,money) values ('listen',6000)" 14 # insertsql1 = "insert into bank(name,money) values ('jia',6000)" 15 # cursor.execute(insertsql1) 16 try: 17 insertsql2="update bank set money=money-2000 where name='listen' " 18 insertsql3="update bank set money=money+2000 where name='jia' " 19 cursor=conn.cursor() 20 cursor.execute(insertsql2) 21 raise Exception #要么全部成功 要么全部失败 回滚 22 cursor.execute(insertsql3) 23 cursor.close() 24 conn.commit() 25 except Exception as e: 26 conn.rollback() 27 conn.commit() 28 29 30 #针对于数据的提交 创建表不需要commit数据库中就会创建一个表 插入一条数据是必须提交了才会放到数据库里面去 31 cursor.close() 32 conn.close()
事务的特性
1、原子性
原子是一个不可分割的单位,正如事务是一个不可分割的工作单位,事务中的操作要不都发生,要不都不发生。
2、一致性
事务前后的数据完整性必须保持一执。在事务执行之前的数据库是符合数据完整性约束的,无论事务是否执行成功,事务结束后的数据库中的数据也应该符合完整性约束的。在某一时间点,如果数据库中所有的记录都能保证满足当前数据库中的所有约束,则可以睡当前的数据库是符合数据库完整性约束的。
比如说:删除部门表事前应该删掉关联的员工(建立外键),如果数据库服务器发生错误,有一个员工没有删掉,那么此员工的部门表已经删除,那么就不符合完整性约束,这样性能的数据库就low爆了。
3、隔离性
事务的隔离性是指多个用户并发访问数据库时,一个用户的事务不能被其他用户的事务所干扰,多个并发事务之间的数据库要相互隔离。
4、持久性
持久性是指一个事务一旦被提交,它对数据库中的数据的改变就是持久性的,接下来即使数据库发生故障也比应该对其产生任何影响。
针对3、隔离性详解:
将数据库设计为串行化程的数据库,让一张表在同一个时间内只能有一个线程来操作。如果将数据库设计为这样,效率太低了。所以数据库的设计者没有直接将数据设计为串行化,而为数据库提供多个隔离级别选项,使数据库的使用者可以根据使用情况自定义需要什么隔离级别。
不考虑隔离性可能出现的问题:
脏读:
一个事务的数据读到了另一个事务未提交的数据,这是特别危险的,要尽力防止。
1 --一个事务读取到了另一个事务未提交的数据,这是特别危险的,要尽力防止。 2 a 1000 3 b 1000 4 a: 5 start transaction; 6 update set money=money+100 where name=b; 7 b: 8 start transaction; 9 select * from account where name=b;--1100 10 commit; 11 a: 12 rollback; 13 b: start transaction; 14 select * from account where name=b;--1000
不可重复读
1 --在一个事务内读取表中的某一行数据,多次读取结果不同。(一个事务读取到了另一个事务已经提交 2 -- 的数据--增加记录、删除记录、修改记录),在某写情况下并不是问题,在另一些情况下就是问题。 3 4 a: 5 start transaction; 6 select 活期账户 from account where name=b;--1000 活期账户:1000 7 select 定期账户 from account where name=b;--1000 定期账户:1000 8 select 固定资产 from account where name=b;--1000 固定资产:1000 9 ------------------------------ 10 b: 11 start transaction; 12 update set money=0 where name=b; 13 commit; 14 ------------------------------ 15 select 活期+定期+固定 from account where name=b; --2000 总资产: 2000
虚读
1 是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。(一个事务读取到了另一个事务已经提交的数据---增加记录、删除记录),在某写情况下并不是问题,在另一些情况下就是问题。 2 3 b 1000 4 c 2000 5 d 3000 6 a: 7 start transaction 8 select sum(money) from account;---3000 3000 9 ------------------- 10 d:start transaction; 11 insert into account values(d,3000); 12 commit; 13 ------------------- 14 select count(*)from account;---3 3 15 3000/3 = 1000 1000
四个隔离级别:
Serializable:可避免脏读、不可重复读、虚读情况的发生。(串行化)
Repeatable read:可避免脏读、不可重复读情况的发生。(可重复读)不可以避免虚读
Read committed:可避免脏读情况发生(读已提交)
Read uncommitted:最低级别,以上情况均无法保证。(读未提交)
安全性考虑:Serializable>Repeatable read>Read committed>Read uncommitted
数据库效率:Read uncommitted>Read committed>Repeatable read>Serializable
一般情况下,我们会使用Repeatable read、Read committed mysql数据库默认的数据库隔离级别Repeatable read
mysql在pycharm中设置数据库的隔离级别语句:
1 set [global/session] transaction isolation level xxxx
如果使用global则修改的是数据库的默认隔离级别,所有新开的窗口的隔离级别继承自这个默认隔离级别;如果使用session修改,则修改的是当前客户端的隔离级别,和数据库默认隔离级别无关。当前的客户端是什么隔离级别,就能防止什么隔离级别问题,和其他客户端是什么隔离级别无关。
mysql中设置数据库的隔离级别语句(终端):
select @@tx_isolation;
三、索引
1、索引简介
索引在mysql中也叫做‘键’,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是档表的数据量越来越大时,索引对于性能的影响就非常重要了。
索引优化应该是对于查询性能最有效的手段了。
索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果查新某个字,如果不使用音序表,则需要从几百页中查询。
索引特点:创建与维护索引会消耗很多时间与磁盘空间,但查询速度大大会提高。
2、索引语法
1 create table 表名( 2 字段1 数据类型[完整性约束条件], 3 字段2 数据类型[完整性约束条件], 4 [UNIQUE | FULLTEXT |SPATIAL] INDEX | KEY 5 [索引名] (字段名 数据类型) [asc|desc ] 6 )
1 # _*_ encoding:utf-8 _*_ 2 __author__ = 'listen' 3 __date__ = '2018/12/16 10:27' 4 --语法: 5 -- create table 表名( 6 -- 字段1 数据类型[完整性约束条件], 7 -- 字段2 数据类型[完整性约束条件], 8 -- [UNIQUE | FULLTEXT |SPATIAL] INDEX | KEY 9 -- [索引名] (字段名 [数据类型]) [asc|desc ] 10 -- ) 11 ------------------------------------------------------------------- 12 13 --创建普通索引示例: 14 15 CREATE TABLE emp1 ( 16 id INT, 17 name VARCHAR(30) , 18 resume VARCHAR(50), 19 INDEX index_emp_name (name) 20 --KEY index_dept_name (dept_name) 21 ); 22 23 24 25 --创建唯一索引示例: 26 27 CREATE TABLE emp2 ( 28 id INT, 29 name VARCHAR(30) , 30 bank_num CHAR(18) UNIQUE , 31 resume VARCHAR(50), 32 UNIQUE INDEX index_emp_name (name) 33 ); 34 35 --创建全文索引示例: 36 37 CREATE TABLE emp3 ( 38 id INT, 39 name VARCHAR(30) , 40 resume VARCHAR(50), 41 FULLTEXT INDEX index_resume (resume) 42 ); 43 44 --创建多列索引示例: 45 46 CREATE TABLE emp4 ( 47 id INT, 48 name VARCHAR(30) , 49 resume VARCHAR(50), 50 INDEX index_name_resume (name, resume) 51 ); 52 53 54 55 --------------------------------- 56 57 ---添加索引 58 59 ---CREATE在已存在的表上创建索引 60 CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 61 ON 表名 (字段名[(长度)] [ASC |DESC]) ; 62 63 ---ALTER TABLE在已存在的表上创建索引 64 65 ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX 66 索引名 (字段名[(长度)] [ASC |DESC]) ; 67 68 69 70 CREATE INDEX index_emp_name on emp1(name); 71 ALTER TABLE emp2 ADD UNIQUE INDEX index_bank_num(band_num); 72 73 74 -- 删除索引 75 76 语法:DROP INDEX 索引名 on 表名 77 78 DROP INDEX index_emp_name on emp1; 79 DROP INDEX bank_num on emp2;
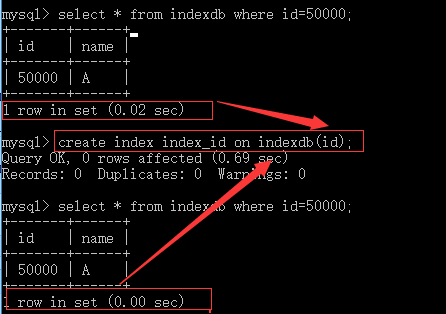
3、索引效率测试
delimiter可以修改终端的结束符从;变为你想变得
1 --创建表 2 create table Indexdb.t1(id int,name varchar(20)); 3 4 5 --存储过程 6 7 delimiter $$ 8 create procedure autoinsert() 9 BEGIN 10 declare i int default 1; 11 while(i<500000)do 12 insert into Indexdb.t1 values(i,'yuan'); 13 set i=i+1; 14 end while; 15 END$$ 16 17 delimiter ; 18 19 --调用函数 20 call autoinsert(); 21 22 -- 花费时间比较: 23 -- 创建索引前 24 select * from Indexdb.t1 where id=300000;--0.32s 25 -- 添加索引 26 create index index_id on Indexdb.t1(id); 27 -- 创建索引后 28 select * from Indexdb.t1 where id=300000;--0.00s