
Redis数据类型及其常用命令
一、Redis字符串(String)
String是Redis最基本的类型,一个key对应一个value,它是二进制安全的(String可以包含任何数据,如jpg图片或者序列化的对象),
一个字符串value最多可以是512MB
SET key value [NX | XX] [GET] [EX seconds | PX milliseconds | EXAT unix-time-seconds | PXAT unix-time-milliseconds | KEEPTTL]-
EX以秒为单位设置过期时间 PX以毫秒为单位设置过期时间EXAT设置以秒为单位的UNIX时间戳所对应的时间为过期时间(Unix 时间戳是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒。)PXAT设置以毫秒为单位的UNIX时间戳所对应的时间为过期时间NX键不存在时设置键值XX键存在时设置键值KEEPTTL保留设置前指定键的生存时间。之前设置了键的过期时间,如果用新的 value 值覆盖旧的并且不设置过期时间,新的 value 就会永不过期GET返回指定键原本的值,若键不存在时返回 nil
(1)同时设置/获取多个键值对
MSET k1 v1 k2 v2...同时设置多个键值对
MGET k1 k2 k3...同时获取多个键值对
MSETNX k1 v1 k2 v2键不存在时设置键值对
(2)获取指定区间范围内的值(下标从0开始)
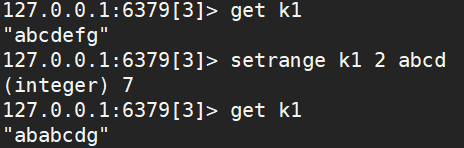
GETRANGE k1 0 -1获取 k1 的全部值;GETRANGE k1 x y获取下标从 x 到 y 的内容SETRANGE k1 x abcd从下标 x 开始将 abcd 覆盖掉原内容
(3)数值增减(value必须是数字)
INCR keykey = key + 1INCRBY key xkey = key + xDECR keykey = key - 1DECRBY key xkey = key - xSTRLEN key获取 key 的长度APPEND key xxxx在 key 后加上 xxxx
(4)分布式锁
SETEX key 过期时间(秒) value创建键值对并设置过期时间
(5)getset(先get在set)
GETSET key newValue获取 key 的值再将 newValue 赋给 key,类似于SET key newValue GET
二、Redis列表(List)
底层是双向链表,可以在列表头部和尾部插入元素,最多可以包含2^32 - 1(4,294,967,295--超过40亿)个元素
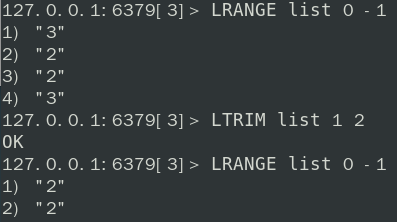
LPUSH key 1 2 3 4 5在列表头部依次插入这些元素RPUSH key 1 2 3 4 5在列表尾部依次插入这些元素LRANGE key 0 -1从左向右遍历输出列表;LRANGE key start stop从 start 遍历输出到 stopLPOP key移出并获取列表的第一个元素RPOP key移出并获取列表的最后一个元素LINDEX按照元素下标获取元素(下标从上向下数,从0开始)LLEN获取列表的长度LREM key 数字N value删除 N 个值等于 value 的元素LTRIM key start stop截取指定范围内的元素再赋值给 key
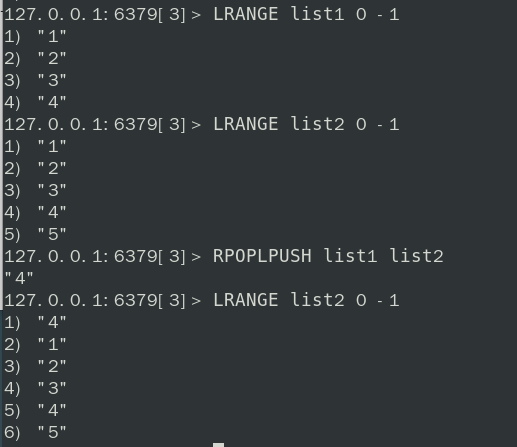
RPOPLPUSH 源列表 目的列表将源列表的最后一个元素移到目的列表的头部
LSET key index value将 key 中下标为 index 的元素赋值为 valueLINSERT key before | after 已有值 新值在 key 中已有值的前面或后面插入新值
三、Redis哈希表(Hash)
是一个String类型的field(字段)value(值)的映射表,每个hash可以存储2^32 - 1个键值对
Map<String, Map<Object, Object>>
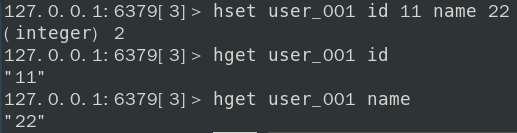
HSET key field value [field value ...]HGET key field
HMSET已被弃用,使用 HSET 也可以一次设置多个键值对HMGET key field [field ...]可以同时根据多个 fileld 获取 valueHGETALL key
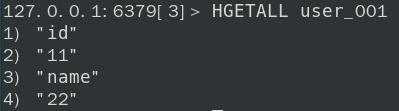
HDEL key field [field ...]
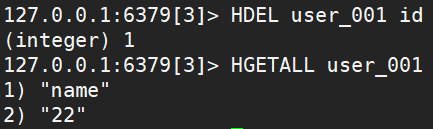
HLEN key显示 key 中全部键值对的数量HEXISTS key field查询 key 中是否有以 field 为 key 的键值对,1 为 true、0 为 falseHKEYS key类似于 Java 中的 keySet(),HVALS key类似于 Java 中的 values()HINCRBY key field increment为 key 中的 field 的值加上 increment(整数),HINCRBYFLOAT key field increment加上指定的小数,也可以加整数HSETNX key field value在 key 中 field 不存在时设置,成功返回 1,失败返回 0
四、Redis集合(Set)
Set是String类型的无序集合,集合成员是唯一的(无序无重复),集合对象的编码可以是 intset 或者 hashtable。Set是通过哈希表实现的,
添加、删除、查找的复杂度是O(1),集合中最大的成员数为2^32 - 1
SADD key member [member ...]向集合里添加数据,只插入不重复的数据,自动去重SMEMBERS key查看集合中的全部元素SISMEMBER key member判断 member 在不在集合中,1在、0不在SREM key member [member ...]在集合中删除指定的元素,返回 0 表示没有该元素,返回 1 表示删除成功SCARD key统计集合中元素的数量SRANDMEMBER key [count]从集合中随机显示 count 个元素SPOP key [count]从集合中随机弹出 count 个元素并删除SMOVE source destination member将 source 中存在的 member 元素剪切到 destination中,一次只能移动一个元素
集合运算
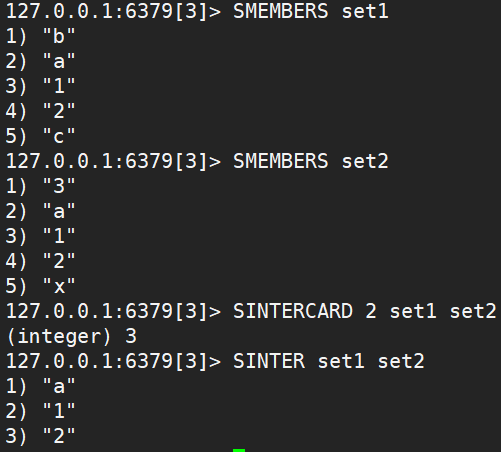
SDIFF key [key ...]A - B ,属于 A 但不属于 B 的元素SUNION key [key ...]A ∪ B,取两者的并集(自动去重)SINTER key [key ...]A ∩ B,取两者的交集SINTERCARD numkeys key [key ...] [LIMIT limit]显示 numkeys 个集合取交集后的集合的元素数量
五、RedisZSet(Sorted set | ZSet)
有序集合,与Set一样也是String类型元素的集合,集合成员是唯一的,但是每个元素都会关联一个double类型的分数,通过分数来进行排序,分数可以重复。
ZSet是通过哈希表实现的,添加、删除、查找的复杂度是O(1),集合中最大的成员数为2^32 - 1
ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member ...]向有序集合中加入一个元素和该元素的分数ZRANGE key min max按照元素分数大小输出该集合的 member(升序输出),ZRANGE zset1 0 -1 WITHSCORES比前面多加了一个 scoreZREVRANGE key start stop [WITHSCORES]降序输出ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]输出分数在 [ min, max ] 之间的元素,LIMIT:输出 下标在 [offset, count] 之间元素ZRANGEBYSCORE key min max输出分数在 [ min, max ] 之间的元素,min、max是分数ZSCORE key member获取指定元素的分数ZCARD key获取集合全部元素的个数ZREM key member [member ...]删除集合里面的元素ZINCRBY key increment member为指定 member 的分数加上 incrementZCOUNT key min max统计分数在 [ min, max ] 中元素的个数ZMPOP numkeys key [key ...] MIN|MAX [COUNT count]从 numkeys 个集合里面弹出 count 个最大或最小的元素ZRANK key member获取集合中 member 元素的下标 ,下标从0开始ZREVRANK key member逆序获取集合中 member 元素的下标
六、Redis地理空间(GEO | Geospatial)
存储地理位置信息,可以添加地理位置的坐标、获取地理位置的坐标、计算两个地理位置之间的距离、根据用户给定的经纬度来获取指定范围内的地理位置集合
底层是 zset,输出中文乱码的解决方法:redis-cli -a 密码 --raw加上 --raw
GEOADD key [NX|XX] [CH] longitude latitude member [longitude latitude member ...]存储 member 的经度(longitude)和纬度(latitude)到 key 中GEOPOS key member [member ...]返回 key 中指定成员的经纬度 天安门 故宫 八达岭长城GEOHASH key member [member ...]将指定 member 的经纬度映射为一个值GEODIST key member1 member2 [M|KM|FT|MI]计算 member1 和 member2 之间的距离(单位默认为米),单位有米、千米、英尺、英里GEORADIUS key longitude latitude radius M|KM|FT|MI [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count [ANY]] [ASC|DESC] [STORE key] [STOREDIST key]
以给定的经纬度为中心,返回与中心距离不超过 radius 的所有位置(在 key 中进行比较)
WITHCOORD返回位置的经纬度
WITHDIST返回与中心之间的距离
WITHHASH以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。(菜鸟教程)
COUNT显示返回元素的个数
ASC返回位置按距离从近到远显示(升序)
DESC返回位置按距离从远到近显示(降序)
GEORADIUSBYMEMBER key member radius以给定的 member 为中心,返回与中心距离不超过 radius 的所有位置(在 key 中进行比较)
七、Redis基数统计(HyperLogLog)
HyperLogLog是用来基数统计的算法,统计网站的 UV(Unique Visitor 独立访客:一般为客户端IP),统计搜索网站关键词的数量。用于统计一个集合中不重复的元素个数。误差率为 0.81%
PFADD key [element [element ...]]将元素添加到 HyperLogLog 中PFCOUNT key [key ...]返回给定 HyperLogLog 的基数估计值PFMERGE destkey sourcekey [sourcekey ...]将多个 HyperLogLog 合并为一个存到 destkey 中
八、Redis位图(Bitmap)
基于String数据类型,由0和1状态表现的二进制bit数组(bit arrays),用来判断 Y/N 状态
SETBIT key offset value设置位图的第 offset 位的值,offset 最大值为 2^32,512MB = 2^9 × 2 ^ 20 × 2^3 = 2^32GETBIT key offset获取指定位的值STRLEN key获取该位图占据的字节长度,每 8 位为一组BITCOUNT key [start end [BYTE|BIT]]统计位图中 1 的个数BITOP operation destkey key [key ...]对 key 进行 AND(与)、OR(或)、NOT(非)、XOR(异或)运算并将结果存到 destkey 中
九、Redis位域(Bitfield)
可以一次性操作多个比特位域(指连续的多个比特位),并返回一个响应数组,数组中的元素对应参数列表中的相应操作的执行结果
十、Redis流(Stream)
是Redis 5.0 版本新增的数据结构。Stream主要用于消息队列(MQ,Message Queue)。Redis版本的消息中间件。
XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|id field value [field value ...]添加消息到队列末尾消息ID要比上一个消息ID大;默认用 * 自动生成 ID
![]()
会返回生成的消息ID,由毫秒时间戳和该毫秒内产生消息的个数组成
XRANGE key start end [COUNT count]用于获取消息队列,忽略删除的消息,- 代表最小值, + 代表最大值XREVRANGE key end start [COUNT count]倒着获取消息队列XDEL key id [id ...]删除指定消息XLEN key获取消息队列中消息的个数XTRIM key MAXLEN|MINID [=|~] threshold [LIMIT count]对消息队列进行截取,MAXLEN 限定消息队列的最大长度(删掉旧的),MINID 截取掉比指定时间戳小的消息
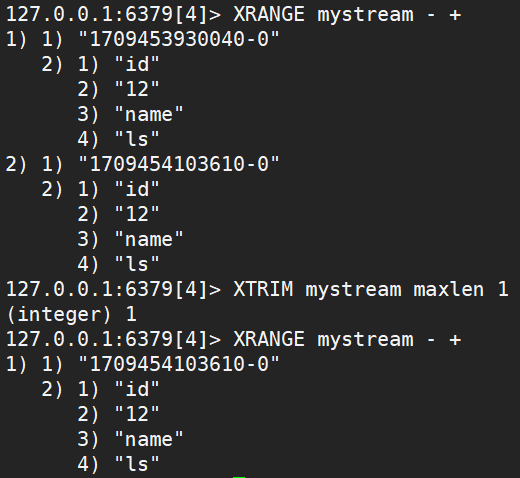
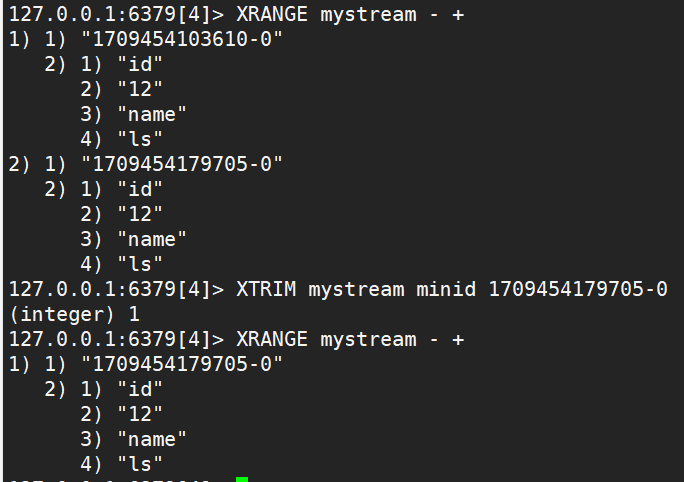
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]用于获取消息(阻塞和非阻塞),只会返回大于指定ID的消息
COUNT最多读取多少条信息;BLOCK是否已阻塞的方式读取消息,默认不阻塞,milliseconds如果设置为 0,表示永远阻塞
XREAD count 2 streams mystream 000 | 0-0 | 00代表从最小的ID开始获取 Stream 中的消息,不指定 COUNT 时,返回所有消息
XREAD count 1 block 0 streams mystream $以阻塞方式获取最新的消息,会等待着获取最新的消息
XGROUP CREATE key groupname id|$ [MKSTREAM] [ENTRIESREAD entries_read]创建消费者组,$ 表示从 Stream 尾部开始消费(只消费新的的消息),0 表示从 Stream 头部开始消费
![]() 为 $ 表示只消费最新的的消息
为 $ 表示只消费最新的的消息
![]() 为 0-0 或者 0 表示从头开始消费(从旧的开始消费)
为 0-0 或者 0 表示从头开始消费(从旧的开始消费)
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...]> 表示从第一条尚未被消费的消息开始读取
![]() 消费组 groupX 内的消费者 consumer1 从 mystream 中读取所有消息(默认读取全部消息)
消费组 groupX 内的消费者 consumer1 从 mystream 中读取所有消息(默认读取全部消息)
同一个消费组的消费者不能消费同一条消息,如果继续消费会显示 nil(读到空值),不同组的消费者可以消费同一条消息。
创建消费组的目的:让组内的多个消费者共同分担读取消息的工作,从而实现消息读取负载的多个消费者间是均衡分布的
XPENDING key group [[IDLE min-idle-time] start end count [consumer]]查询每个消费组内所有消费者已读但未确认的消息
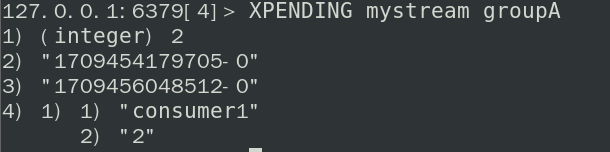
XACK key group id [id ...]确认该消费组读取了那些消息
![]() 确认 groupA 中 1709454179705-0 已被读取
确认 groupA 中 1709454179705-0 已被读取
XINFO STREAM key [FULL [COUNT count]]显示指定 Stream 的详细信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号