
大数据学习笔记
大数据学习笔记
Zookeeper
是一个领导者,多个跟随者组成的集群。集群中只要有半数以上的节点存活,集群就能正常服务。
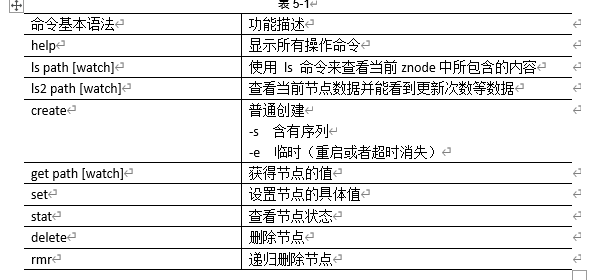
ZK的shell操作
Hive
hive是Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是将HQL转化成MapReduce程序。
hive采用了类似于sql的语言,叫做HQL。但是hive并不是数据库,hive是用mapreduce来查的。hive不建议对数据进行改写,所有的数据都是在加载的时候确定好的。
hive的基本操作
- 启动hive
bin/hive - 查看数据库
show databases - 打开数据库
use databasename - 显示某个数据库中的表
show tables - 创建一张表
create table student(id int, name string); - 查看表的结构
desc student - 向表中插入数据
insert into student values(1000, "ss"); - 查询表中的数据
select * from student - 退出hive
quit;
可以看到和sql语句及其相似。
hive的数据类型
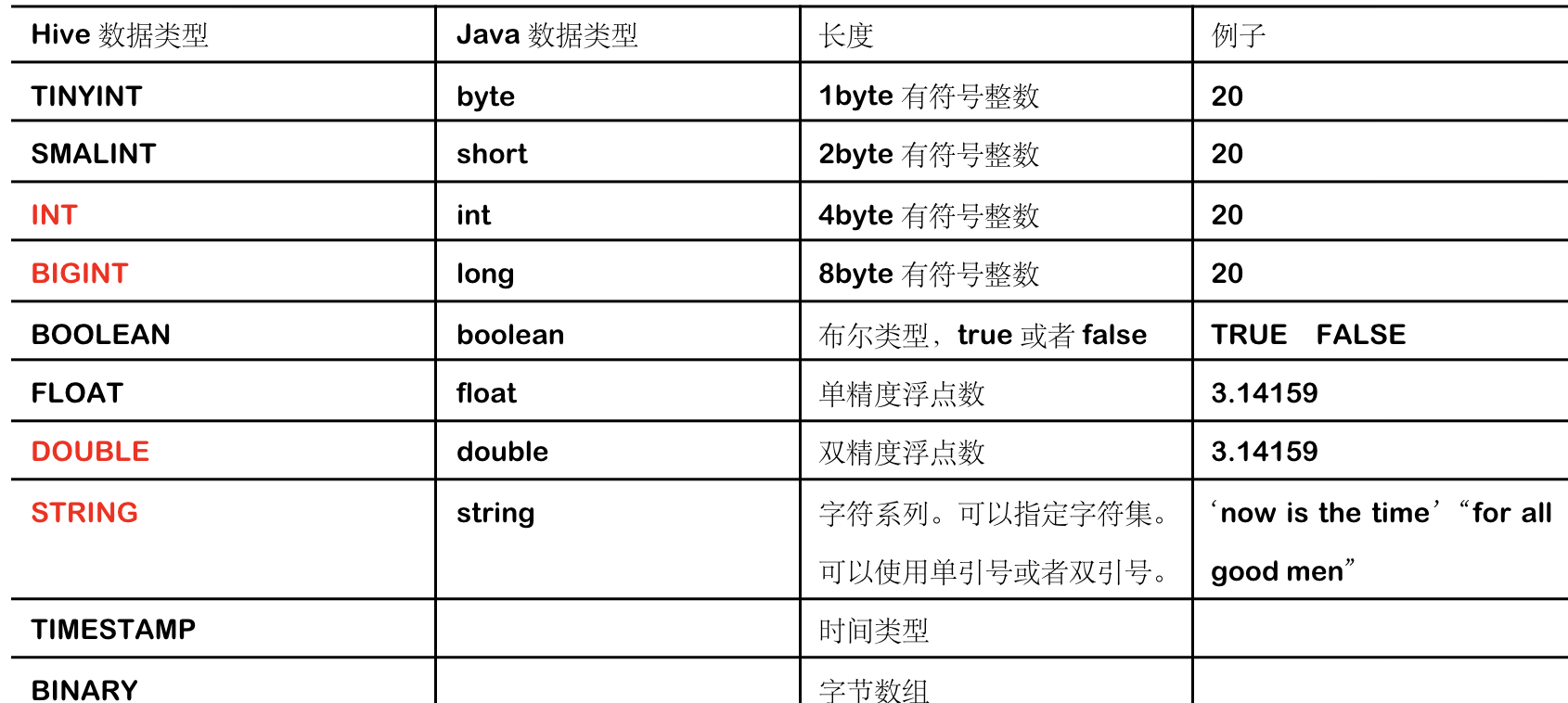

对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
尘嚣看不见,你沉醉了没

 浙公网安备 33010602011771号
浙公网安备 33010602011771号