

用python批量爬取B站视频弹幕(评论)
声明不用说了,直接进入主题
还是接上次的爬虫爬取B站视频弹幕和评论
思路
以我的主页为例,如下

然后找到存有我相关视频数据的文件,如下
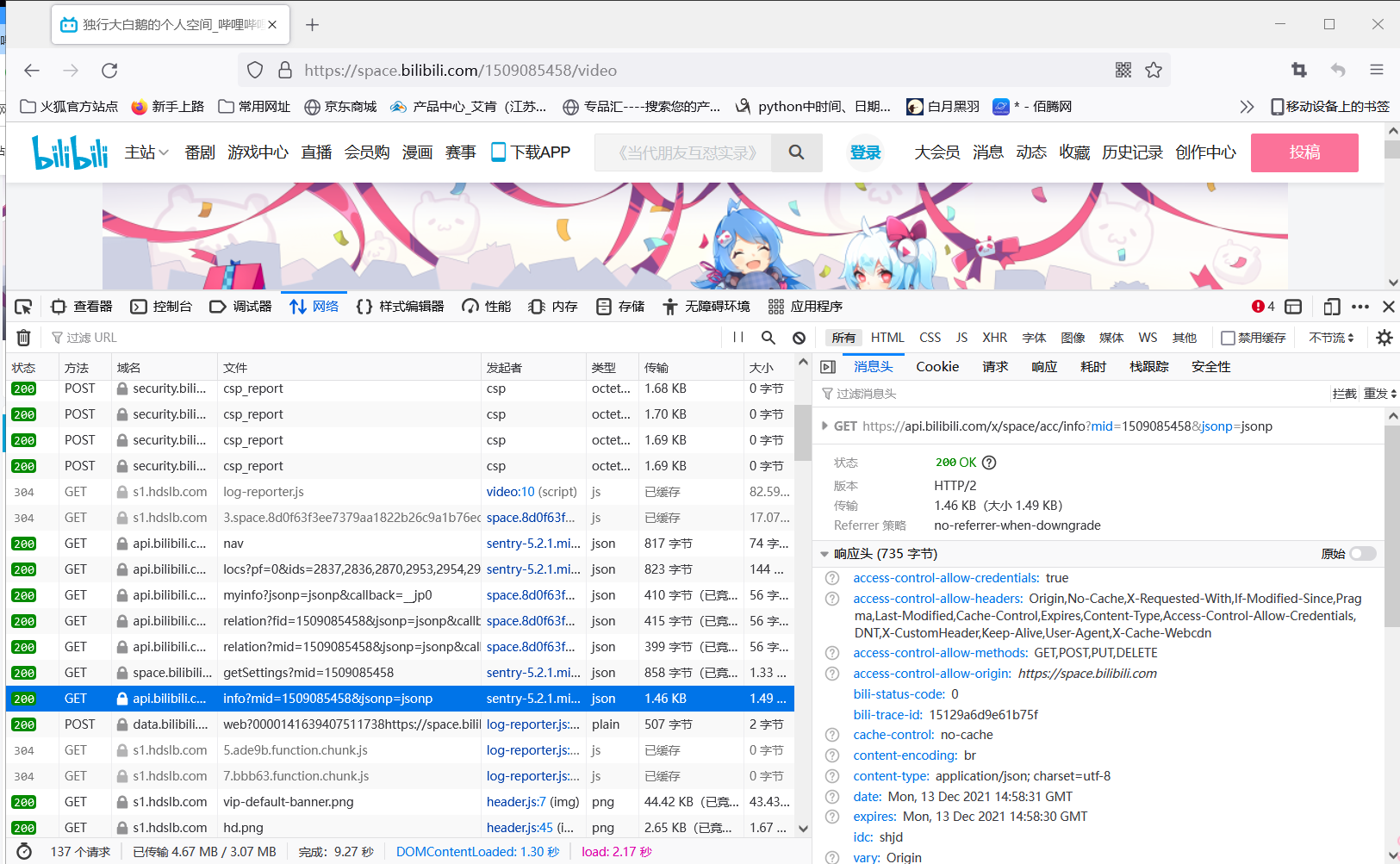
然后我们随便点开一个视频,进入api端口查看相关信息

我们发现视频的cid号和oid号是一样的,所以我们只需要获取到视频相应的cid,然后将弹幕文件中的oid号用这里的cid号代替就可以了(事实上cid和oid号是一样的)。
让我们回到我的主页,F12寻找存有我视频aid号的文件
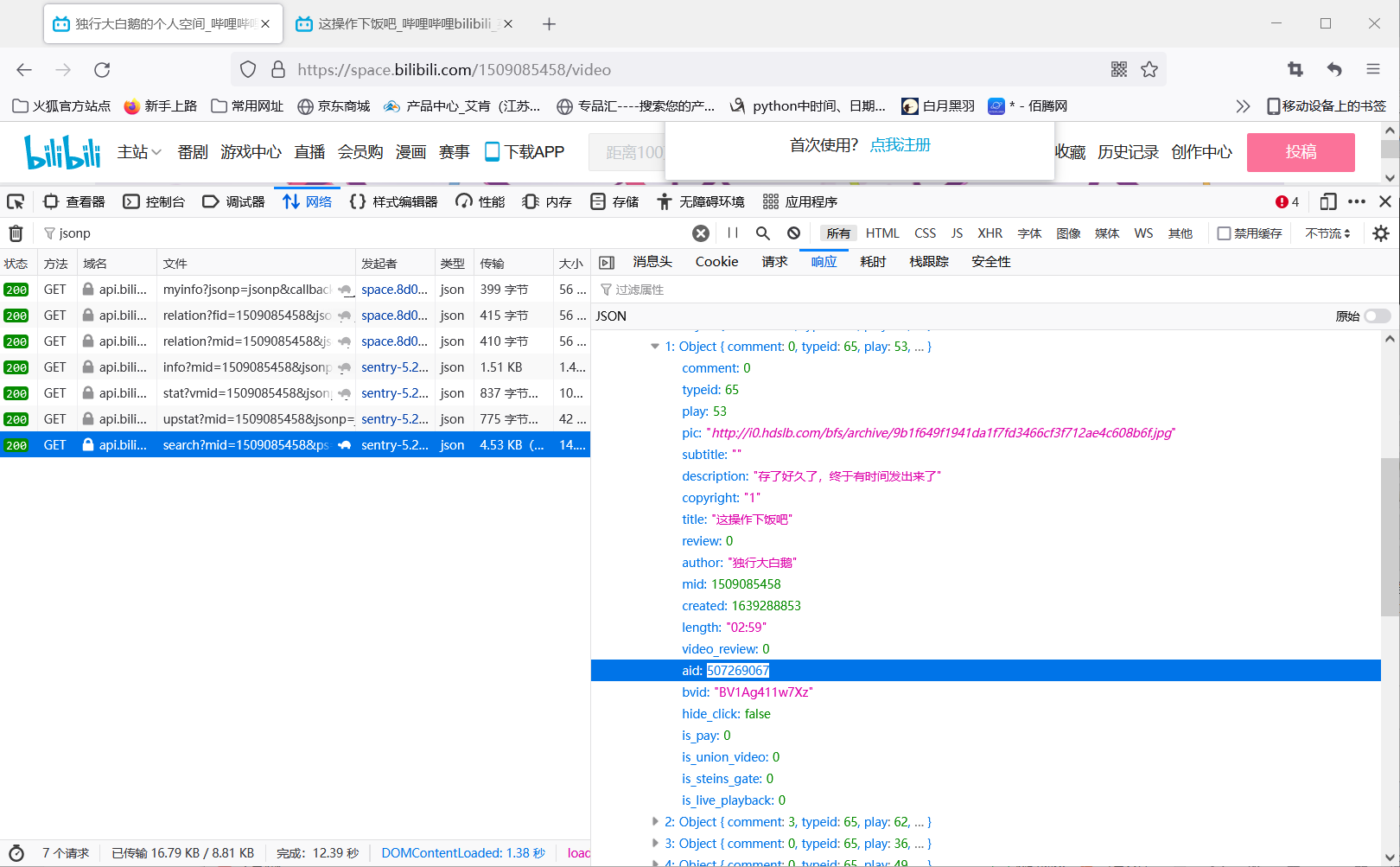
这个文件很明显显示了我主页这一页的所有视频(当然每页数量是可以改的,页数也是可以改的,这里只提供思路),然后使用代码爬取到这些视频的aid号
接着,我们随便点开一个视频,进入api端口,按F12寻找到存有视频cid号的文件,如下
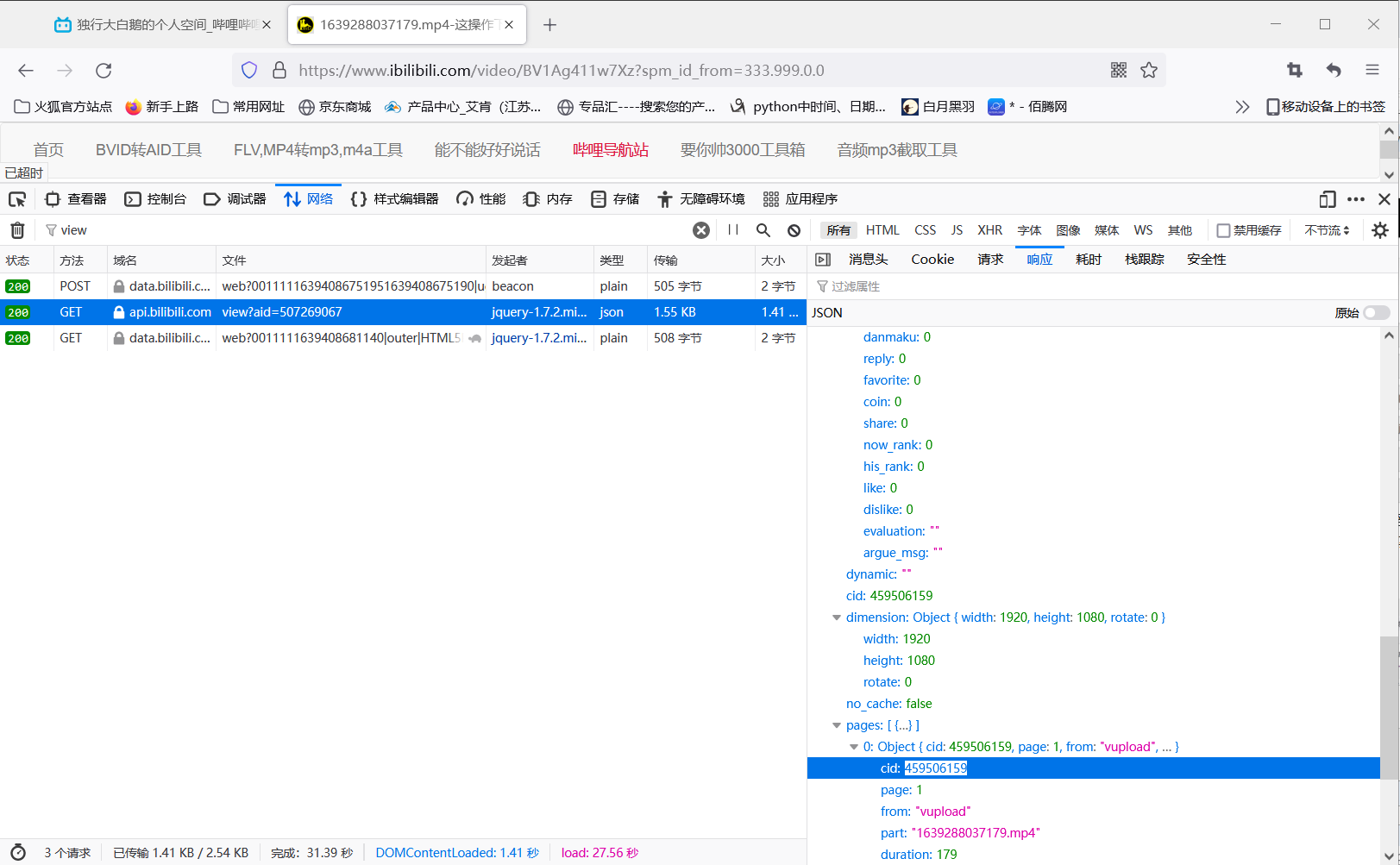
管你用什么方式,只要获取到里面的cid号就大功告成了
将你获取到的视频cid号放进列表中,然后用循环取出来使用就能实现批量爬取数据的目的了
设计代码如下(这里只给出爬取视频aid号的代码,cid号的爬取只需要在此基础上写一个循环就可以实现了)
import requests
import time
mid = str(input('请输入你要爬取的up主mid号:'))
# 获取视频总数
url = 'https://api.bilibili.com/x/space/arc/search?mid={}&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'.format(mid)
response = requests.get(url).json()
count = response['data']['page']['count']
# 获取aid号
if count > 50:
url2list = []
aidurllist = []
i = 1
n = 0
while i < (count//50)+2:
url1 = 'https://api.bilibili.com/x/space/arc/search?mid=25503580&ps=50&tid=0&pn={}&keyword=&order=pubdate&jsonp=jsonp'.format(i)
response1 = requests.get(url1).json()
m = 0
while m < 50:
aid = response1['data']['list']['vlist'][m]['aid']
aidurl = str(n+1)+'.'+'https://api.bilibili.com/x/web-interface/view?aid=' + str(aid)
print(aidurl)
m += 1
n += 1
i += 1
else:
url1 = 'https://api.bilibili.com/x/space/arc/search?mid={0}&ps={1}&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'.format(mid, count)
response1 = requests.get(url1).json()
i = 0
aidurllist = []
while i < count:
aid = response1['data']['list']['vlist'][i]['aid']
aidurl = str(i+1)+'.'+'https://api.bilibili.com/x/web-interface/view?aid=' + str(aid)
print(aidurl)
i += 1
解释一下,为什么这里有一个判断视频数量的代码块,因为本人测试过,一页最多只能有50个视频,因此这里需要设置条件语句判断视频数量
让我们看看运行效果

很明显我们顺利地爬到了存有视频cid号的文件,接着写一个循环就可以实现批量爬取咯。(其实是本人精力有限,这里只提供设计思路就ok了)
然后下面提供一份可以爬取一页(最多50个)视频的弹幕文件的代码
import requests
import time
mid = str(input('请输入你要爬取的up主mid号:'))
# 获取视频总数
url = 'https://api.bilibili.com/x/space/arc/search?mid={}&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'.format(mid)
response = requests.get(url).json()
count = response['data']['page']['count']
# 获取aid号
url1 = 'https://api.bilibili.com/x/space/arc/search?mid={0}&ps={1}&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'.format(mid, count)
response1 = requests.get(url1).json()
i = 0
url2list =[]
aidurllist = []
while i < count:
bvid = response1['data']['list']['vlist'][i]['bvid']
aid = response1['data']['list']['vlist'][i]['aid']
url2 = 'https://www.ibilibili.com/video/' + bvid + '?spm_id_from=333.999.0.0'
aidurl = 'https://api.bilibili.com/x/web-interface/view?aid=' + str(aid)
url2list.append(url2)
aidurllist.append(aidurl)
i += 1
time.sleep(0.2)
# 获取cid或oid号并打印弹幕文件url地址
n = 0
while n < count:
getdata = requests.get(aidurllist[n]).json()
oid = getdata['data']['pages'][0]['cid']
danmu = 'https://api.bilibili.com/x/v1/dm/list.so?oid=' + str(oid)
print(str(n+1) + '.' + danmu)
n += 1
time.sleep(0.2)
让我们运行一下看看效果

很明显,我顺利地爬到了自己视频的弹幕文件(弹幕挺少的呵呵呵)
然后再用我们之前的方法写一个循环结构就可以对弹幕进行批量的加工处理了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号