

用python爬取图片
声明:全过程没有任何违法操作
背景
这周闲的无聊,到某个不用FQ就能上P站的网站上欣赏图片,但是光欣赏也不够,我得下载下来慢慢欣赏,于是便写了个爬虫(批量)下载图片(因为在这个网站上下载需要一张一张下载,麻烦)。
分析
下载单张图片
首先打开我想要下载的作品集的网页,然后F12寻找我需要的目标文件,然后再爬虫上运行一下看看状态是什么
import requests
url = 'https://pixiv-image.pwp.link/img-original/img/2018/12/08/03/57/33/72014282_p0.jpg'
headers = {
'Origin': 'https://pixiviz.pwp.app',
'Referer': 'https://pixiviz.pwp.app/pic/72014282',
'Sec-Fetch-Dest': 'empty',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Mobile Safari/537.36'
}
response = requests.get(url, headers=headers)
print(response)
结果显示是200,说明可以下载
下载可以使用如下代码
filename = str('图片')+".png"
with open(filename,"wb") as code:
code.write(response.content)
print('文件下载成功!')
如图,图片下载成功
注意:这个下载的文件的请求头必须写完整,否则图片是无法爬取到的
批量下载
其实批量下载有多种方法,我只讲一种,还有一种我会在最后说思路
在我们所要爬取的网页中的作品集一共有15张图片,于是我们可以尝试吧url中的"p0"中的数字进行修改然后再看看效果
图片会更改,于是我们可以设计一个循环来实现图片批量爬取,设计如下
import requests
import time
i = 0
while i < 15:
url = 'https://pixiv-image.pwp.link/img-original/img/2018/12/08/03/57/33/72014282_p{}.jpg'.format(i)
headers = {
'Origin': 'https://pixiviz.pwp.app',
'Referer': 'https://pixiviz.pwp.app/pic/72014282',
'Sec-Fetch-Dest': 'empty',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Mobile Safari/537.36'
}
response = requests.get(url, headers=headers)
filename = str('图片{}'.format(i))+".png"
with open(filename,"wb") as code:
code.write(response.content)
print('图片{}下载成功!'.format(i))
i += 1
time.sleep(0.5)
这里的time.sleep是用来减慢爬取速度,防止网站识别爬虫而禁ip访问

上图是第15张图片
这是我们爬到的第15张图片
于是这样我们就实现了图片的批量爬取
批量下载的另种设计思路
在这个网站(网站url我不会给出)上可以进入画师主页,然后F12可以寻找到对应的作品集文件,然后发送请求返回文件中的数据(json文件),最后利用循环就能设计出批量爬取图片的程序了,下面我就放一张自己设计的程序运行图片
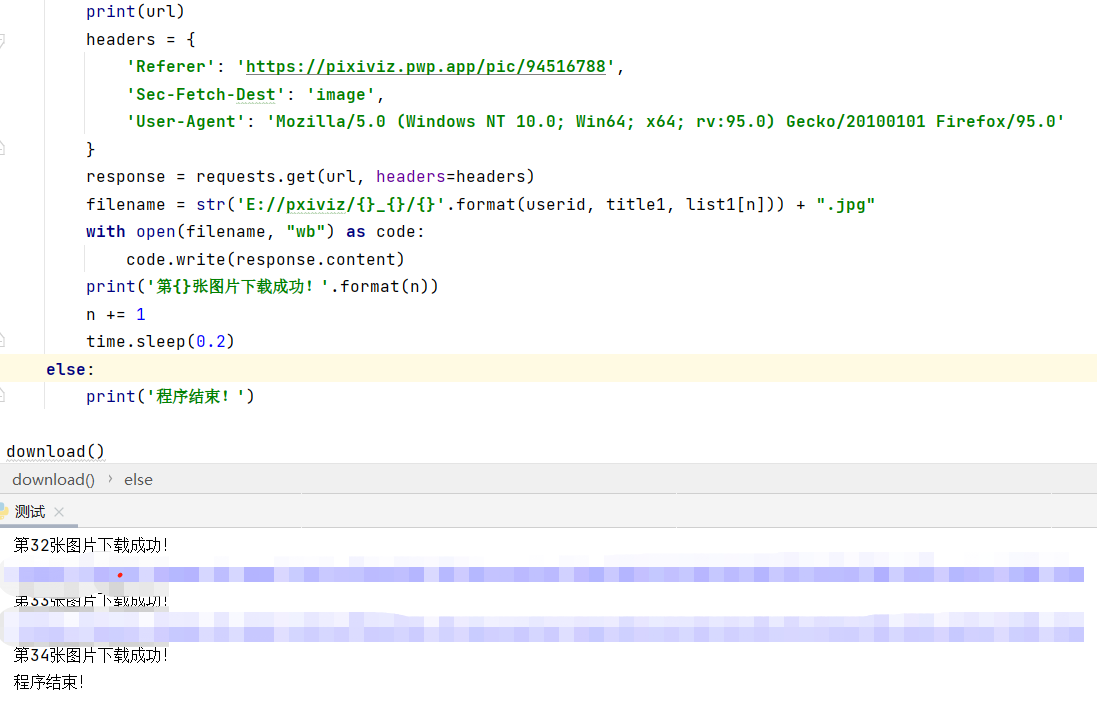
至于本人欣赏什么类型的图片,大伙儿就不用知道了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号