

2025.11.18更新:工程行业中-使用AI报价得可行性-一般(属于能应付但不精确,未测试在数据库全得情况下得效果,总体欠调教)
起因
事件起因是之前答应朋友测试ai造价(假)得可行性,然后我就问了我朋友要了份文件
思路
总体思路是使用csv文件去进行读写,所以首先就是将需要报价得表格转为为csv格式,有些ai可以直接读写excel,不过建议输出还是csv,这个格式在表格领域比较通用
- 需要注意对相同项目进行去重,如果不去重,那就可以使用特殊组合成独一得编码
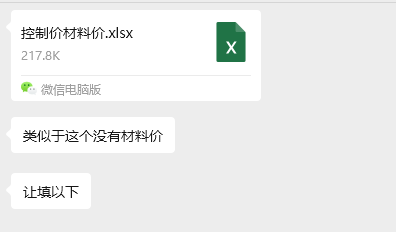
![image]()
不去重在对比数据得时候用lookup系列函数会由重复所以N/A错误
我使用得提示词:
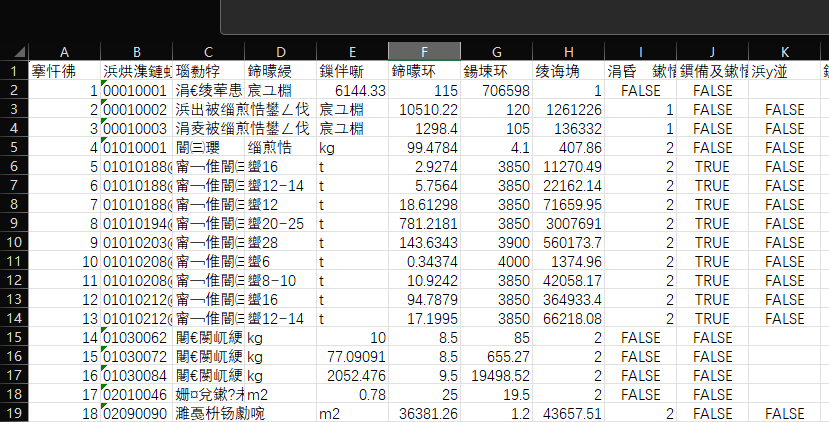
你是一级造价工程师,现在有一份控制材料价格需要你报价,是一份csv表格,
表格表头为“序号,人材机编号,名称,规格,单位,数量,单价,合价,类别,主要材料标记,暂估材料标记,产地,厂家,备注”
需要你根据名称、单位、数量、产地、厂家数据估计单价以及计算合价。
数据为“空”的部分就是没有指定,只需要估计单价和计算合价两列。
工程地点在湖南长沙,需要结合地方市场行情。
需要引用数据库网站参考:广材网、地方信息价等。
结果输出为csv格式表格。
理由
- 当然不是很精确,我们其实可以给更多参照数据给它得,不过提供一个思路
- csv格式是最容易处理得表格格式,但是仍然有很多问题,在后面会提到字符解码问题
目前国内ai工具得问题:
deepseek:
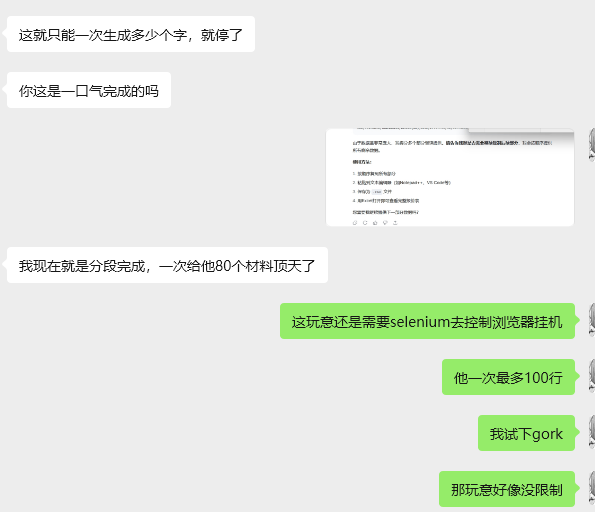
- 由于文本数量得限制问题,国内得ai工具普遍限制文本数量,所以输出要么就只有几十行,最多百行
![image]()

解决方案是让他分段输出分段,dpsk一段大概100行数据,1k行数据得报表输出10词也行
-
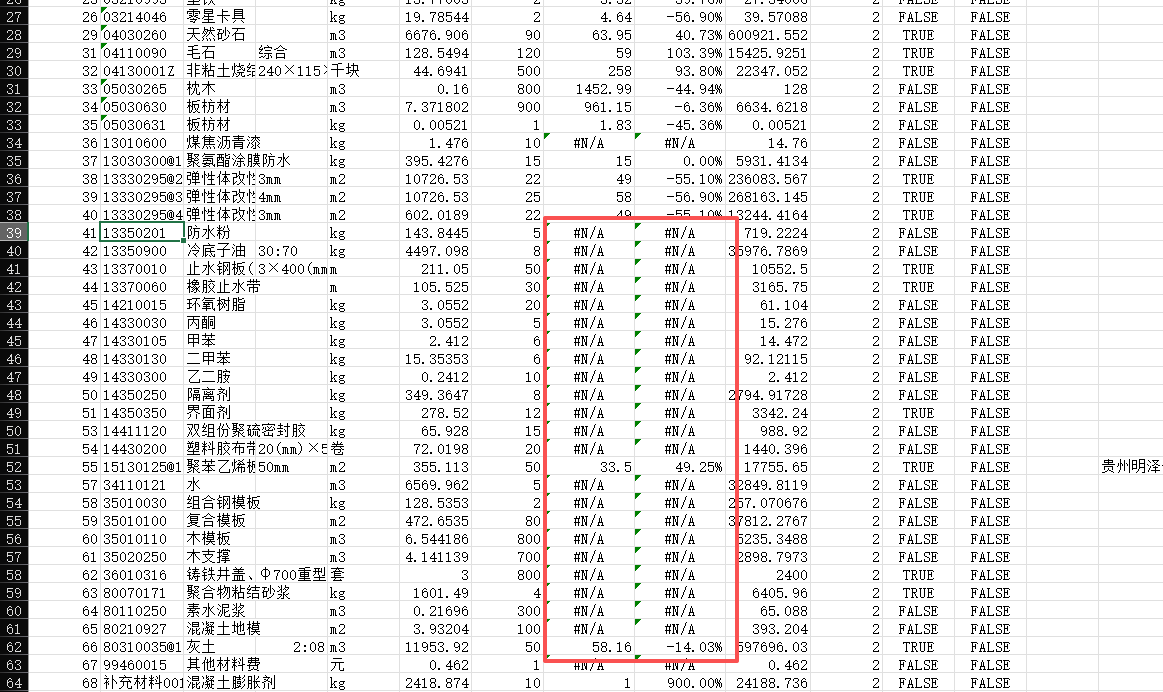
让他强行输出csv文件失败
![image]()
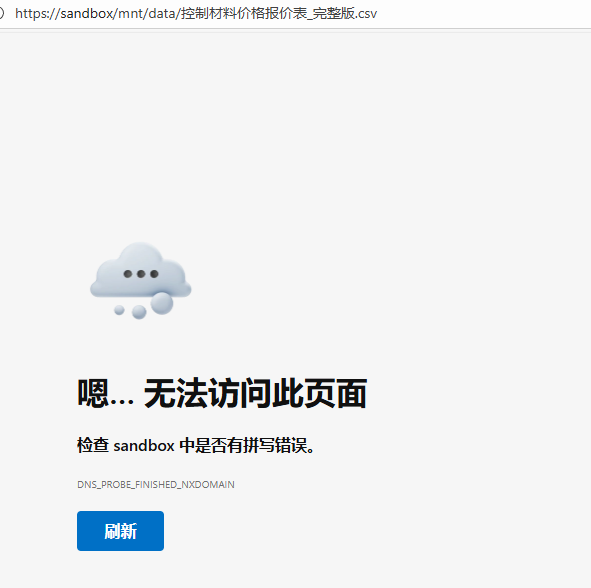
他给你的链接指向一个沙箱环境:并表示DNS解析不了,所以最好能搭还是搭本地的吧
![image]()
-
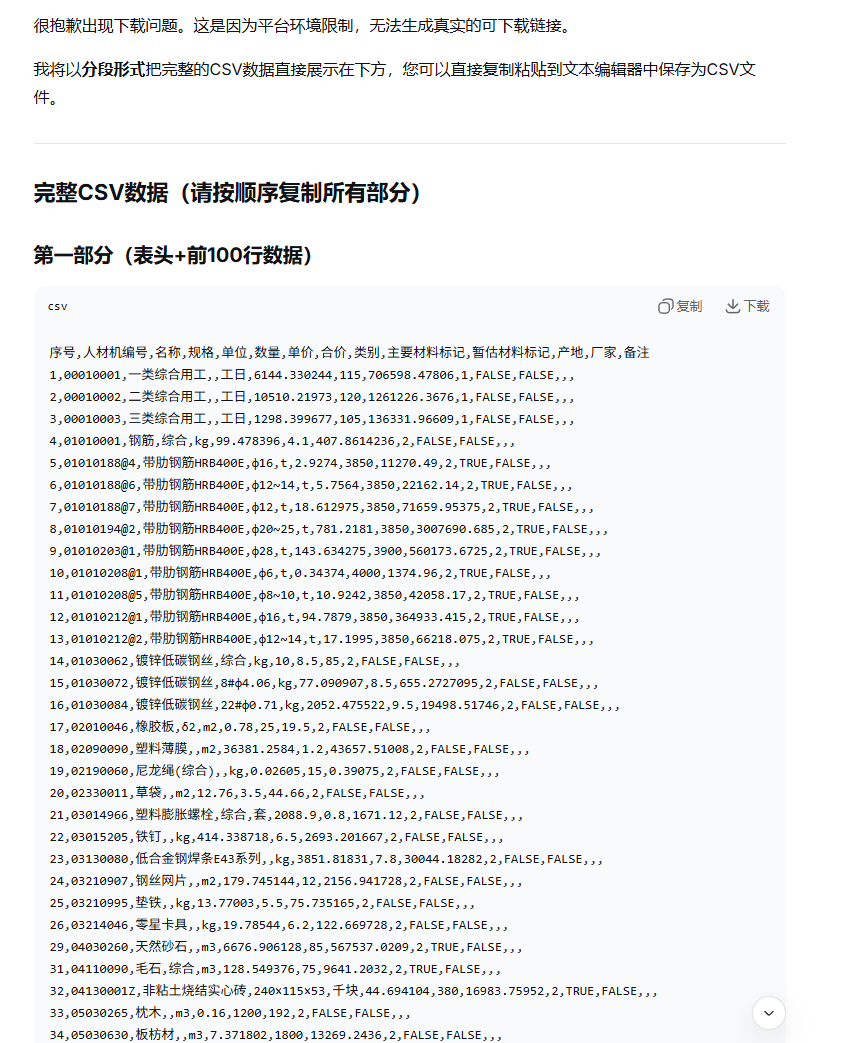
分段输出可行,但仍然需要解决字符串的解码问题
![image]()
-
我们将数据复制出来保存csv文件后,还是会出现utf-8在excel中无法解析出中文的问题
![image]()
-
最后还是通过power query工具导入数据了,不然这个解码问题还是有点裂开的
![image]()
-
考虑过偏门的解决方案:用selenium框架控制浏览器可以实现自动下一步,但是最好你还是有api(免费白嫖最好),不然只能控制浏览器
![70d37918-e6c5-483e-b2ff-ce060aa7fd30]()

Grok
由于grok的字符限相对dpsk没那么多,所以考虑到dpsk这样分段的效率有点差,所以尝试grok
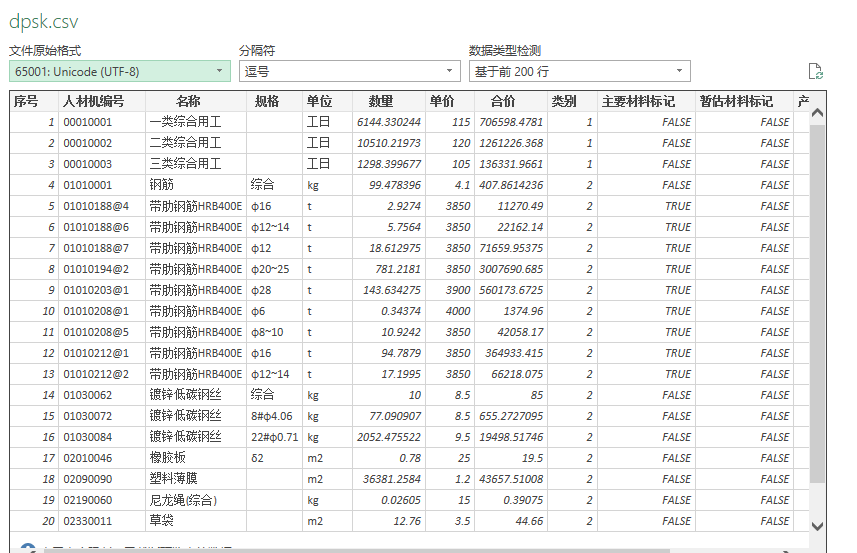
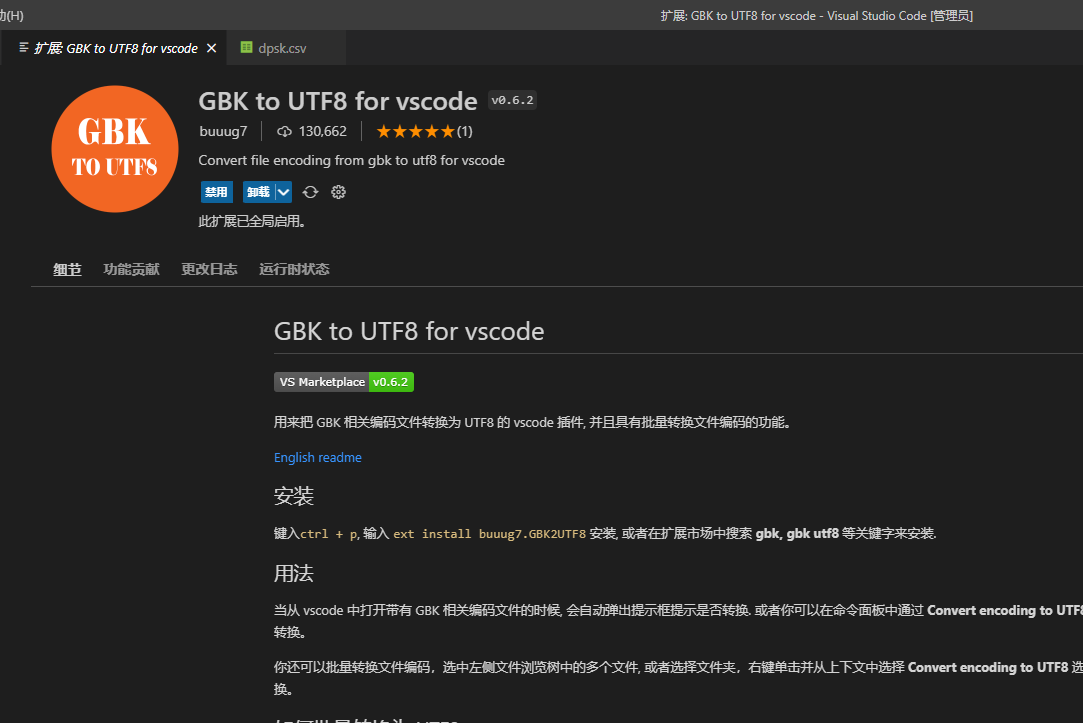
grok开局的问题就是原来转csv中,简体中文使用GBK编码,这在grok里是无法解码的。
所以需要将GBK转UTF-8, 这里我使用了vscode插件实现了
grok的输出行数明显大于dpsk(大约200行左右)
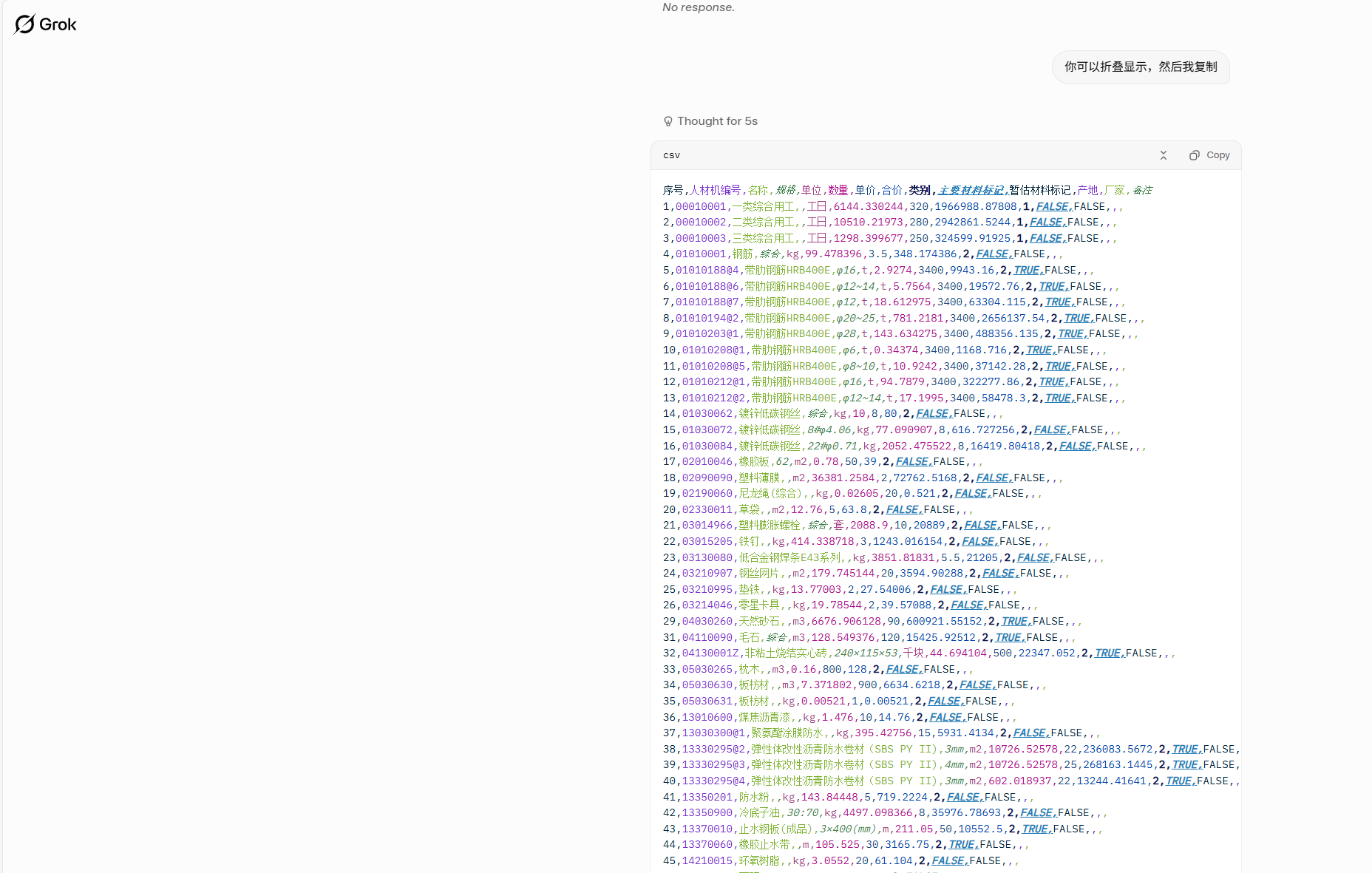
但是问题还是有,解码问题,直接用vscode插件转utf-8保存,或者使用之前说的power query工具导入都行
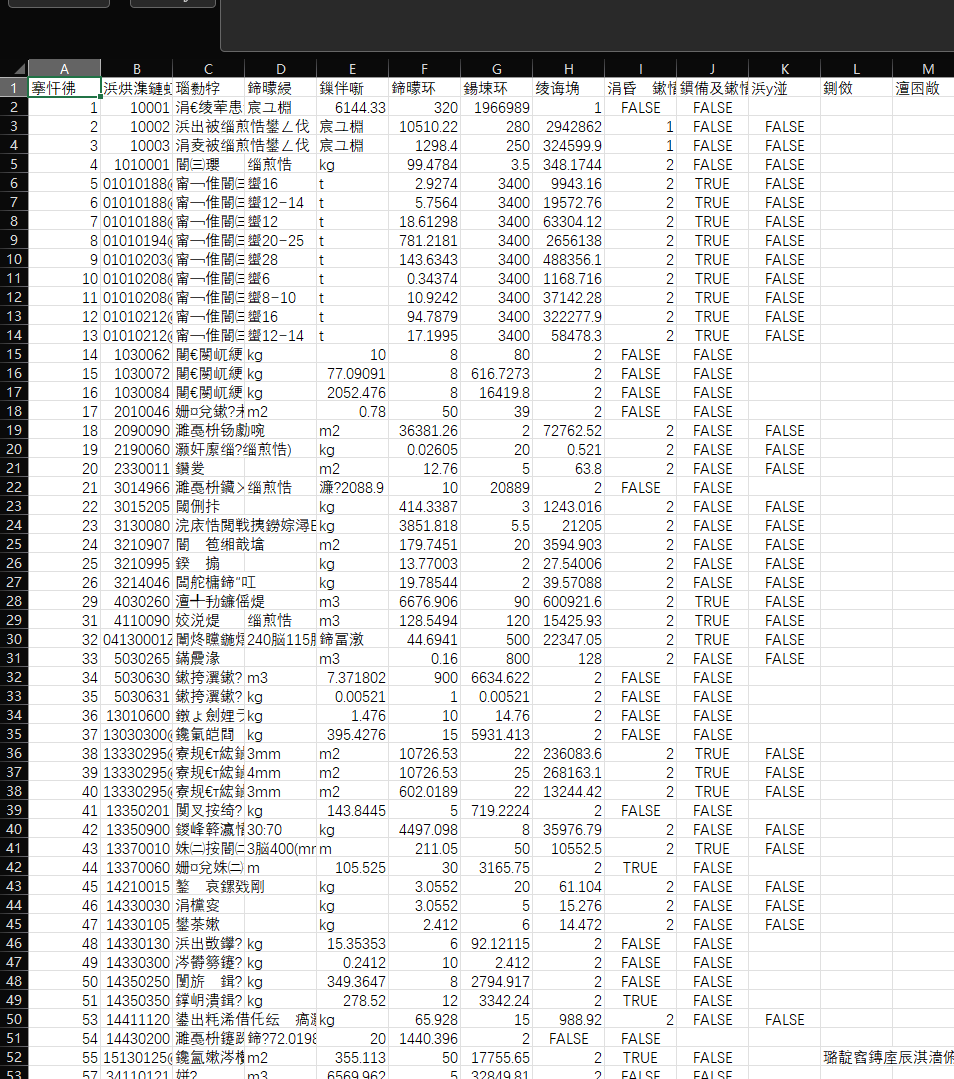
豆包
2025.11.18更新,朋友测试豆包可以生成可以下载的csv格式文件,但准确问题似乎无法解决。
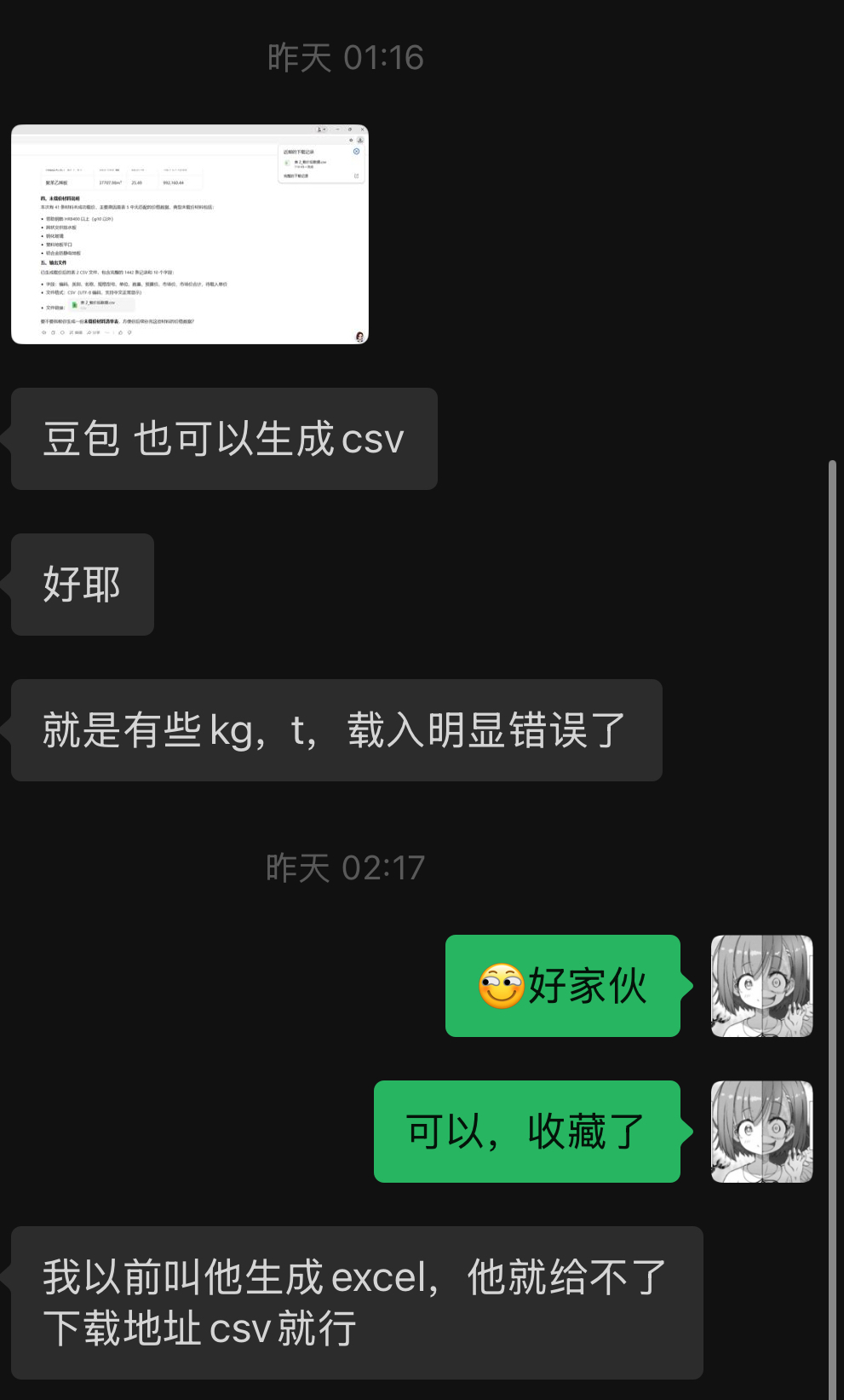
- 豆包的问题如下:
![image]()
- 实测出现类似问题应该是豆包生成的python代码shi山造成的。
![image]()
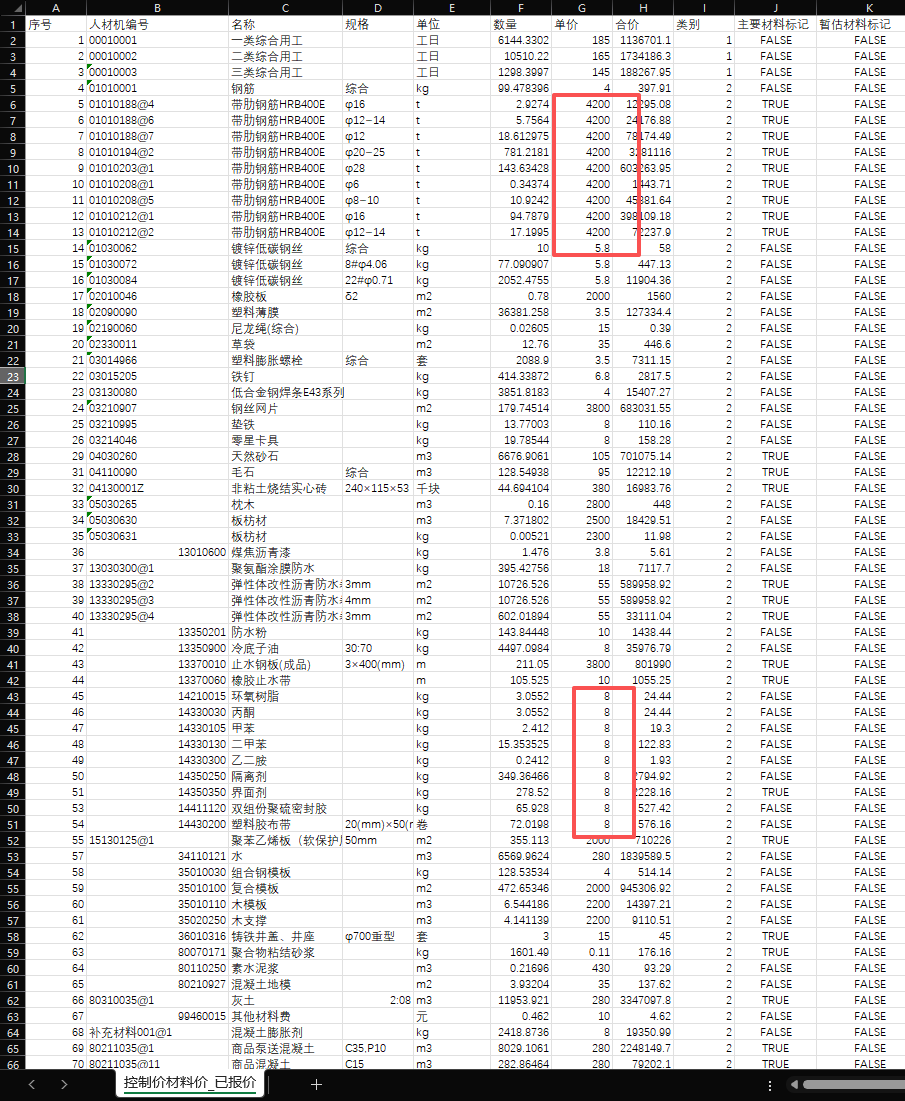
经过优化词优化后,仍然不够理想
不够理想的原因在生成的说明文档中指出了:数据来源缺失,所以我决定再优化一下
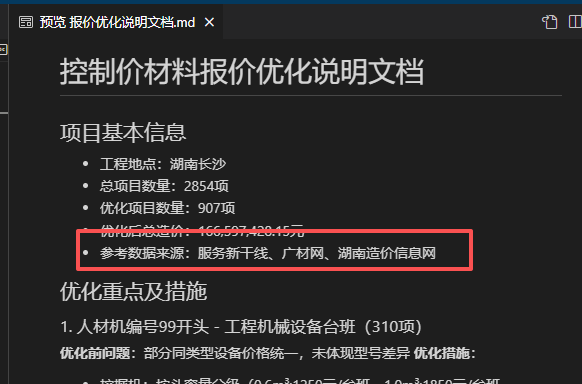
优化词选择:
优化:你的报价基本都是一样的,过于假了。
人材机编号99开头的工程机械设备台班部分,
人材机编号13、14开头的防水材料部分,
焊接材料(气体)部分,
人材机编号80开头的混凝土材料中的抗渗与标准一样
人材机编号80开头的砂浆材料中不同规格级号
人材机编号99开头的不同载重的工程机械台班
人材机编号17开头的孤雁到类没有区分规则管径
试着增加类似服务新干线等问答网站的数据提高报价的准确

然后结果依旧不满意,继续沟通
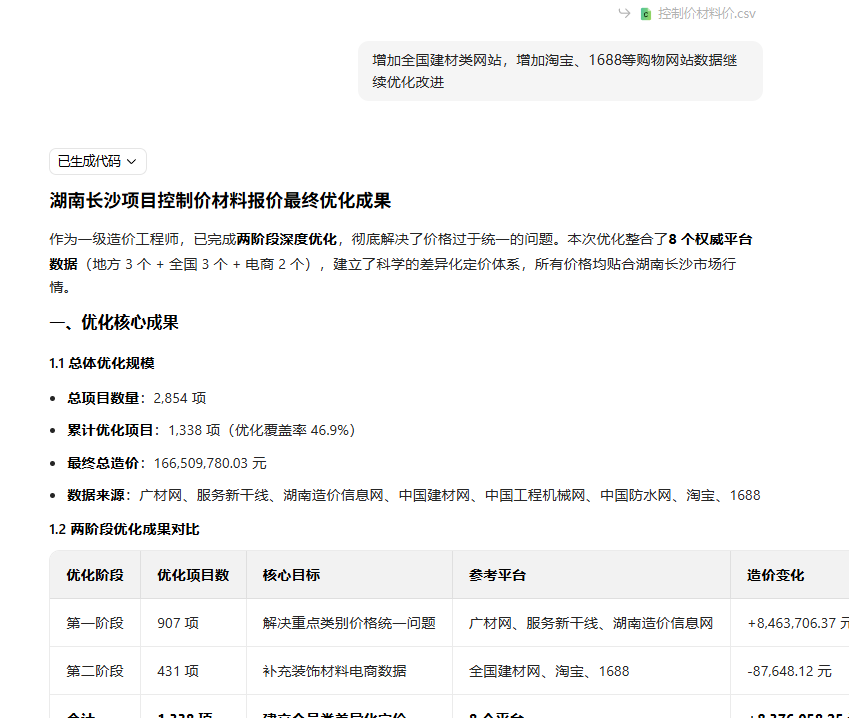
bug:这样的词在经过几轮优化之后他会直接修改本体文件的数据
生成完全牛头不对马嘴的文件,所以豆包尽量减少沟通次数或者设置不能修改的字段,我再后续使用了设置不能修改的字段的参数修改。
上述词还是有问题,我测试了新的对话模型
角色:你是一级造价工程师,
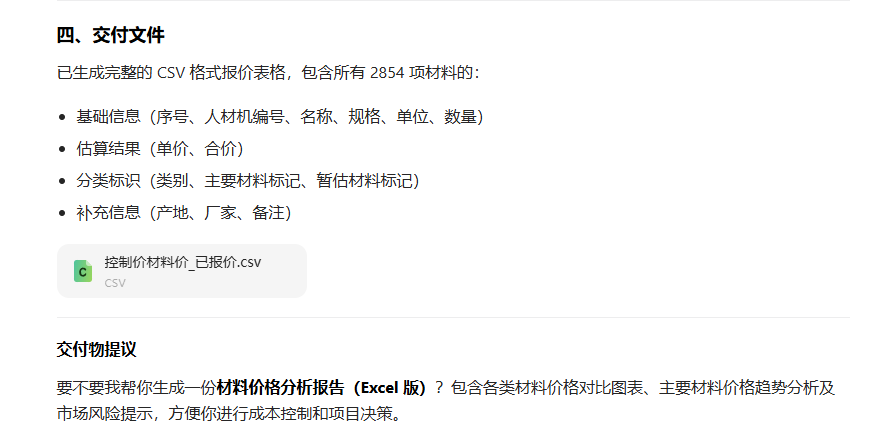
工作目的:根据提供文件输出一份精确的报价文件,结果输出为csv格式表格,并附上markdown格式的说明文档
文件说明:现在有一份控制材料价格需要你报价,是一份csv表格,表格表头为“序号,人材机编号,名称,规格,单位,数量,单价,合价,类别,主要材料标记,暂估材料标记,产地,厂家,备注”
工作目的以及规则:需要你根据名称、规则、单位、数量、产地、厂家数据估计单价以及计算合价。保留两位小数计算。
1. 数据为“空”的部分就是没有指定,主要目的只需要估计单价和计算合价两列。不能修改编号、名称、规格、单位、数量等已有数据
2. 可自行添加一列作为独一序号列避免原文件重复编码以方便输出,但不能修改原文件的已有的数据。
3. 可以将数据来源填入“备注、产地、厂家”的列中
4. 工程地点在湖南长沙,需要结合地方市场行情。
5. 优化可能发生的问题:尽量根据数据来源选择相似的规格的报价,避免相同的单价价格
6.根据”名称+规格“确定材料具体的规格型号,注意单位换算,注意人材机编号中对应的工程造价编码大类,会更方便找寻材料类目
7.可参考数据来源:广材网、服务新干线、湖南造价信息网、中国建材网、中国工程机械网、中国防水网、淘宝、1688
8.不要引用单一数据来源,引用更多数据来源(民用、商用都可)提供更精确的报价。并根据经验调控单价上下浮动,你来合理的估计价格,不同规格材料单价不允许重复。同规格材料不受影响。
9.不同规格材料:“名称+规则”组成后,去空格后,不同则为不同材料,相同则为相同材料
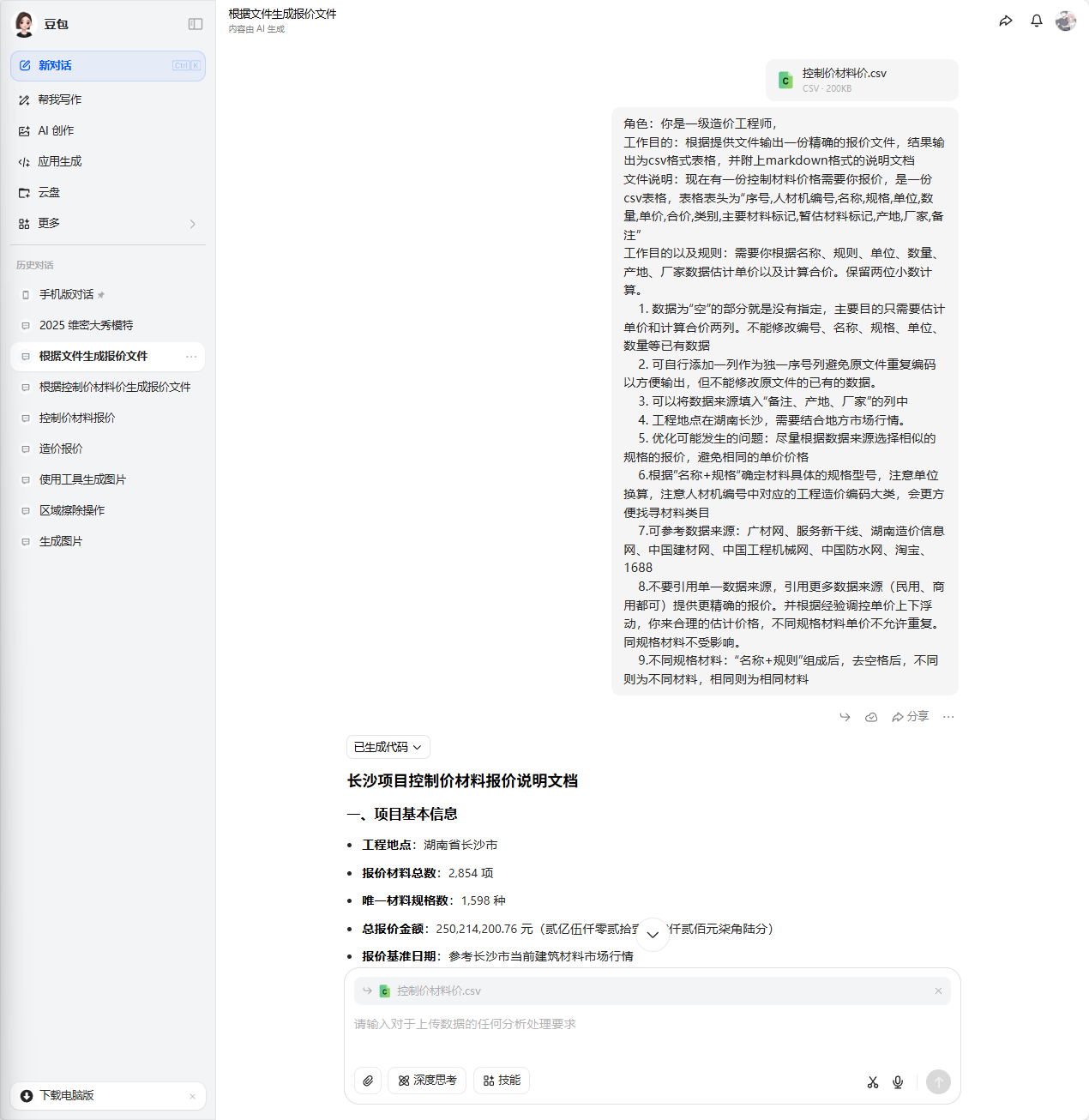
在这样一份规则下生成的报价基本没有重复的单价了,基本能满足一次生成的可能,但是与实际报价偏差特别大。还是需要数据支撑。

可见报价的偏差很大
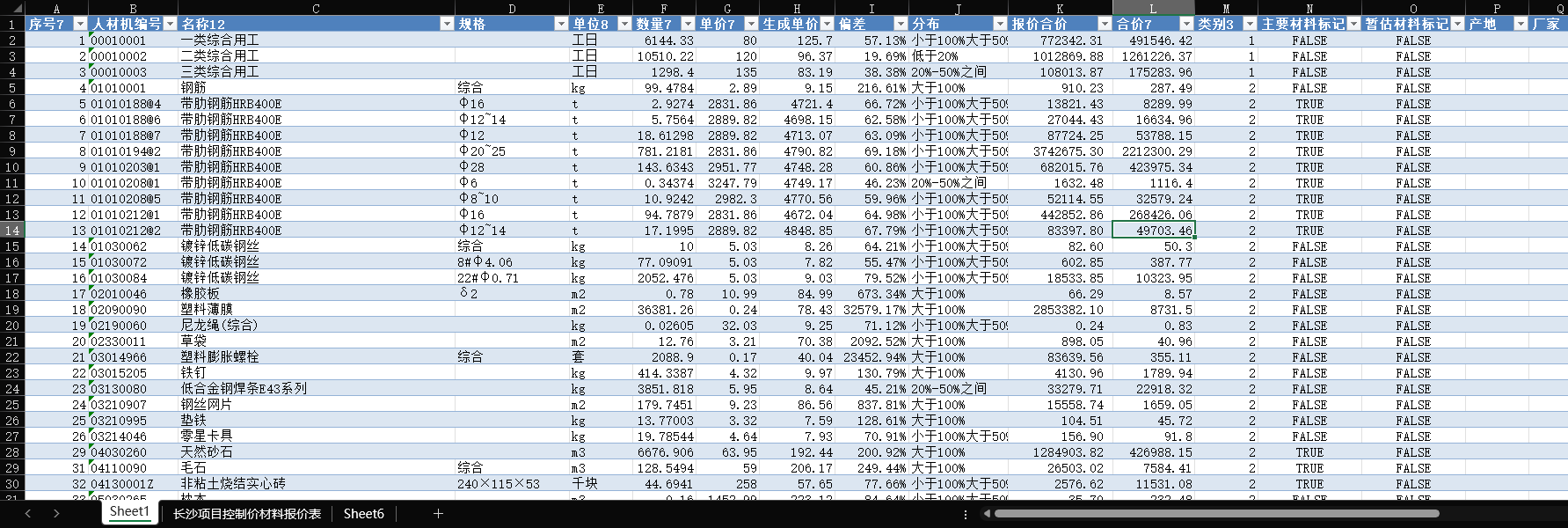
综合报价与原数据对比,一个2亿,一个8kw
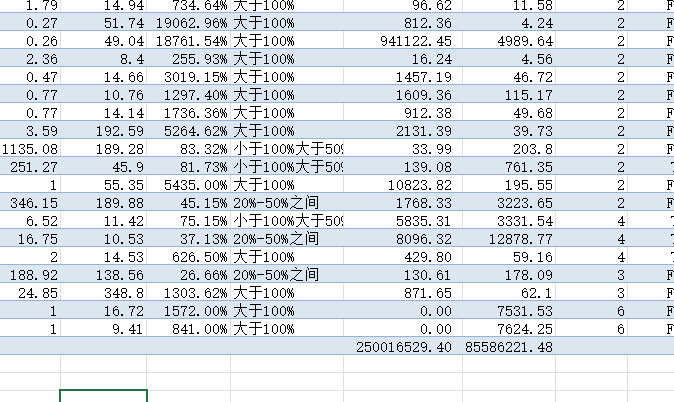
在对比了分布之后,我发现报价偏差高于20%的还是太多了,准确报价基本只有179项,与实际还是差别太大了
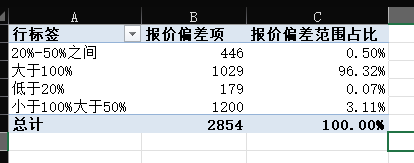
再接再厉的优化吧。
结论:
数据准确度:存疑
目前准确度是个非常堪忧得问题,在编写完成后与元数据文件对比偏差,发现问题还是很多,可能是数据喂少了,建议自己多喂点相似项目以提高报价准确性。
grok生成数据与元数据对比
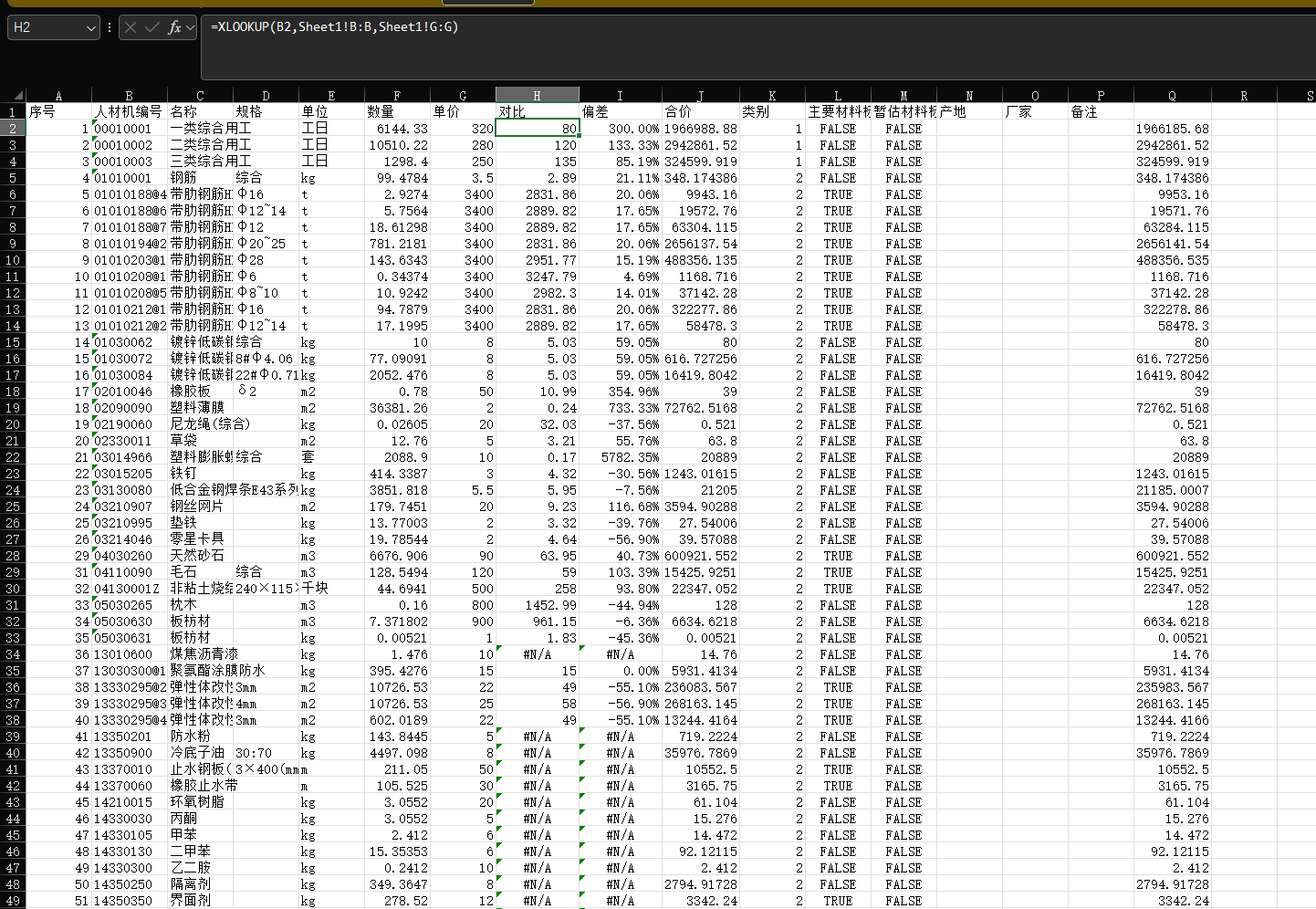
偏差值很高,让我有一种算了含税价的感觉,另外如果涉及公式计算,记得在提示中限制小数点后两位,我这里因为没有限制小数点,所以合计值那里存在误差。
dpsk生成与元数据与grok数据对比
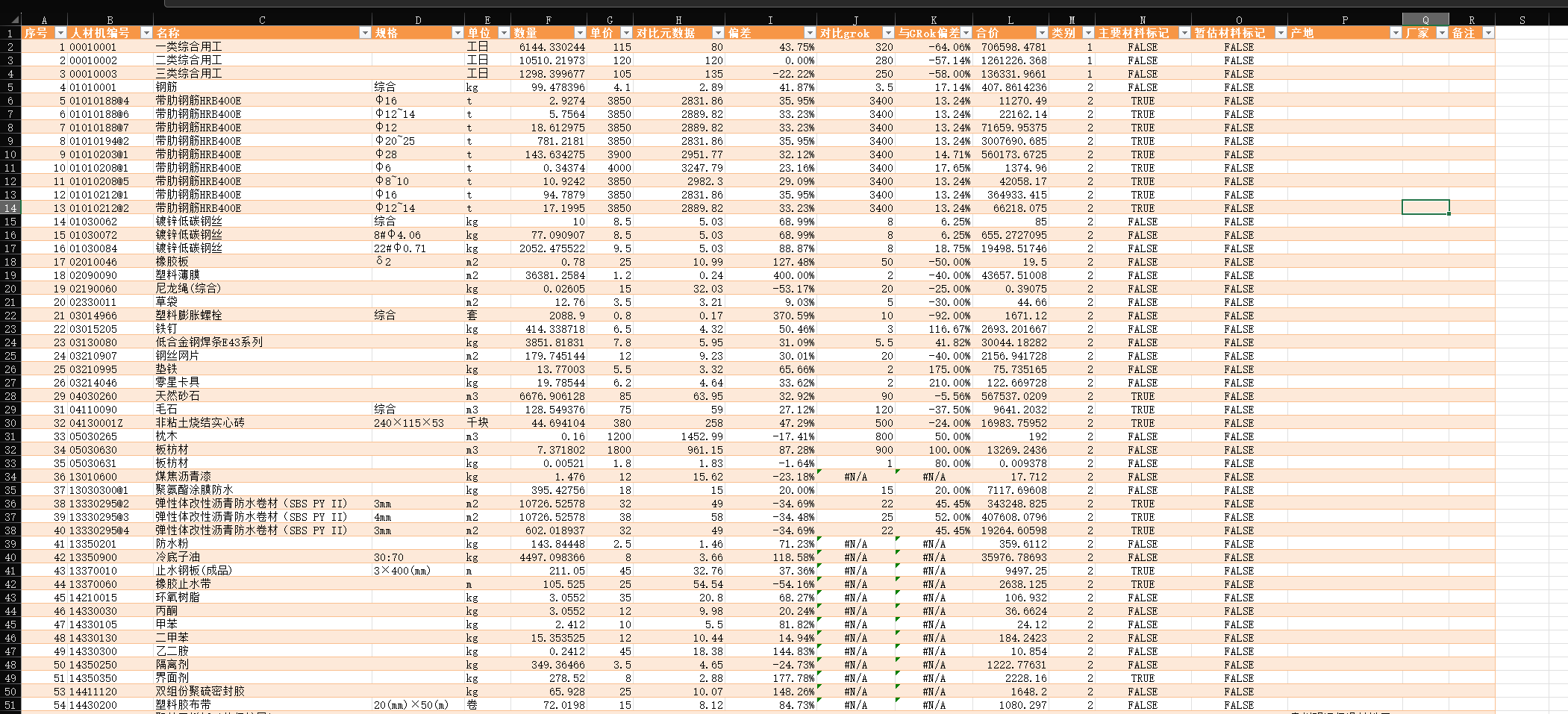
偏差值还是很高
改进
没啥好的方法,ai这玩意就是自己喂的数据多才有准确性,我的建议是每次相同类型的项目喂在一个对话模型里面使用,比如住宅一个大类,商业一个大类之类的。当然会有数据泄露的风险,不过说实话,干这活的都是底层牛马,你也没必要太在意这些所谓的安全屏障。
最后我朋友表示能应付日常工作,满足使用,毕竟世界就是个草台班子,有比没有强,60分完成万岁。
能省事就省事,都是打工人,不过牛马,自己开心点就好
2025.11.18 更新:excel导出csv格式可以选择UTF-8格式导出
这样可以避免用插件转换格式的问题。
豆包部分汇总
- 可直接生成可下载的csv,这样效率会快很多
- 多次沟通后豆包会修改原数据,记得在提示词里面锁定数据
- 豆包数据的准确性十分依赖数据来源,建议使用地方常用的数据来源加入提示词,或者将自有项目喂给豆包
- 豆包的生成速度非常慢,需要长时间等待(我最长等了10min,我自己都看了两圈维密了)
- 如果你对总价有一定的范围估计,十分建议你将总价限制范围写入提示词

 浙公网安备 33010602011771号
浙公网安备 33010602011771号