JVM之基础概念(运行时数据区域、TLAB、逃逸分析、分层编译)
运行时数据区域
- JDK8 之前的内存布局
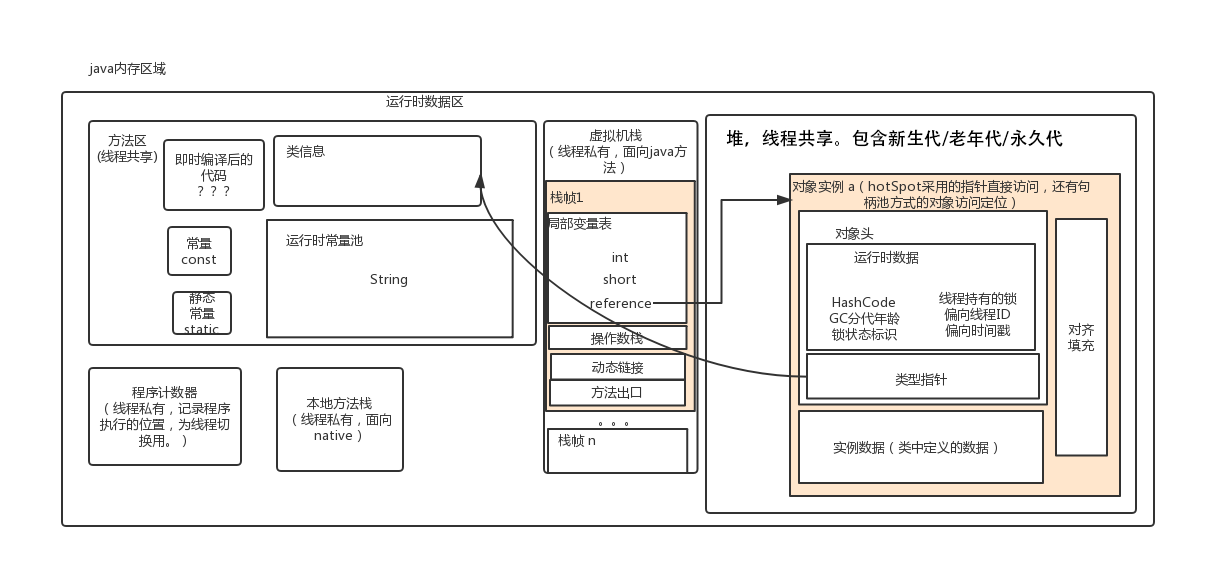
- JDK8 之后的 JVM 内存布局
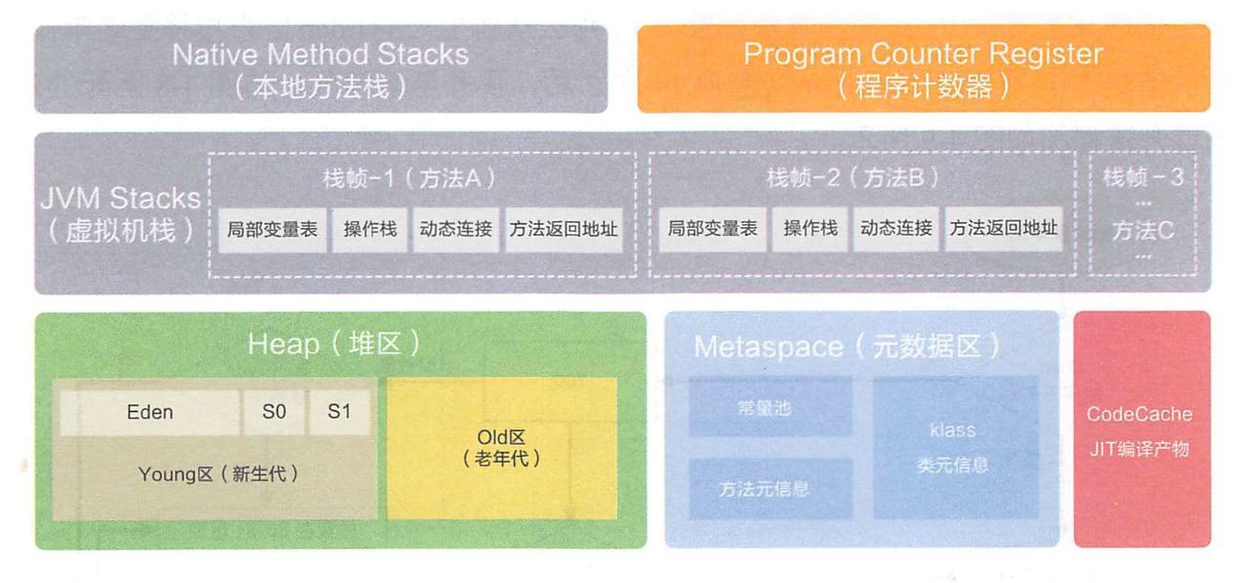
JDK8 之前,Hotspot 中方法区的实现是永久代(Perm),JDK8 开始使用元空间(Metaspace),以前永久代中字符串常量、类静态变量移至堆内存,其他内容移至元空间,元空间直接在本地内存分配。
-
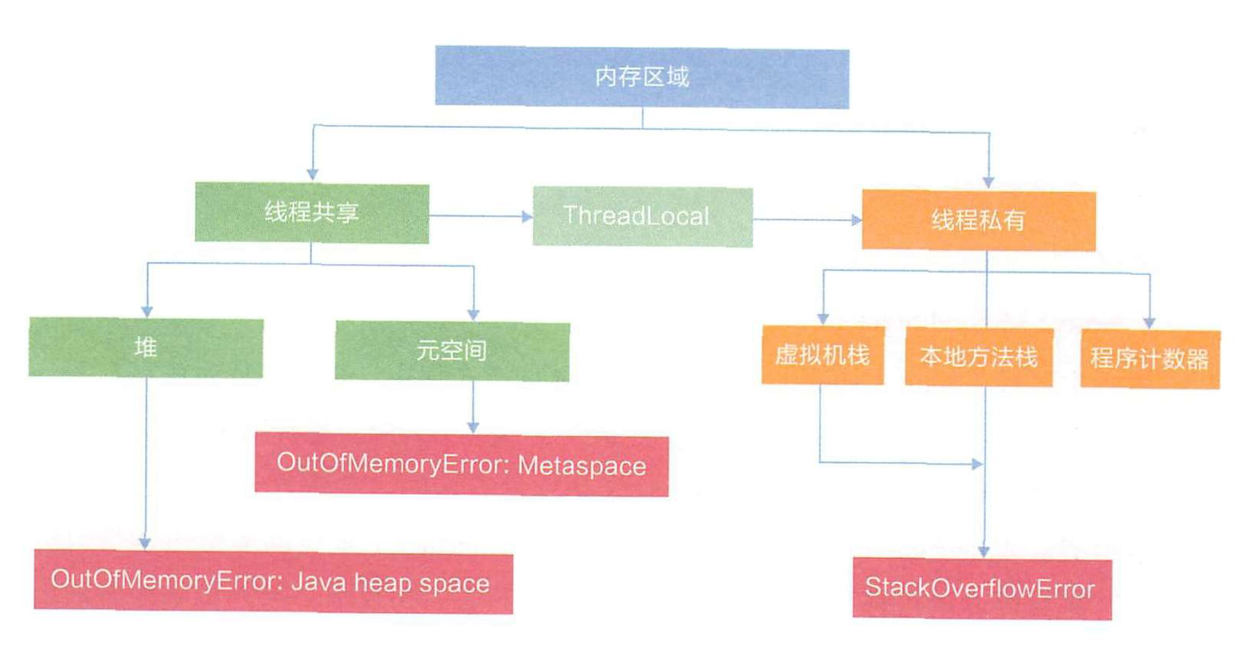
内存溢出
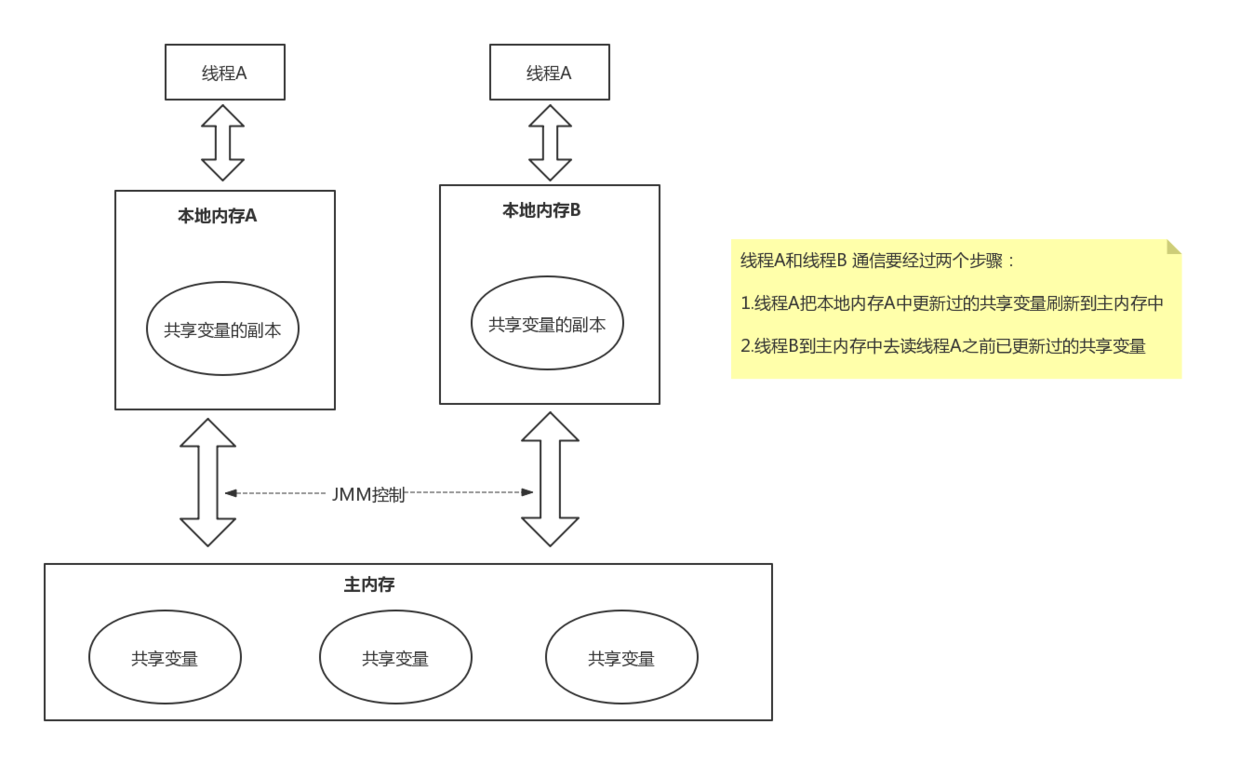
内存模型
TLAB
TLAB的全称是Thread Local Allocation Buffer,即线程本地分配缓存区,这是一个线程专用的内存分配区域。其本质还是Eden区域,只是从Eden区申请了一块私有区域,用三个指针进行管理:start、top 、end,其中 start 和 end 标识起始位置,top指目前已经使用到的位置,最大值为end。
可以把TLAB理解为一种Eden区域的空间分配策略,线程预先申请空间,后续的空间分配如果在自己独有的空间上进行,不存在竞争,可以大大提高分配效率。当然,线程申请独有空间还是存在竞争关系的,虚拟机采用CAS+失败重试保证操作的原子性。
那么,什么情况下才会在TLAB上直接分配?
先了解下JVM相关参数:
-
-XX:+UseTLAB:启用TLAB,默认开启
-
-XX:+TLABSize: 设置TLAB大小,JVM会在运行时不断调整,不建议手动设置
-
-XX:TLABRefillWasteFraction:TLAB允许浪费空间的比例,默认为64,refill_waste的默认值,运行时会不断调整
-
-XX:ResizeTLAB:自动调整TLABRefillWasteFraction阈值,默认开启
-
-XX:TLABWasteTargetPercent:设置TLAB空间所占用Eden空间的百分比大小,默认是1%
-
XX:+PrintTLAB:查看TLAB信息
分配规则:
- obj_size + tlab_top <= tlab_end:直接在TLAB空间分配对象
- obj_size + tlab_top > tlab_end
- tlab_free > tlab_refill_waste_limit:tlab剩余可用空间>tlab可浪费空间,当前线程不能丢弃当前TLAB,本次申请交由Eden区分配空间,下次遇到满足条件的小对象接着用
- tlab_free:剩余的内存空间,即tlab_end - tlab_top
- tlab_refill_waste_limit:允许浪费的内存空间,由-XX:TLABRefillWasteFraction决定,默认TLAB的1/64,运行时会不断调整
- tlab_free <= _refill_waste_limit:重新分配一块TLAB空间,在新的TLAB中分配对象,原TLAB就交给Eden管理
- tlab_free > tlab_refill_waste_limit:tlab剩余可用空间>tlab可浪费空间,当前线程不能丢弃当前TLAB,本次申请交由Eden区分配空间,下次遇到满足条件的小对象接着用
逃逸分析
public class EscapeAnalysis {
public static Object object;
public Object methodEscape1() { // 方法逃逸:方法返回值逃逸
return new Object();
}
public Object methodEscape2() { // 方法逃逸:作为参数传递到其它方法中
Object object=new Object();
xxx(object)
}
public void threadEscape1() {// 线程逃逸:赋值给类变量
object = new Object();
}
public void threadEscape2() { // 线程逃逸:其他线程中访问的实例变量
Object obj=new Object();
new Thread(() -> xxx(obj)).start();
}
public void eliminate1() { // o未逃逸,可自动清除锁
Object o=new Object();
synchronized (o){
xxx();
}
}
public void eliminate2() { // buffer未逃逸,append操作加锁可自动清除锁
StringBuffer buffer=new StringBuffer();
buffer.append("hello");
buffer.append("world");
buffer.append("!");
}
/**
* foo未逃逸,可通过标量替换进行优化
*/
publicint bar(int x) {
Foo foo = new Foo();
foo.a = x;
return foo.a;
// 优化后代码
int a = x;
return a;
}
}
- 逃逸分析缺点:不能保证逃逸分析的性能收益必定高于它的消耗
- 逃逸分析作用:
- 锁消除:-XX:+EliminateLocks开启(JDK8默认开启),-XX:-EliminateLocks关闭
- 标量替换:把不存在逃逸的对象拆散,将成员变量恢复到基本类型,直接在栈上创建若干个成员变量。分层编译()和逃逸分析在1.8中是默认是开启。参数:-XX:+EliminateAllocations
- 栈上分配:目前Hotspot并没有实现真正意义上的栈上分配,实际上是标量替换。栈上分配随着方法结束而自动销毁,垃圾回收压力减小
- XX:+DoExcapeAnalysis:开启逃逸分析,默认开启,可通过-XX:-DoEscapeAnalysis关闭
- XX:PrintEscapeAnalysis:查看分析结果
分层编译
从 Java 7 开始,HotSpot 默认采用分层编译的方式:系统执行初期热点方法优先使用C1编译器,以便尽快进入编译执行。随着时间推移,执行频率较高的代码再被C2编译器编译,以达到最佳性能。
C1、C2都是即时编译器,会将其中反复执行的热点代码,以方法为单位进行即时编译,翻译成机器码后直接运行在底层硬件之上。C2编译器需要收集大量统计信息用于编译优化,相对C1比较耗时,但运行效果更好。
热点方法是由JVM统计每个方法被调用的次数,超过多少次,就是热点方法。默认的分层编译应该是达到两千调C1,达到一万五调C2。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号